HBase是非常热门的一款分布式KV数据库系统,国内各大公司都使用HBase存储海量数据。本质上HBase是一个稀疏的、高可靠性、面向列、可伸缩的分布式存储系统。
历史背景
2004年-2006年,Google发表了风靡一时的“三篇论文”-GFS、MapReduce、BigTable。
- GFS: 揭示了如何在大量廉价机器基础上存储海量数据。
- MapReduce:论述了如何在大量廉价机器上稳定的实现超大规模的并行数据处理。(DAG模型)
- BigTable:用于解决Google内部海量结构化数据的存储以及高效的读写问题。
科技巨头Yahoo按照论文时间出一个简易版的HDFS和MapReduce,一家叫做Powerset的公司,实现了BigTable的开源版本-HBase,并被Apache收录为顶级项目
存储类型
- 行式存储:将一行数据存储在一起。如典型的mysql,获取一行数据是高效的,适合OLTP。
- 列式存储:将一列数据存储在一起。如clickhouse,获取一列数据是高效的,压缩效率高,适合OLAP.
- 列簇式存储:介于行式存储和列式存储之间,可以相互切换,如单簇包含所有列,或者每簇只设置一列。
系统特性
优点:
- 容量巨大:HBase单表可以支持千亿行、百万列的数据规模,数据容量可以达到TB甚至Pb级
- 良好的扩展性:HBase集群可以简单的增加DataNode节点实现存储扩展,简单的增加RegionServer节点实现计算层的扩展。
- 稀疏性:允许大量列值为空,并且不占用存储空间。
- 高性能:数据写操作性能强劲,对于随机单点读以及小范围的扫描读,性能也能够保证。
- 多版本:HBase支持多版本,一个KV可以同时保留多个版本。
