图数据库是NoSQL(非关系型)数据库的一种实现,以实体及其关系为主要存储对象的数据库系统,是一个使用图结构进行语义查询的数据库。
基本概念
- 图(Graph):指关系图
- 顶点(Vertex):一般指实体。比如:用户、文章、视频等。
- 边(Edge):一般指顶点之间的关系。比如:用户关注了用户、用户发表了文章等。
- 属性(Property):顶点或边都可以拥有对应的属性。
- 顶点属性:用户是否是大V,文章的发表时间等。
- 边属性:用户给某文章的点赞时间/发表时间等。
- N跳查询:沿着指定路径查询N次
- 查询用户A的关注用户是一跳查询;查询用户A的关注用户的关注用户,即为两跳查询
- 入边和出边:箭头起为出边,止为入边。
数据模型
数据模型是数据库的抽象框架、信息世界的逻辑模型。最为常用的「关系模型」,它太流行了,利用SQL一统江湖,具备坚实的理论和运算基础,而在描绘多对多关系的时候表达能力和效率稍微逊色。「文档模型」的出现虽然在某些场景下提升了效率,不过其更适合单打独斗(1vN),显得略微呆板。
- 「关系模型」中数据被组织成关系,而每个关系作为元组(tuples)的无序集合呈现为通俗意义上的“行”。
- 「文档模型」数据通常被组织为树状结构,以此来形成一篇通俗意义上的“文档”。
- 「图状模型」由节点与节点经过边连接,通过节点或边上携带信息(属性)表达整个关系,形成通俗意义上的“图”。

越是复杂多样的信息就越加需要一种简单通用的方式来“记住”它。「图状模型」是一个更加简单的方案,甚至几乎可以自然再现所有其他数据模型。图数据模型并不需要像关系模型一样有规范化的表格结构,结构复杂多样,具备了天然可解释性。
为什么需要使用图数据库
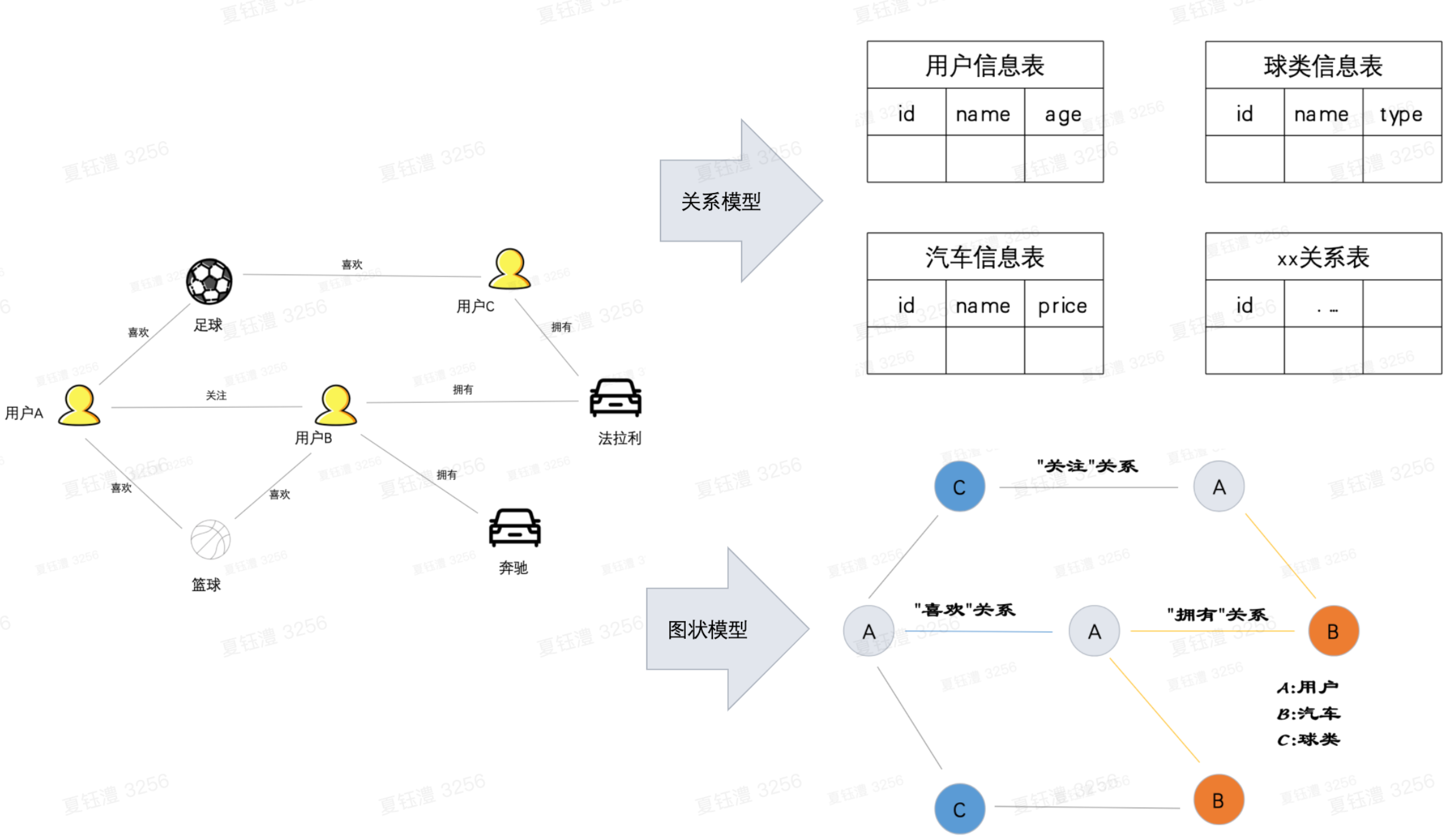
适合处理数据关系,更加直观和容易理解,不用设计复杂的关系表,各种连表join等操作:
- 针对上图例子,如果设计关系型数据库,需要有用户信息表、球类信息表、骑车信息表、用户和球类的关系表,用户和汽车的关系表….
