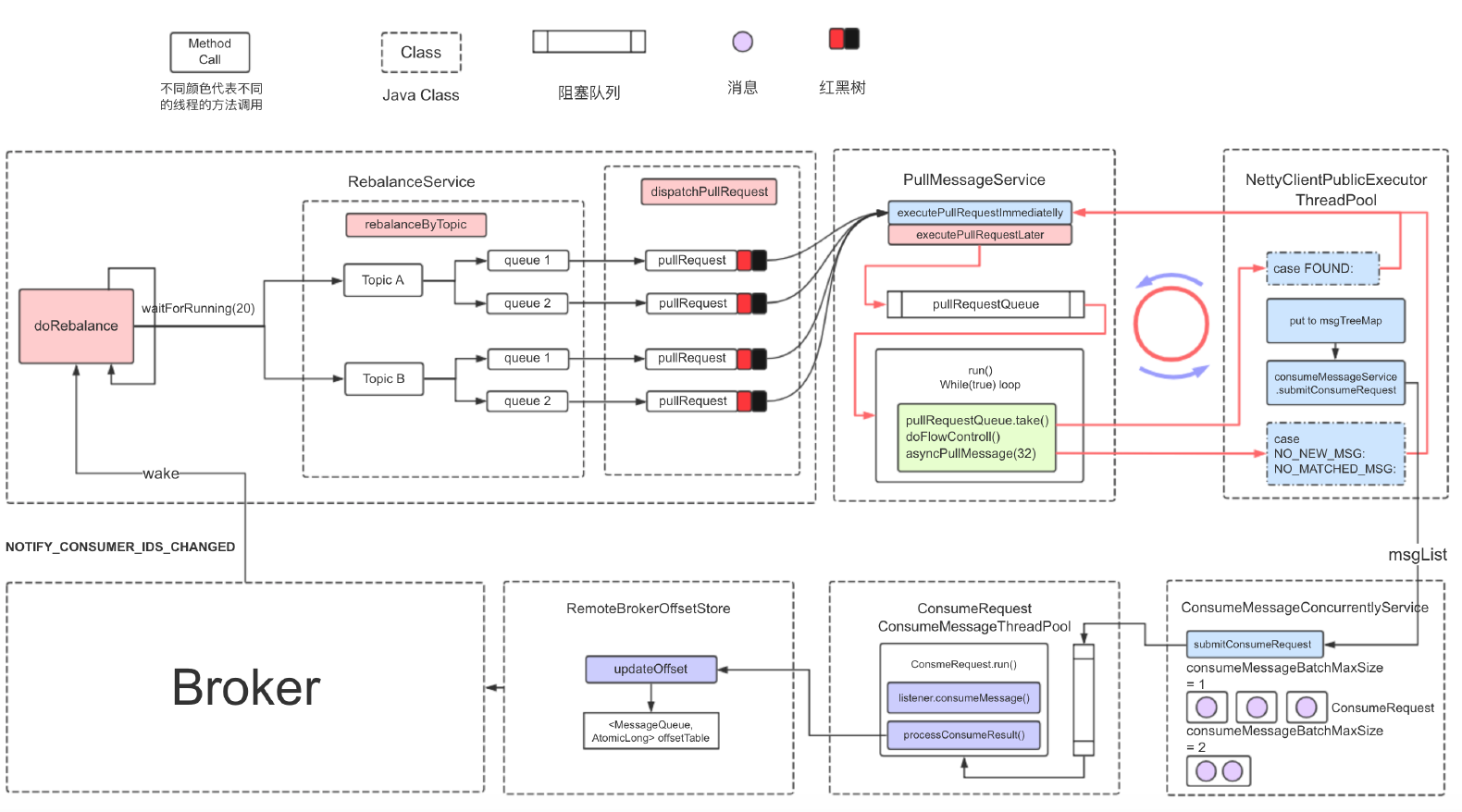
相关概念
tag 标签
标签,即子主题,为用户提供了额外的灵活性。有了标签,来自同一业务模块的具有不同目的的消息可以具有相同的主题和不同的标签。标签有助于保持代码的清晰和连贯,同时标签也方便 RocketMQ 提供的查询功能。 在 producer 中使用 tag:
1
2
3
Message msg = new Message("TopicTest",
"TagA" /* Tag */,
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
在 consumer 中订阅 tag:
1
consumer.subscribe("TopicTest", "TagA||TagB");// * 代表订阅Topic下的所有消息
group 组
代表具有相同角色的生产者组合或消费者组合,称为生产者组或消费者组。
key
设置业务相关标识,用于消费处理判定,或消息追踪查询。 尽管 broker 不会对消息进行 key 相关的过滤(并不属于服务端消息过滤的功能),但是会为消息定制相应的索引,提供了一种较精确的查询指定消息的功能。 在发送消息之前可以为消息设定指定的 key,通常这个 key 是在业务层面是唯一的:
1
2
Message msg = new Message("Topic", "Tag", "Content".getBytes());
msg.setKey(uniqueKey);
commit log
文件集合,每个文件 1G 大小,存储满后存下一个,所有消息内容全部持久化到这个文件中。
消息存储协议
commit log 文件存储的逻辑视图如下图所示,每条消息的前面 4 个字节存储该条消息的总长度。

所有的 topic 共享
消息存储格式如下
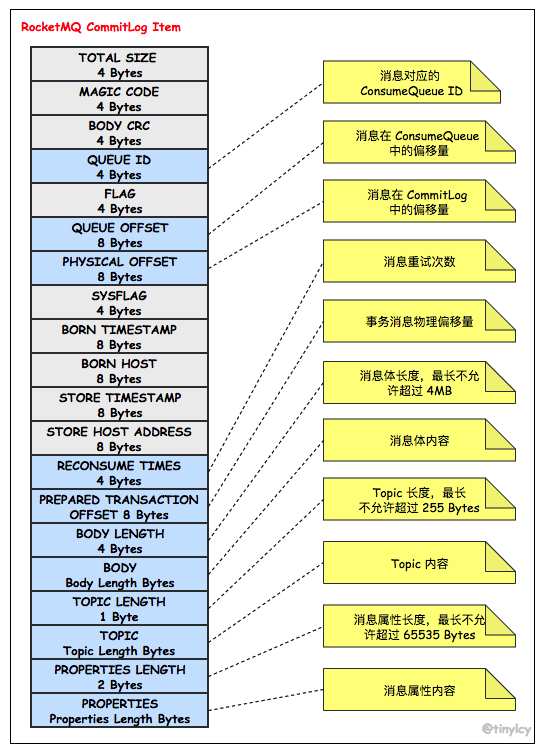 RocketMQ 以如下图所示存储格式将消息顺序写入 CommitLog。除了记录消息本身的属性(消息长度、消息体、Topic 长度、Topic、消息属性长度和消息属性),CommitLog 同时记录了消息所在消费队列的信息(消费队列 ID 和偏移量)。由于存储条目具备不定长的特性,当 CommitLog 剩余空间无法满足消息时,CommitLog 在尾部追加一个 MAGIC CODE 等于 BLANK_MAGIC_CODE 的存储条目作为结束标记,并将消息存储至下一个 CommitLog 文件。