- 支持过期:支持TTL过期特性,
- 数据存储在hdfs上,备份机制健全;
缺点:
- 不支持复杂的聚合运算
- 不支持二级索引功能
- 不支持全局跨行事务,只支持单行事务
系统架构
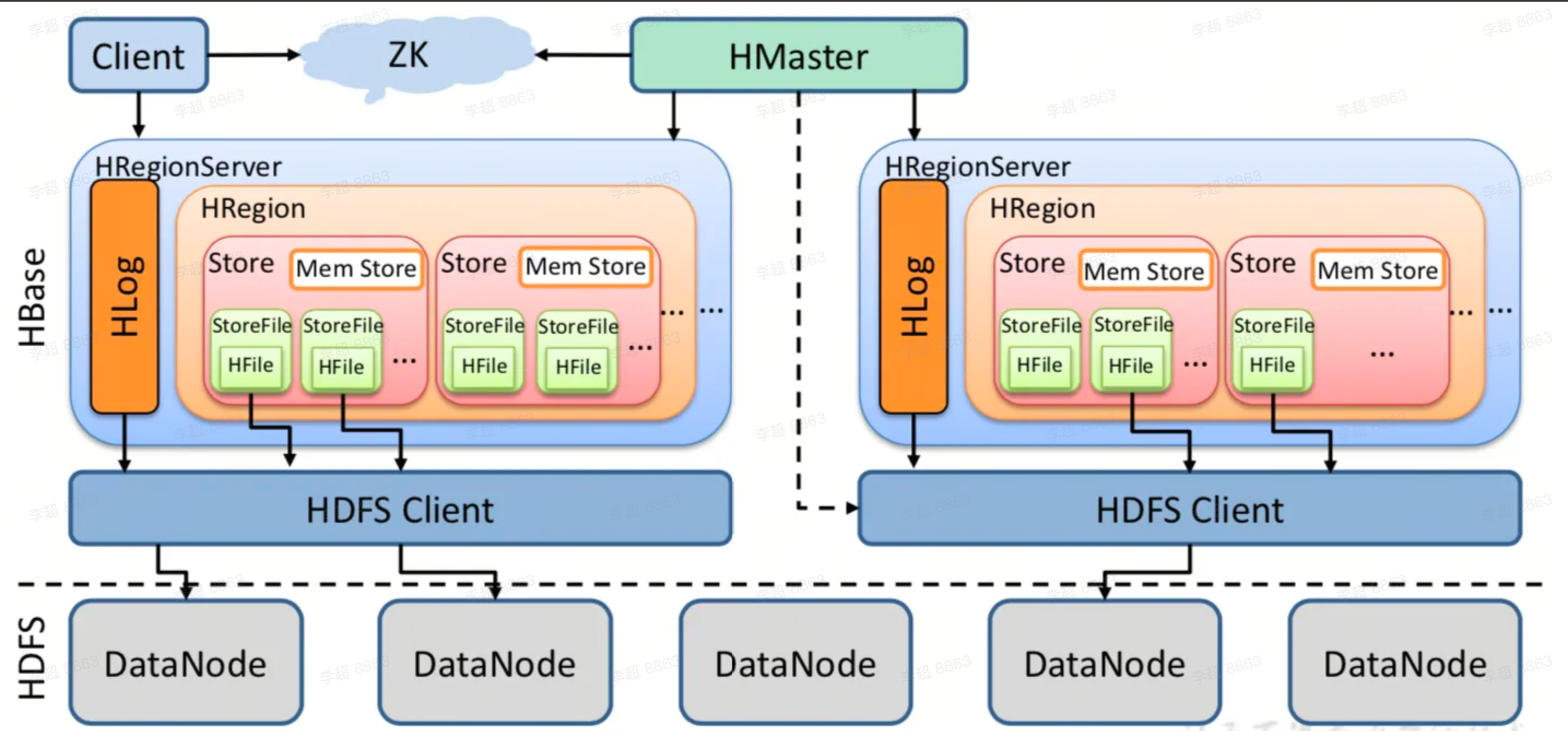
- Zookeeper: 实现Master高可用、管理系统核心元数据、参与RegionServer宕机恢复、分布式锁。
- Master: 处理管理请求: 表操作、权限操作、合并数据分片、Compaction。管理RegionServer的负载均衡、宕机恢复、迁移。清理过期日志及文件。
- RegionServer: 响应用户的IO请求,是HBase最核心的模块。
- HDFS: HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,包括数据文件HFile、日志文件HLog File存储。
RegionServer
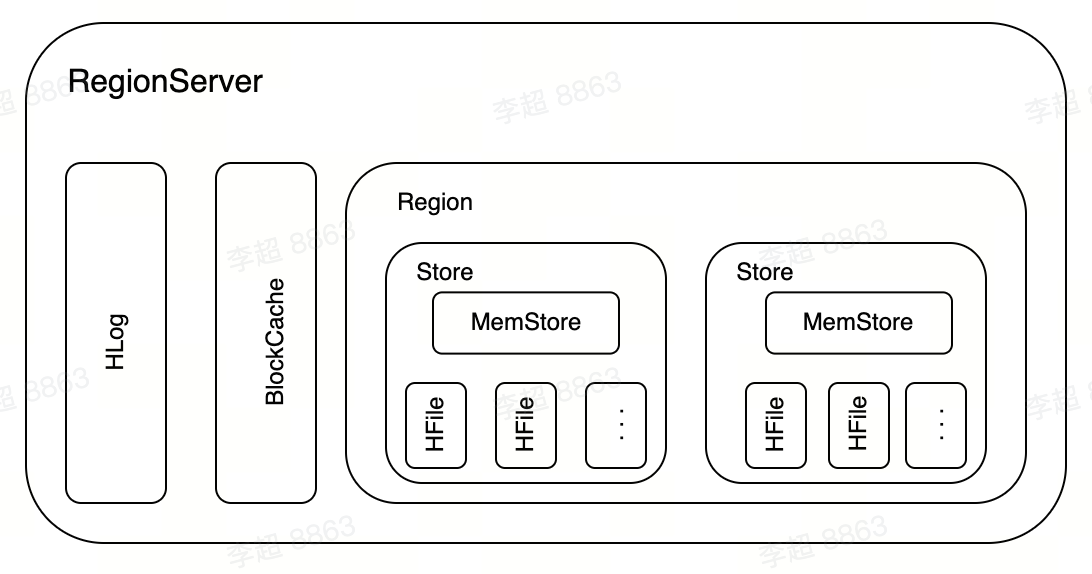
RegionServer是HBase系统中最核心的组件,主要负责用户数据的写入、读取等基础操作。
HLog
HBase中系统故障恢复以及主从复制都基于HLog实现。
所有写入操作(写入、更新以及删除)的数据都先以追加形式写入HLog,再写入MemStore。如果RegionServer在某些异常情况下发生宕机,此时写入MemStore中但尚未flush到磁盘的数据就会丢失,需要回放HLog补救丢失的数据。
HBase主从复制需要主集群将HLog日志发送给从集群,从集群在本地执行回放操作,完成数据复制。
