MySQL 主从复制是指数据可以从一个 MySQL 数据库服务器主节点复制到一个或多个从节点。MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
通过数据复制,可以实现:
- 负载均衡:可以将读操作分布到不同的节点上面,避免单个节点服务瓶颈,水平扩展数据库的负载能力。
- 读写分离:业务的写操作都在主库上,主库因为异常写入导致不可用,其他节点可以继续提供读服务
- 高可用和故障切换:避免单点故障,Master宕机时Slave可以马上切换上去,保证业务可用性
原理
MySQL通过Binlog(逻辑复制)搭建主从集群,实现数据复制。
| RedoLog | Binlog | |
|---|---|---|
| 特性能力 | Redo 初衷是用于性能提升和崩溃恢复 | Binlog 适用于主从复制和数据恢复 是记录数据行更改的逻辑复制 |
| 实现方式 | Redo 是 InnoDB 引擎层实现的,并不是所有引擎都有 | Binlog 是 Server 层实现的,有统一的格式,所有引擎都可以使用 Binlog 日志 |
| 记录方式 | Redo 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志 | Binlog 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上 |
| 记录内容 | 具体到某个page的某个字节的修改,不可读,只能innodb解析 | 记录了行级别的更改,可以通过解析Binlog,转换成DML语句来将数据变更同步到异构数据库 |