RocketMQ 以如下图所示存储格式将消息顺序写入 CommitLog。除了记录消息本身的属性(消息长度、消息体、Topic 长度、Topic、消息属性长度和消息属性),CommitLog 同时记录了消息所在消费队列的信息(消费队列 ID 和偏移量)。由于存储条目具备不定长的特性,当 CommitLog 剩余空间无法满足消息时,CommitLog 在尾部追加一个 MAGIC CODE 等于 BLANK_MAGIC_CODE 的存储条目作为结束标记,并将消息存储至下一个 CommitLog 文件。
- TOTALSIZE:该消息条目总长度,4字节。
- MAGICCODE:魔数,4字节。固定值Oxdaa320a7。
- BODYCRC:消息体ere校验码, 4字节。
- QUEUEID:消息消费队列ID , 4 字节。
- FLAG:消息FLAG , RocketMQ 不做处理,供应用程序使用,默认4字节。
- QUEUEOFFSET :消息在消息消费队列的偏移量, 8 字节。
- PHYSICALOFFSET : 消息在CommitLog 文件中的偏移量, 8 字节。
- SYSFLAG : 消息系统Flag ,例如是否压缩、是否是事务消息等, 4 字节。
- BORNTIMESTAMP : 消息生产者调用消息发送API 的时间戳, 8 字节。
- BORNHOST :消息发送者IP 、端口号, 8 字节。
- STORETIMESTAMP: 消息存储时间戳, 8 字节。
- STOREHOSTADDRESS: Broker 服务器IP+ 端口号, 8 字节。
- RECONSUMETIMES: 消息重试次数, 4 字节。
- Prepared Transaction Offset: 事务消息物理偏移量, 8 字节。
- BodyLength: 消息体长度,4字节。
- Body: 消息体内容,长度为 bodyLenth 中存储的值。
- TopieLength: 主题存储长度,1字节,表示主题名称不能超过255 个字符。
- Topie: 主题,长度为 TopicLength 中存储的值
- PropertiesLength: 消息属性长度,2字节, 表示消息属性长度不能超过65536个 字符。
- Properties: 消息属性,长度为 PropertiesLength 中存储的值。
存储过程
- 在写入 commitlog 之前,先申请 Lock(putMessageLock),也就是将消息存储到 commit log 文件中是串行锁。
- 创建全局唯一消息ID,消息ID有16字节,消息ID的组成如下图:
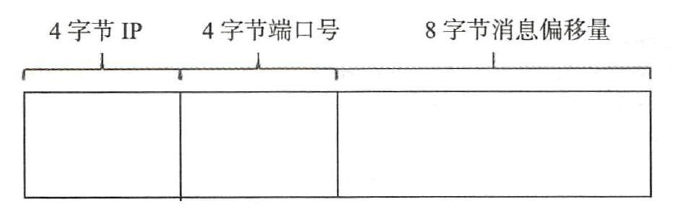 这样生成ID的好处:为了消息 ID 可读性,返回给应用程序的 msgld 为字符类型,可以通过 UtilAll.bytes2string 方法将 msgld 字节数组转换成字符串,通过Uti1All.string2bytes 方法将 msgld字符串还原成 16 个字节的字节数组,从而根据提取消息偏移量,可以快速通过 msgld 找到消息内容。