每一个RegionServer拥有一个或多个HLog,默认1个,HLog由HLogKey和WALEdit两部分组成,HLogKey由tablename、region name以及sequenceid等字段组成。WALEdit表示一个事物中的更新集合,一次事物变更HLog只会写入一行记录。

默认每隔一个小时创建一个新的日志文件,数据已经刷盘则认为文件失效,会将日志文件从WALS文件夹移动到oldWALs文件夹。
默认每隔一分钟检查oldWALs文件夹下的失效日志文件,如果没有参与主从复制,且已经存在目录中10分钟,则会删除该文件。
BlockCache
BlockCache将数据块缓存在内存中以提升数据读取性能。
Region
HBase系统中一张表会被水平切分成多个Region。每个Region负责自己区域的数据读写请求。水平切分意味着每个Region会包含所有的列簇数据。一个RegionServer上通常会负责多个Region的数据读写。
Store
-个Region由多个Store组成,每个Store存放对应列簇的数据,如果一个表有多个列簇,这个表的所有Region就都会包含多个Store。
MemStore
每个Store包含一个MemStore和多个HFile,用户数据写入时会将对应列簇数据写入相应的MemStore,一旦写入数据的内存大小超过设定阈值,系统会将MemStore中的数据落盘形成HFile文件。HFile存放在HDFS上,是一种定制化格式的数据存储文件,方便用户进行数据读取。
MemStore由两个ConcurrentSkipListap实现,当第一个ConcurrentSkipListMap中数据量超过阈值后会创建一个新的ConcurrentSkipListMap来接收用户新的请求,之前已经写入第一个ConcurrentSkipListMap的数据会异步执行flush操作落盘形成HFile。