| 副本类型 | 每个RedoLog同步的节点,与主节点共享一份数据 | 每个Binlog副本都需要一份全量的数据存储 |
| 复制延迟 | 稳定的日志落盘+读取的开销,日志支持并行回放,性能更好 一般在10-20ms左右 | 只有主库事务提交后,日志才会写入到Binlog文件并传递到备库,这意味着备库至少延迟一个事务的执行时间。 一般在100ms左右 遇到ddl或者大事务,容易造成极大的延迟 |
| 数据一致性 | 共享同一份数据,完全一致 | 不同的数据副本,部分极端情况下可能造成数据不一致,比如 - 主库故障后,强切到从库 |
| 清理方式 | checkpoint 前的 Redo 可以清理 | 线上一般保留 7天的 Binlog |
不管是 delete、update、insert、还是创建函数、存储过程,所有的操作都在 master 上。当 master 有操作的时候,slave 会快速的接收到这些操作,从而做同步。
- 在 master 机器上,主从同步事件会被写到 binlog
- 在 slave 机器上,slave 读取主从同步事件,并根据读取的事件变化,在 slave 库上做相应的更改。
MySQL Binlog 数据复制架构
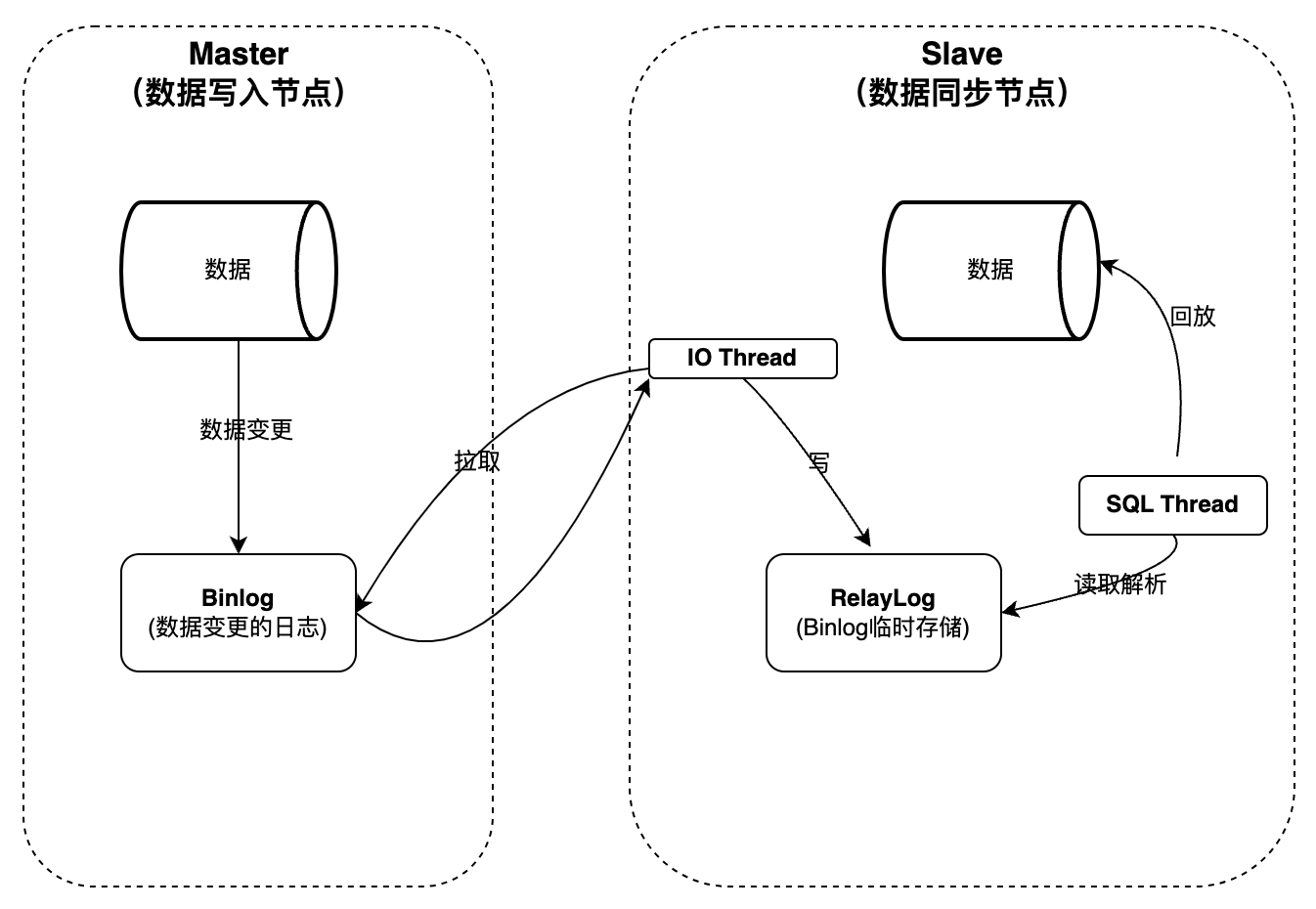
在 master 机器上,主从同步事件会被写到 binlog。 主从同步事件有 3 种形式: statement、row、mixed:
- statement:会将对数据库操作的 SQL 语句写入到 binlog 中。
- row:会将每一条数据的变化写入到 binlog 中。
- mixed:statement 与 row 的混合。MySQL 决定什么时候写 statement 格式的,什么时候写 row 格式的 binlog。
当 master 上的数据发生改变的时候,该事件(insert、update、delete)变化会按照顺序写入到binlog中。
主备流程
Master节点数据写入成功之后,生成数据变更的日志Binlog,Slave节点有IO Thread跟master节点建立链接,实时监听Binlog文件,读取Binlog文件的写入内容,再写入Slave节点本地的中继日志RelayLog。以上完成了数据变更日志从master复制到Slave节点的过程,但数据并未真正写入到Slave节点数据表。
Slave节点的SQL Thread监听Relay log文件写入,读取Relay log解析成SQL事务回放到数据表(相当于重新执行一遍数据变更的操作),完成数据复制的整个过程。
基本Binlog复制的特点:
- 主从数据延迟
从上述流程可发现,Binlog日志需要经过多个步骤最终才在slave回放完成数据的复制过程,整个过程就天然存在一定的时间差(日志网络传输耗时+日志回放耗时),在正常情况下主从的数据延迟时间在100ms以内。在一些写后即读的场景下,读取从库可能会读取不到最新的数据,有类似业务场景的建议是读主库。
- 主从数据一致性