这样生成ID的好处:为了消息 ID 可读性,返回给应用程序的 msgld 为字符类型,可以通过 UtilAll.bytes2string 方法将 msgld 字节数组转换成字符串,通过Uti1All.string2bytes 方法将 msgld字符串还原成 16 个字节的字节数组,从而根据提取消息偏移量,可以快速通过 msgld 找到消息内容。 - 获取该消息在消息队列的偏移量。CommitLog 中保存了当前所有消息队列的当前待写入偏移量。
- 根据消息、体的长度、主题的长度、属性的长度结合消息存储格式计算消息的总长度。
commit queue
一个 topic可以有多个,每个文件代表一个逻辑队列,这里存放消息在 commit log 中的偏移量以及大小和 tag 属性。
RocketMQ 主要通过 MappedByteBuffer 对文件进行读写操作。其中,利用了 NIO 中的 FileChannel 模型直接将磁盘上的物理文件直接映射到用户态的内存地址中(这种 Mmap 的方式减少了传统 IO 将磁盘文件数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销),将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率(这里需要注意的是,采用 MappedByteBuffer这种内存映射的方式有几个限制,其中之一是一次只能映射 1.5~2G的文件至用户态的虚拟内存,这也是为何 RocketMQ 默认设置单个 CommitLog 日志数据文件为1G的原因了)。
刷盘
刷盘一般分成:同步刷盘和异步刷盘
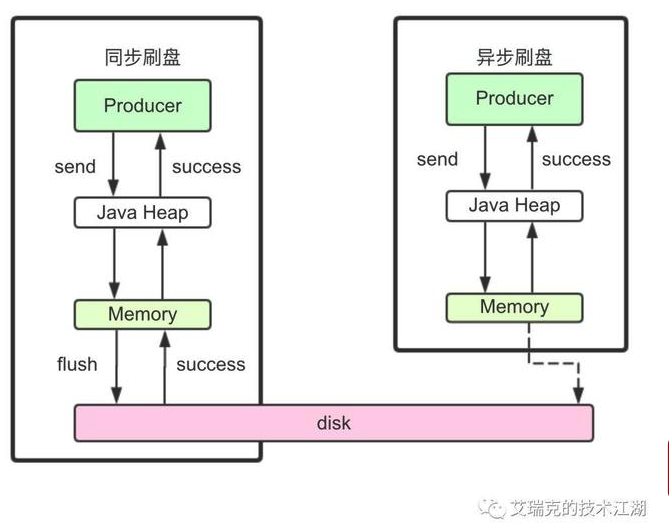
- 同步刷盘
在消息真正落盘后,才返回成功给Producer,只要磁盘没有损坏,消息就不会丢。
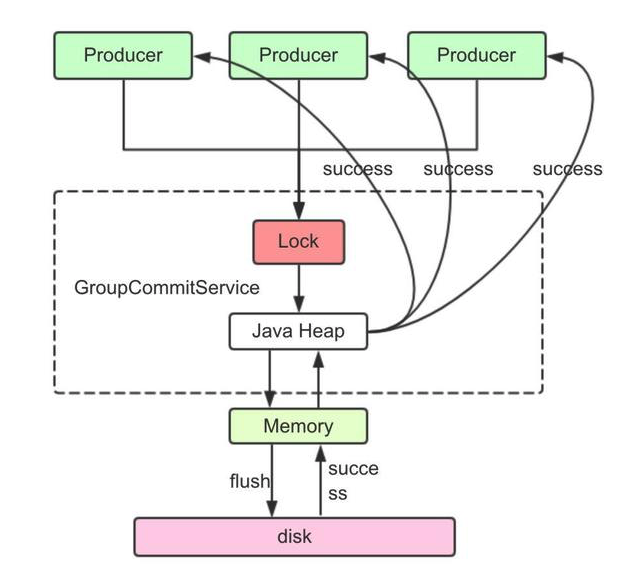 一般只用于金融场景,这种方式不是本文讨论的重点,因为没有利用Page Cache的特点,不管数据量大小,每次刷盘的时间几乎都是相同的,因此RMQ采用GroupCommit(锁粗化)的方式对同步刷盘进行了优化。
一般只用于金融场景,这种方式不是本文讨论的重点,因为没有利用Page Cache的特点,不管数据量大小,每次刷盘的时间几乎都是相同的,因此RMQ采用GroupCommit(锁粗化)的方式对同步刷盘进行了优化。 - 异步刷盘
读写文件充分利用了Page Cache,即写入Page Cache就返回成功给Producer,RMQ中有两种方式进行异步刷盘,整体原理是一样的。
当程序顺序写文件时,首先写到Cache中,这部分被修改过,但却没有被刷进磁盘,产生了不一致,这些不一致的内存叫做脏页(Dirty Page).