MemStore的内存问题:
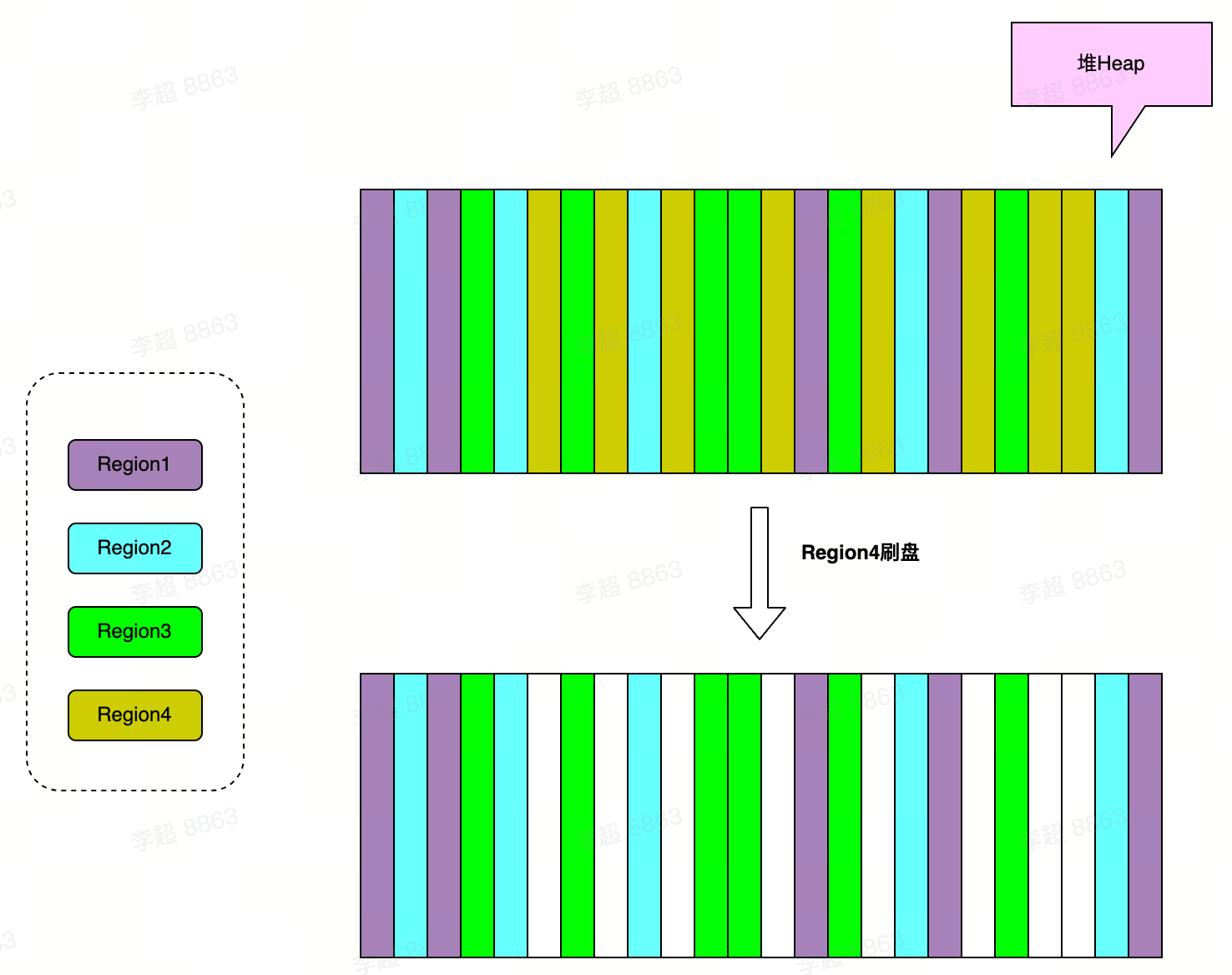
不同的Region共享缓存内存,当某个Region的数据执行落盘操作,会造成大量的白色内存条,这些内存条继续为数据分配内存,会变成更小的内存条,这些条带就是内存碎片,随着内存碎片越来越小,无法分配足够大的内存给写入的对象时,导致耗时长的Full GC。
治理: MSLAB内存管理(顺序化分配内存、内存数据分块使内存碎片保持粗粒度,2M Chunk内存数组但会有新生代Eden区满,触发YGC)–>Chunkpool池化
HFile
HFile由很多相同数据结构但类型不同的Block组成。介绍其中两种block类型Meta:
- Block:存储布隆过滤器相关元数据信息
- Data Block:存储用户KeyValue信息,
Data Block是HBase中文件读取的最小单元,内存和磁盘中的Data Block结构如下图:
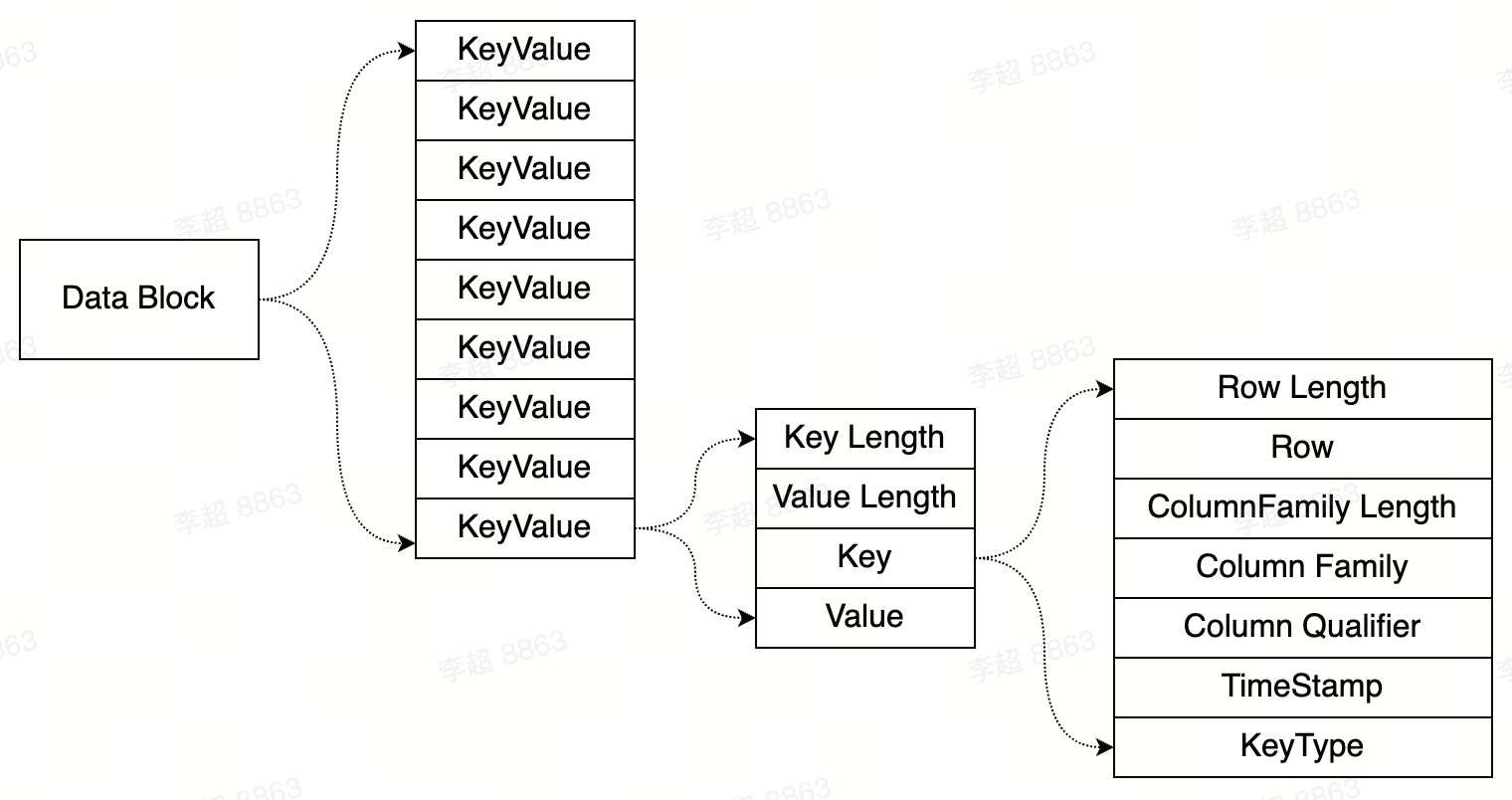
任意KeyValue中都包含Rowkey、Column Family以及Column Qualifier,因此这种存储比直接存储value占用更大的存储空间,这也是HBase系统在表结构设计时经常强调Rowkey、Column Family以及Column Qualifier尽可能设置短的根本原因。
读写流程
写入
HBase采用LSM树结构,天生适合写多读少的应用场景。Hbase中对于更新操作会写入一个最新版本数据,对于删除操作会写入一条标记为删除的KV数据,所有其他操作与写入流程完全一致。