一个方面,Slave节点的数据存在一定的延迟,如果Master节点宕机发生切主,Slave节点升主成为新的Master节点,会有丢失最新写入数的可能性。 另外一方面,Binlog其实是数据变更的日志,也就是常见的逻辑日志回放方式,存在一些特定的场景造成Slave节点的数据回放日志之后跟Master节点不一致。MySQL为了解决回放日志的延迟,引入的并行复制,即多线程去回放日志,并行回放就打破了日志顺序,增加了复杂度的同时也增加了数据不一致的风险。
异步复制和半同步复制
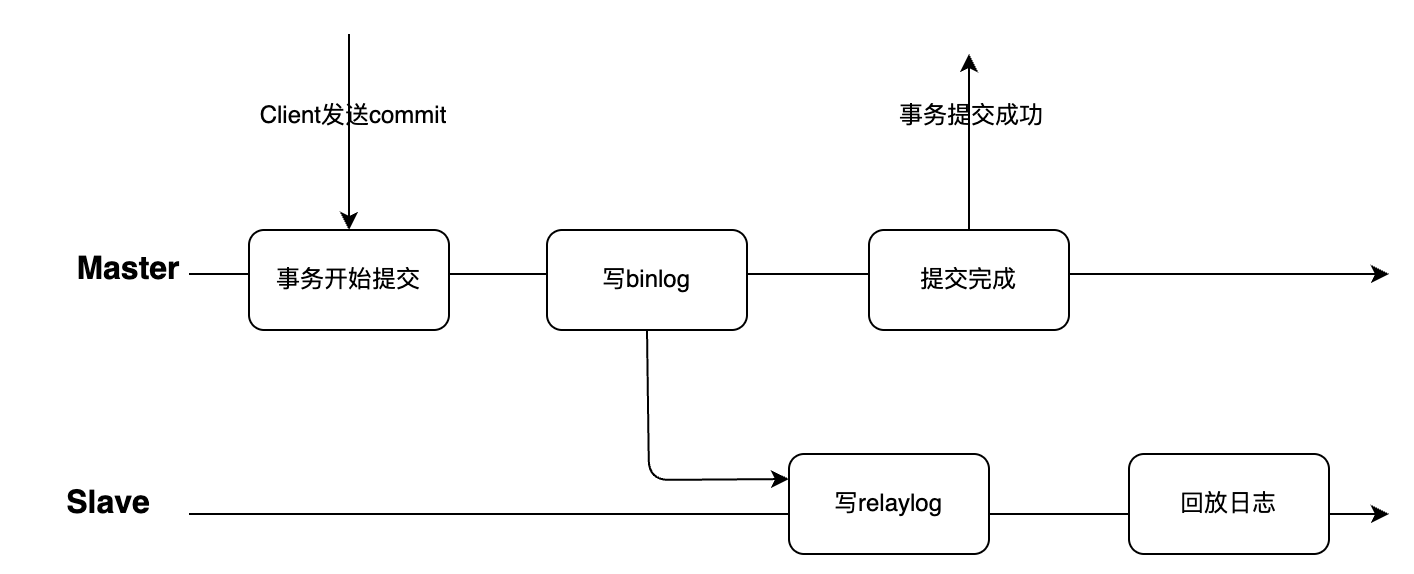
上述的复制流程也称为异步复制,简单理解就是Master节点写入不感知Slave节点是否接收到binlog就给客户端返回事务提交成功,对于客户端来说可能数据库返回事务提交成功,但是日志并没有传输到Slave,所以会存在数据延迟和故障切换数据一致性的问题。
为此,MySQL引入了半同步复制的模式,Master节点写入的binlog必须等待Slave节点确认接收到之后才给客户端返回事务提交成功。在这种机制下,如果Master节点宕机发生了切主,起码可以保证的是客户端明确收到提交成功的事务一定是有日志传输到了Slave,切主就不会造成数据的丢失。
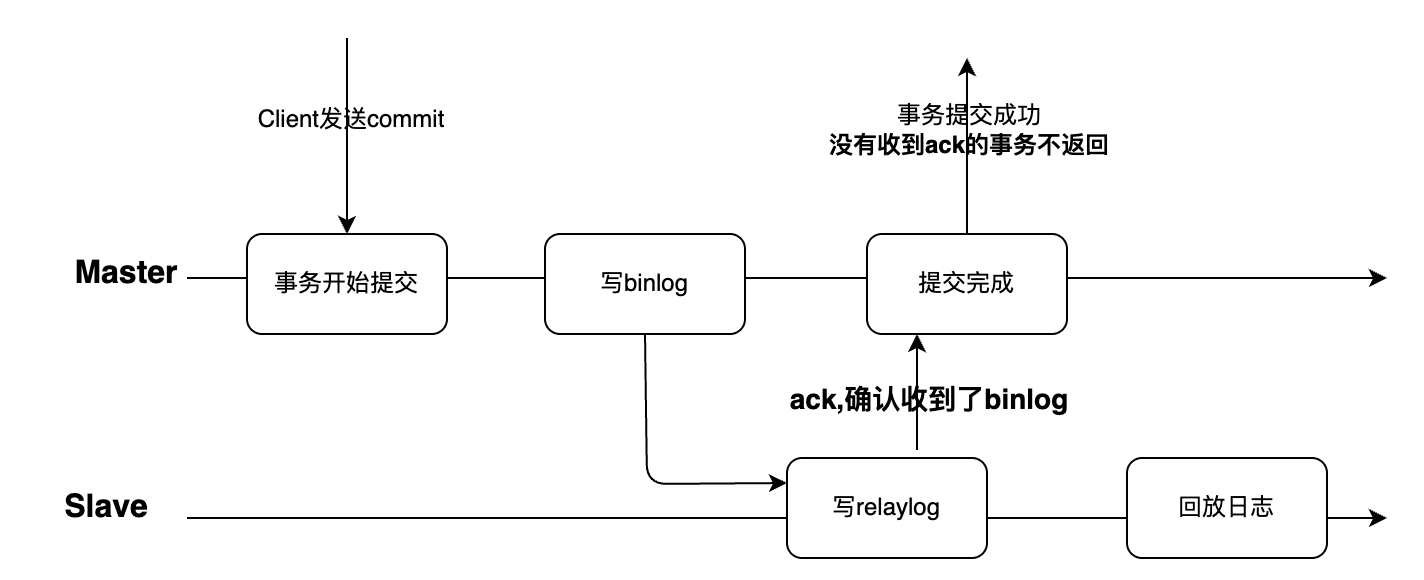
但是半同步复制是不解决延迟的问题的,因为大多数情况下Slave的数据延迟是在回放binlog的阶段,半同步并不等待Slave节点回放日志完成。如果说在Slave节点回放日志延迟比较大情况下发生Master节点宕机,需要切主,是不是也会造成数据丢失?这就是下面主备切换部分回答的问题。