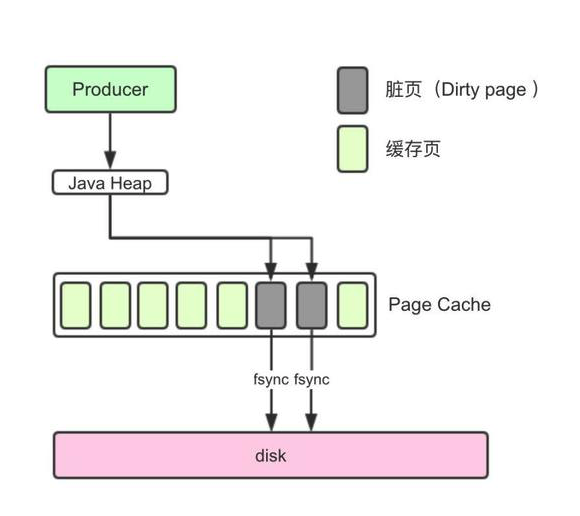 脏页设置太小,Flush磁盘的次数就会增加,性能会下降;脏页设置太大,性能会提高,但万一OS宕机,脏页来不及刷盘,消息就丢了。
脏页设置太小,Flush磁盘的次数就会增加,性能会下降;脏页设置太大,性能会提高,但万一OS宕机,脏页来不及刷盘,消息就丢了。
实例分析
假如集群有一个broker,topic为“biglog”的队列(consume queue)数量为4,按顺序发送这5条数据。
这时commit log 和consume queue的内容结构为:
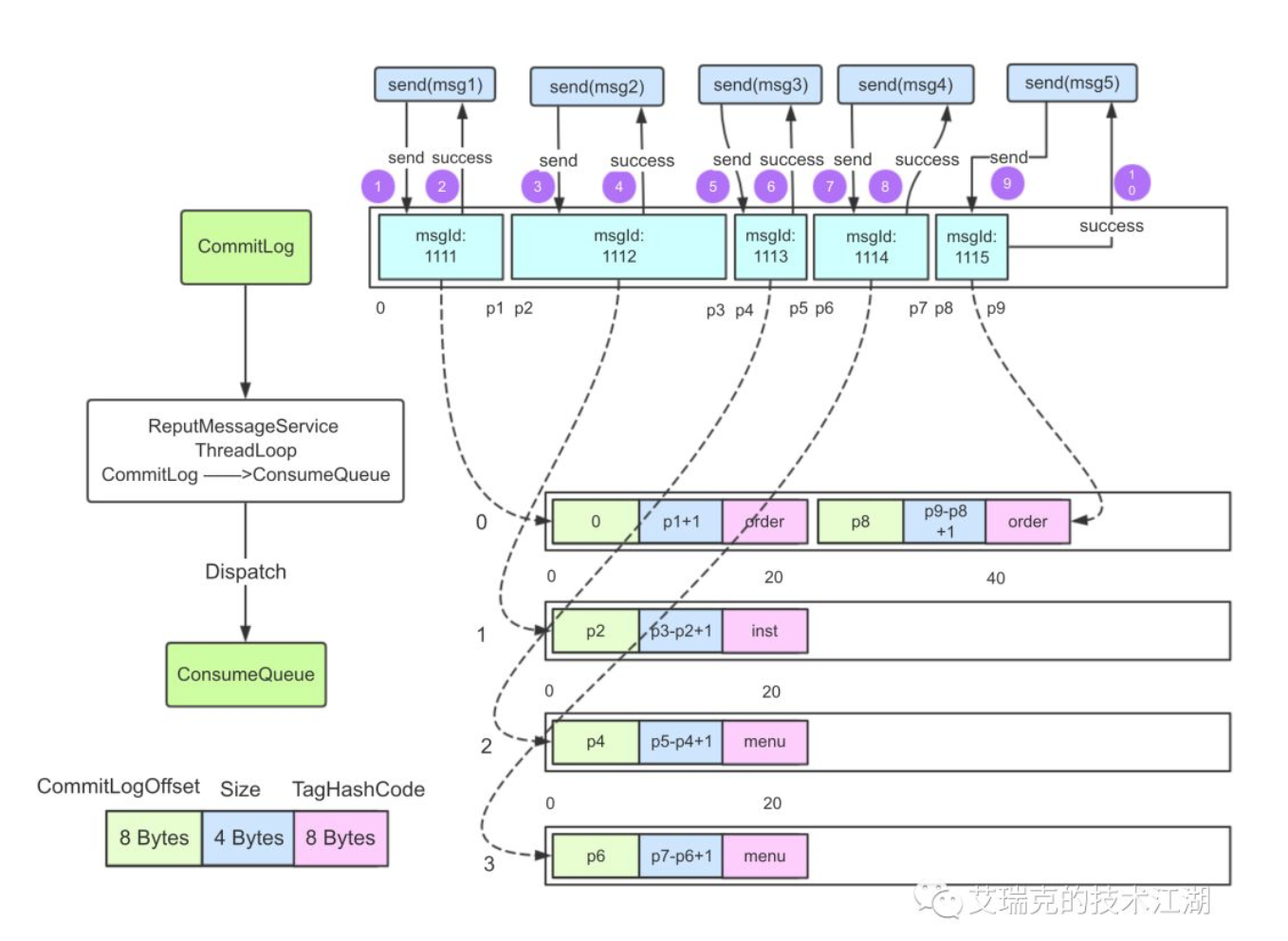 RocketMQ消息整体是有序的,所以这5条消息按顺序将内容持久化到Commit log 中,consume queue则是用于将消息均衡地按序排列在不同的逻辑队列。集群模式下多个消费者就可以并行消费consume queue的消息
RocketMQ消息整体是有序的,所以这5条消息按顺序将内容持久化到Commit log 中,consume queue则是用于将消息均衡地按序排列在不同的逻辑队列。集群模式下多个消费者就可以并行消费consume queue的消息
文件存储模型层次结构
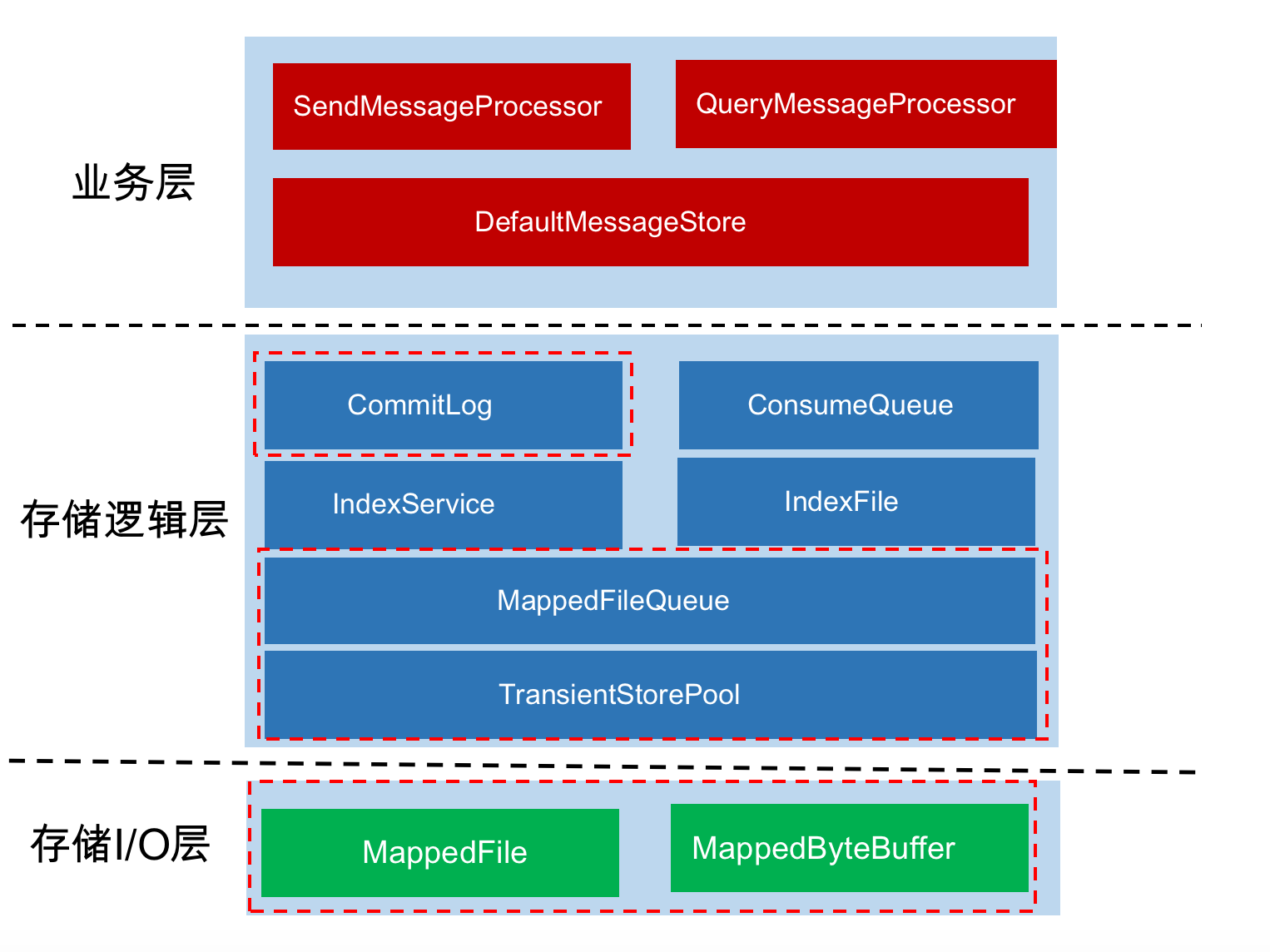 RocketMQ 文件存储模型层次结构如上图所示,根据类别和作用从概念模型上大致可以划分为5层,下面将从各个层次分别进行分析和阐述:
RocketMQ 文件存储模型层次结构如上图所示,根据类别和作用从概念模型上大致可以划分为5层,下面将从各个层次分别进行分析和阐述:
- RocketMQ 业务处理器层: Broker端对消息进行读取和写入的业务逻辑入口,这一层主要包含了业务逻辑相关处理操作(根据解析RemotingCommand中的RequestCode来区分具体的业务操作类型,进而执行不同的业务处理流程),比如前置的检查和校验步骤、构造MessageExtBrokerInner对象、decode反序列化、构造Response返回对象等;
- RocketMQ数据存储组件层: 该层主要是RocketMQ的存储核心类—DefaultMessageStore,其为RocketMQ消息数据文件的访问入口,通过该类的“putMessage()”和“getMessage()”方法完成对CommitLog消息存储的日志数据文件进行读写操作(具体的读写访问操作还是依赖下一层中CommitLog对象模型提供的方法);另外,在该组件初始化时候,还会启动很多存储相关的后台服务线程,包括AllocateMappedFileService(MappedFile预分配服务线程)、ReputMessageService(回放存储消息服务线程)、HAService(Broker主从同步高可用服务线程)、StoreStatsService(消息存储统计服务线程)、IndexService(索引文件服务线程)等;
- RocketMQ存储逻辑对象层:该层主要包含了RocketMQ数据文件存储直接相关的三个模型类IndexFile、ConsumerQueue和CommitLog。IndexFile为索引数据文件提供访问服务,ConsumerQueue为逻辑消息队列提供访问服务,CommitLog则为消息存储的日志数据文件提供访问服务。这三个模型类也是构成了RocketMQ存储层的整体结构(对于这三个模型类的深入分析将放在后续篇幅中);
- 封装的文件内存映射层:RocketMQ主要采用NIO中的MappedByteBuffer和FileChannel两种方式完成数据文件的读写。其中采用MappedByteBuffer这种内存映射磁盘文件的方式完成对大文件的读写,在RocketMQ中将该类封装成MappedFile类。这里限制的问题在上面已经讲过;对于每类大文件(IndexFile/ConsumerQueue/CommitLog),在存储时分隔成多个固定大小的文件(单个IndexFile文件大小约为400M、单个ConsumerQueue文件大小约5.72M、单个CommitLog文件大小为1G),其中每个分隔文件的文件名为前面所有文件的字节大小数+1,即为文件的起始偏移量,从而实现了整个大文件的串联。这里,每一种类的单个文件均由MappedFile类提供读写操作服务(其中,MappedFile类提供了顺序写/随机读、内存数据刷盘、内存清理等和文件相关的服务);
- 磁盘存储层:主要指的是部署RocketMQ服务器所用的磁盘。这里,需要考虑不同磁盘类型(如SSD或者普通的HDD)特性以及磁盘的性能参数(如IOPS、吞吐量和访问时延等指标)对顺序写/随机读操作带来的影响;
问题
RocketMQ 采用了什么存储方案?