写入流程可以概括为三个阶段:
- 客户端处理: 客户端根据rowkey到zk中获取rowkey所在的RegionServer和Region信息(本地缓存),发起RPC调用(可以设置批量写入,有可能丢失本地数据)
- Region写入:
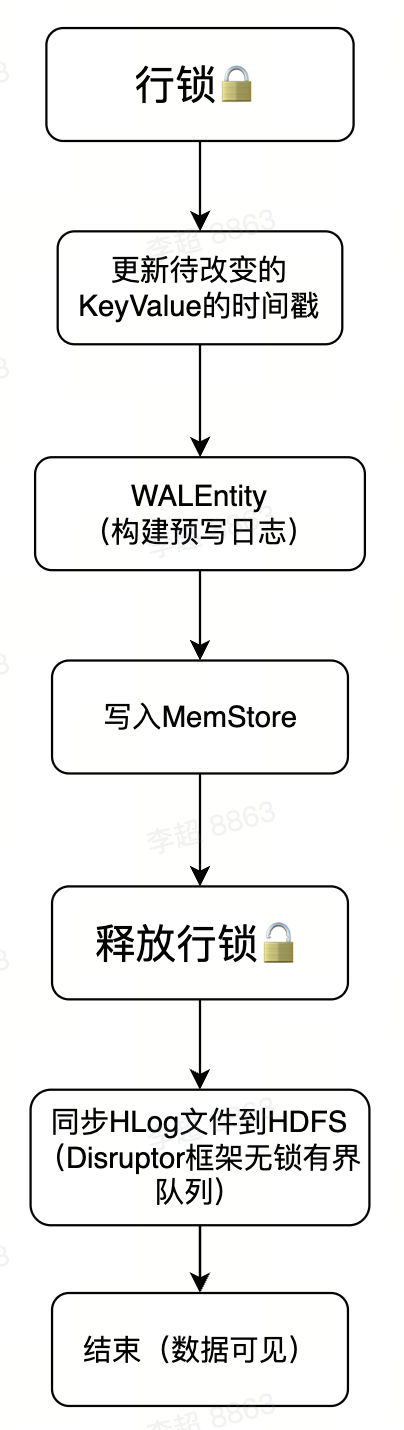
- MemStore Flush: HBase会在以下几种条件下触发flush操作:
- MemStore级别限制:当单个MemStore大小达到默认128M
- Region级别限制:当Region中所有MemStore的大小总和达到了上限xxx.size
- RegionServer级别限制:当RegionServer中MemStore的大小总和超过低水位阈值xxx.size4、当一个RegionServer中Hlog数量达到上限,选择最早的HLog进行flush
- 默认定期1小时flush
- 手动执行flush
读取
一、客户端处理,客户端根据rowkey到zk中获取rowkey所在的RegionServer和Region信息(本地缓存),数据读取可以分为get和scan两类,get请求也是一种scan请求,所以读操作都可以认为是一次scan操作。但是一次大的scan操作可能扫描结果非常之大,所以客户端需要分批循环查询。
一次scan请求可能会扫描一张表的多个Region,对于这种扫描,客户端会根据meta元数据将扫描的区间[startKev,stopKey]切分为多个互相独立的查询子区间,每个子区间对应一个Region。
二、Server端处理,收到客户端的请求之后,首先构建scanner iterator体系,然后执行next函数获取KeyValue,并对其进行条件过滤