高可用主备切换
MySQL本身是不提供高可用能力的,绝大部分的RDS服务都是在MySQL主从架构的基础上再加一个HA高可用的组件来进行主备切换操作。HA的组件也比较多,整体的RDS架构也有些许区别,但大同小异。以我字节为例,以下是RDS服务整体的架构,了解清楚基本架构有助于理解HA高可用切换的流程。
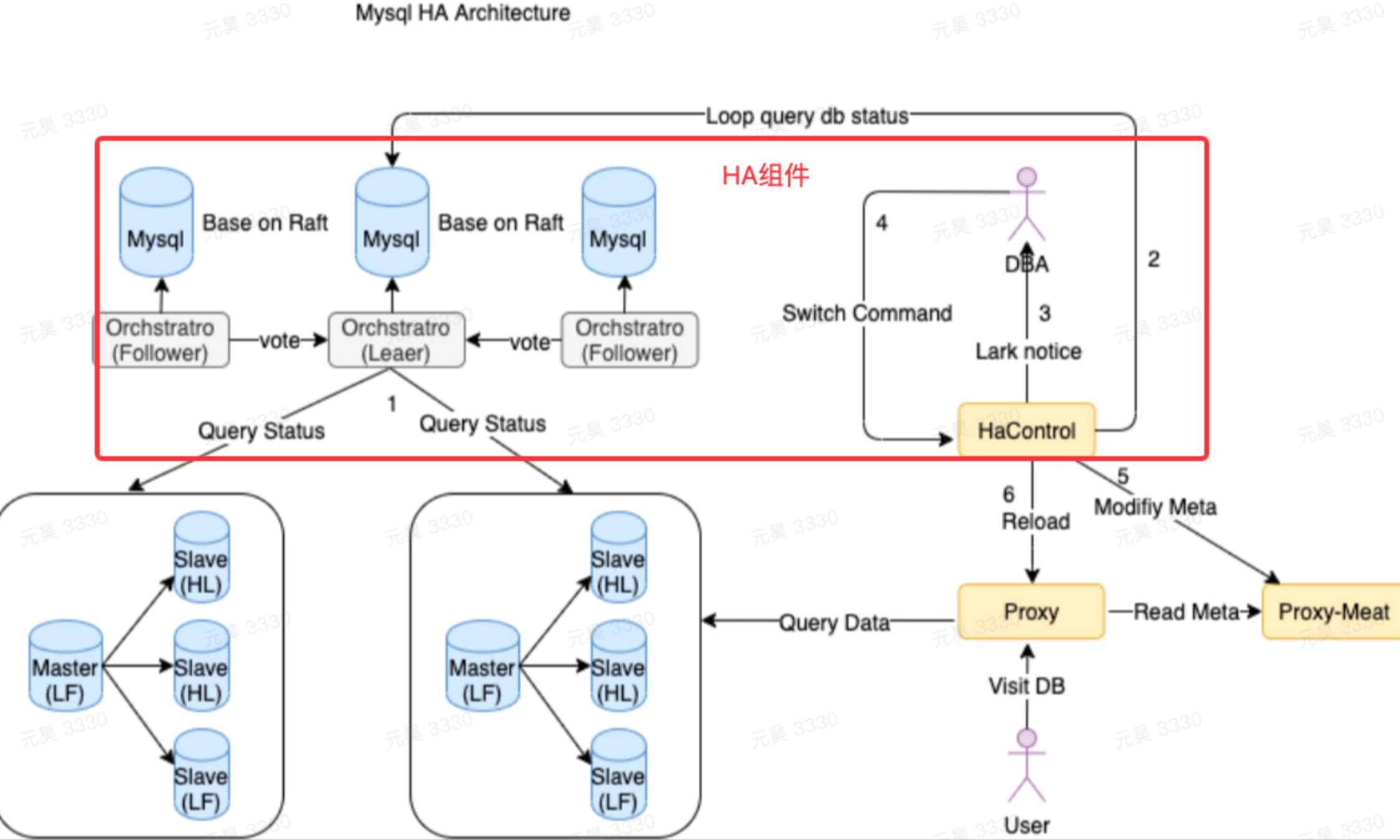
对于主备切换的流程,HA循环检测Master实例的健康状态,发现实例故障实例故障,触发主备切换的操作,完整流程如下:

流程中候选主库的步骤是是否丢数据的关键,如果选的新主机是有数据延迟的,就可能会丢数据。所以选新主的时候HA会从两个方面尽量减少数据丢失:一是选择数据最新的实例作为新的主;二是 检查新的主回放binlog是否完成,如果没有完成会等一定时间。
所以回答上一个章节的问题:半同步下如果Slave节点回放日志延迟比较大,主备切换会不会丢数据?答案是肯定的,HA在切换选主过程中虽然会检查并等待回放日志完成,但是不会一直等下去,过了等待时间还没有回放完升主了就可能丢失数据。
总结下MySQL Binlog复制的特点:优点是简单灵活,可扩展性强,另外很多下游的也能获取binlog来获取数据变更,是跨存储组件数据同步的不二选择;缺点是在主从数据延迟,数据一致性上比较难保障,在业务使用的过程中需要特别关注的点;那么下面介绍的基于RedoLog的复制架构就能够很好解决数据延迟跟数据一致性的问题。