目前主流的MQ采用的存储方式主要有以下三种方式:
- 分布式KV存储:这类MQ一般采用levelDB、rocksDB和Redis来作为消息持久化的方式,需要解决的问题是如何保证MQ整体的可靠性.\
- 文件系统:采用消息刷盘到文件系统来做持久化
- 关系型数据库DB:关系型数据库在表单数据量达到千万级别的情况下,其IO读写性能往往会出现瓶颈 从存储效率来看,文件系统>分布式KV存储>关系型数据库DB。 RocketMQ采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog)来存储。RocketMQ的混合型存储结构针对Producer和Consumer分别采用了数据和索引部分相分离的存储结构,Producer发送消息至Broker端,然后Broker端使用同步或者异步的方式对消息刷盘持久化,保存至CommitLog中。ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据。
这种存储方案为什么能带来性能的提升?
顺序读写、异步刷盘:
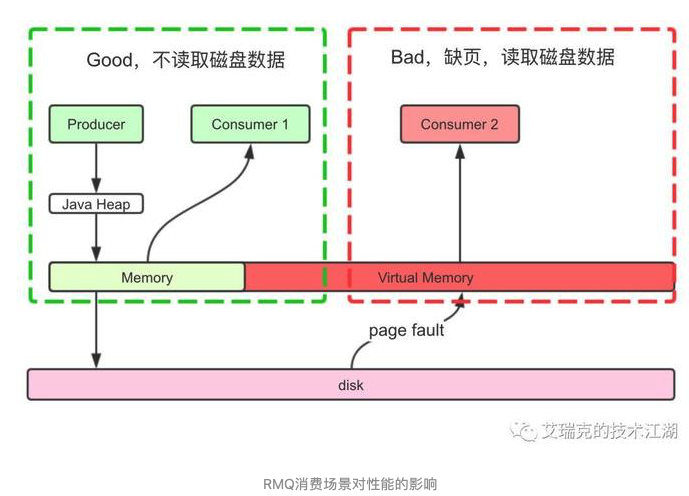 RMQ想要性能高,那发送消息时,消息要写进Page Cache而不是直接写磁盘,接收消息时,消息要从Page Cache直接获取而不是缺页从磁盘读取。
RMQ发送逻辑
发送时,Producer不直接与Consume Queue打交道。RMQ所有的消息都会存放在Commit Log中,为了使消息存储不发生混乱,对Commit Log进行写之前就会上锁。
RMQ想要性能高,那发送消息时,消息要写进Page Cache而不是直接写磁盘,接收消息时,消息要从Page Cache直接获取而不是缺页从磁盘读取。
RMQ发送逻辑
发送时,Producer不直接与Consume Queue打交道。RMQ所有的消息都会存放在Commit Log中,为了使消息存储不发生混乱,对Commit Log进行写之前就会上锁。
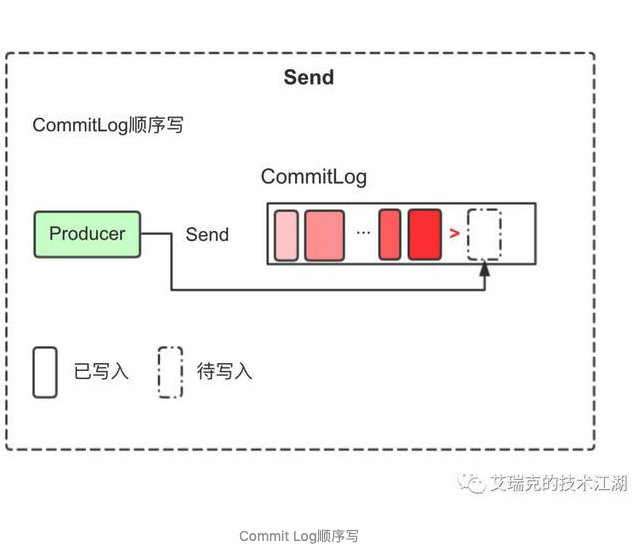 消息持久被锁串行化后,对Commit Log就是顺序写,也就是常说的Append操作。配合上Page Cache,RMQ在写Commit Log时效率会非常高。
Commit Log 持久后,会将里面的数据Dispatch到对应的Consume Queue上。
消息持久被锁串行化后,对Commit Log就是顺序写,也就是常说的Append操作。配合上Page Cache,RMQ在写Commit Log时效率会非常高。