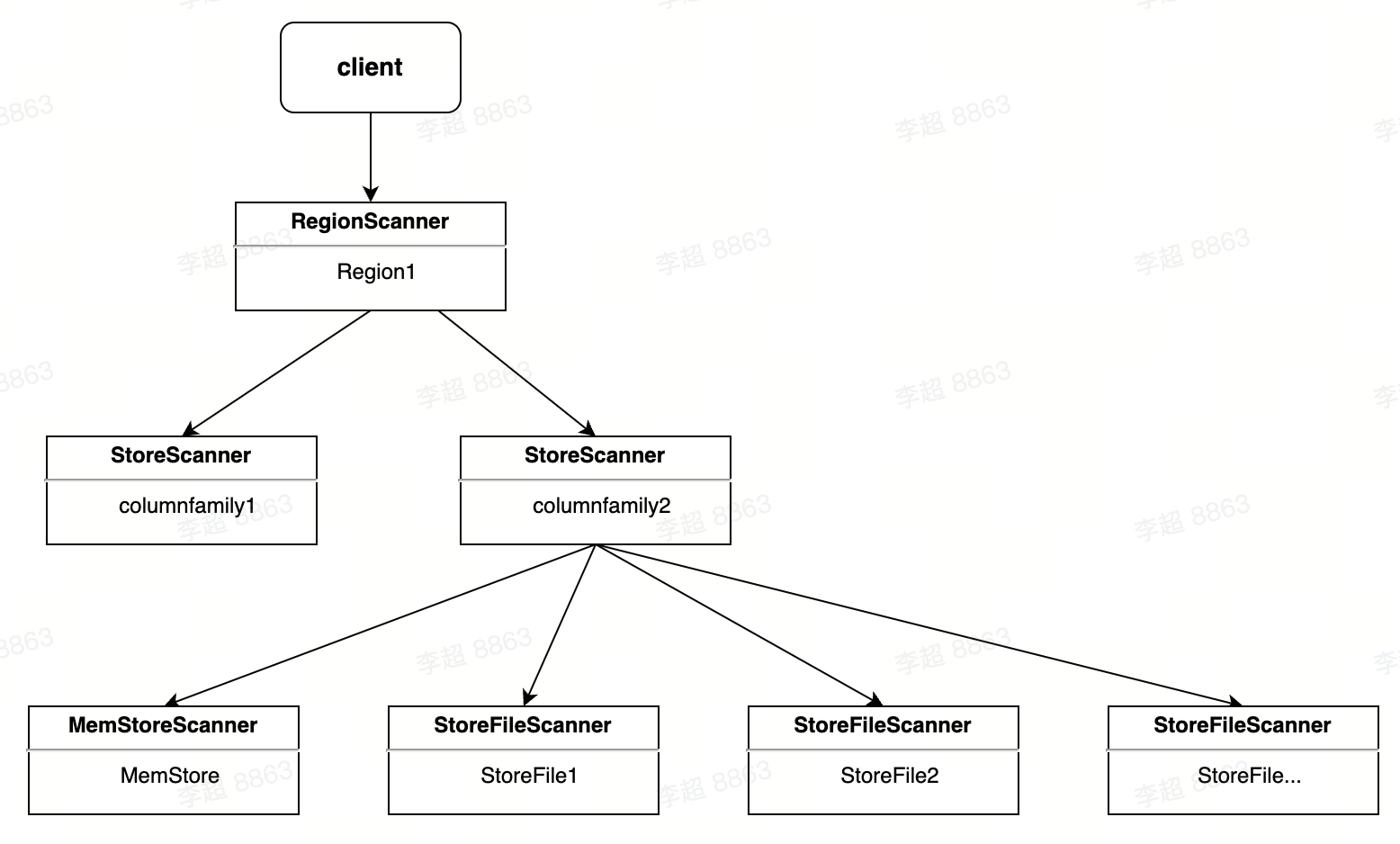
一个RegionScanner由多个StoreScanner构成。一张表由多少个列簇组成,就有多少个StoreScanner,每个StoreScanner负责对应的Store的数据查找。
一个StoreScanner由MemStoreScanner和StoreFileScanner构成。StoreScanner会为当前该Store中每个HFile构造一个StoreFileScanner,用于执行对应文件的检索。
MemStoreScanner用于执行该Store中MemStore的数据检索。RegionScanner和StoreScanner并不负责实际查找工作,他们更多地承担组织调度任务,负责KeyValue最终查找操作的是MemStoreScanner和StoreFileScanner。
构建完Scanner体系后,执行如下核心的关键步骤:
- 过滤淘汰部分不满足查询条件的Scanner,主要过滤策略有:Time Range过滤、Rowkey Range过滤以及布隆过滤。
- 每个Scanner seek到startKey。
- 将该Store中的MemStoreScanner和StoreFileScanner合并构成一个最小堆heap,按照Scanner排序规则将Scanner seek得到的KeyValue由小到大进行排序,依次不断地pop就可以由小到大获取KeyValue集合,保证有序性。
- 检查KeyValue是否满足用户设定的Time Range条件、版本号条件以及Filter条件。
数据压缩(Compaction)
用户数据在LSM树体系架构中最终会形成一个一个小的HFile文件。如果HFile小文件数量太多会导致读取低效,为了提高读取效率,LSM树体系架构设计了一个非常重要的模块-Compaction。一般基于LSM树体系结构的系统都会设计Compaction,比如LevelDB、RocksDB.
原理:
Compaction是从一个Region的一个Store中选择部分HFile文件进行合并。先从这些待合并的数据文件中依次读出KeyValue,再由小到大排序后写入一个新的文件,之后,这个新生成的文件就会取代之前已合并的所有文件对外提供服务。
HBase根据合并规模将Compaction分为两类:MinorCompaction和Major Compaction。
Minor Compaction是指选取部分小的、相邻的HFile,将他们合并成一个更大的HFile。
Major Compaction是指将一个Store中所有的HFile合并成一个HFile,这个过程还会清理三类无意义的数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。
一般情况下,Major Compaction持续时间会比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响,因此线上部分数据量较大的业务通常推荐关闭自动触发Maior Compaction功能,改为在业务低峰期手动触发,或者设置策略自动在低峰期触发。
触发时机:
- MemStore Flush时检查
- 后台线程周期性检查
- 手动触发
作用:
- 合并小文件,减少文件数,稳定随机读延迟。
- 提高数据的本地化率。
- 清除无效数据,减少数据存储量。
- 带来很大的带宽压力和短时间I0压力