Commit Log 持久后,会将里面的数据Dispatch到对应的Consume Queue上。
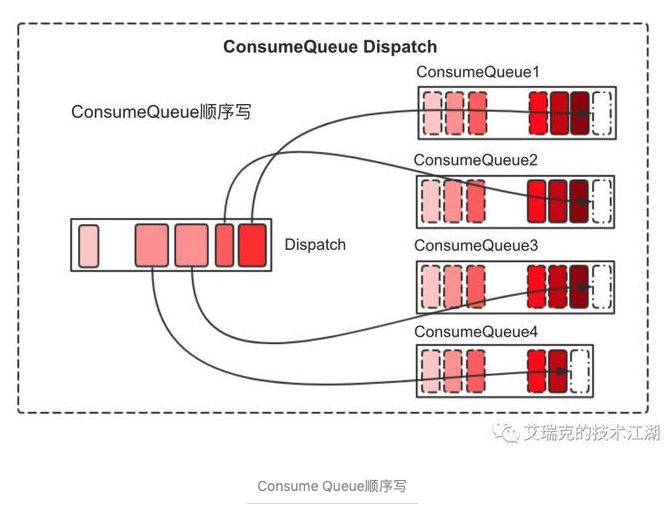 每一个Consume Queue代表一个逻辑队列,是由ReputMessageService在单个Thread Loop中Append,显然也是顺序写。
消费逻辑底层
消费时,Consumer不直接与Commit Log打交道,而是从Consume Queue中去拉取数据:
每一个Consume Queue代表一个逻辑队列,是由ReputMessageService在单个Thread Loop中Append,显然也是顺序写。
消费逻辑底层
消费时,Consumer不直接与Commit Log打交道,而是从Consume Queue中去拉取数据:
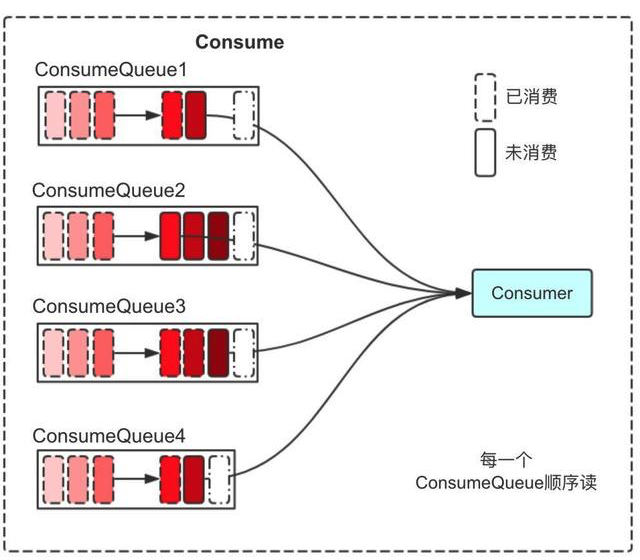 拉取的顺序从旧到新,在文件表示每一个Consume Queue都是顺序读,充分利用了Page Cache。光拉取Consume Queue是没有数据的,里面只有一个对Commit Log的引用,所以再次拉取Commit Log。
拉取的顺序从旧到新,在文件表示每一个Consume Queue都是顺序读,充分利用了Page Cache。光拉取Consume Queue是没有数据的,里面只有一个对Commit Log的引用,所以再次拉取Commit Log。
 Commit Log会进行随机读:
Commit Log会进行随机读:
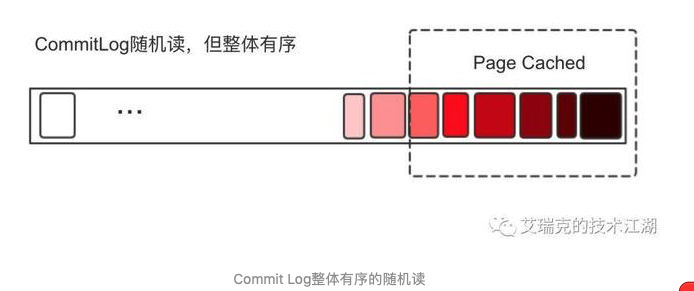 但整个RMQ只有一个Commit Log,虽然是随机读,但整体还是有序地读,只要那整块区域还在Page Cache的范围内,还是可以充分利用Page Cache。
但整个RMQ只有一个Commit Log,虽然是随机读,但整体还是有序地读,只要那整块区域还在Page Cache的范围内,还是可以充分利用Page Cache。
魔数的作用?
首先判断文件的魔数,如果文件的魔数不对,说明不是消息的存储文件。直接返回false. 按照当初存储消息的顺序来进行读取消息:
- 读取消息总大小
- 读取消息魔数
- 如果魔数是MESSAGE_MAGIC_CODE,那么走到3
- 如果魔数是BLANK_MAGIC_CODE, 说明是空白填充,直接返回。size = 0, success = true.
- 如果是别的那么打印warn级别日志,并返回异常。 size = -1 , success = false.
- 读取一系列的msg属性