- 当需要实现“年龄小于18的用户,关注的用户喜欢的球类”这样的一个查询需求,需要关联用户信息表、用户关注关系表、用户和球类的关系表、球类信息表等,无论是写SQL和查询效率来看,都不如图数据库的直观和高效。
处理数据关系方面具有高性能:
- 可存储的数据量大:图数据库面向的应用领域数据量可能都比较大,比如知识图谱、社交关系,总数据量级别一般在亿或十亿以上。Mysql在不做分表分库的情况下,插入百万级别数据已经较慢,图数据库比如neo4j、bytegraph等图数据库,在十亿/千亿的数据量级还能保持较高的性能。
- 效率高:关系型数据库在数据规模庞大时很难做多层关联关系分析(Join操作往往消耗过长时间而失败),图数据库则天然把关联数据连接在一起,无需耗时耗内存的Join操作,可以保持常数级时间复杂度。
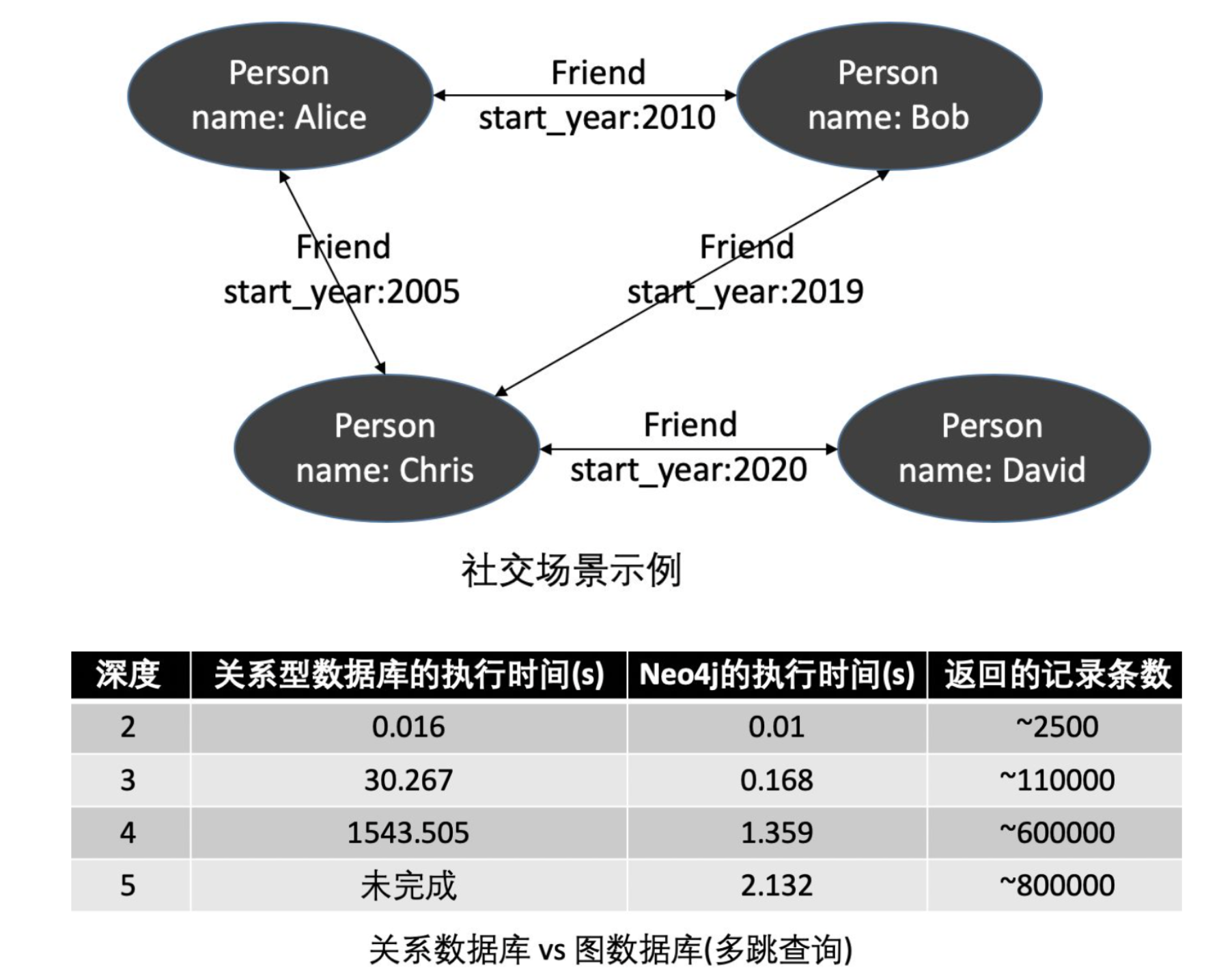
灵活的数据模型可以适应不断变化的业务需求:
- 可以不断增加/删除 顶点/边 类型,扩大/缩小数据模型
“真假”图数据库
图数据库在设计时存在不同的权衡点,由此诞生两种存储计算模式【原生图】和【非原生图】。
- 原生图/非原生图存储
- 底层的数据存储格式是否以图的形式存储图
- 原生图存储是通过将顶点和关系边写入到“相近”的位置来保证高效的存储,关系是直接“读”出来而非“计算”出来。
- 使用外部存储DB一般是非原生。
- 原生图存储参考。
- 底层的数据存储格式是否以图的形式存储图
- 无索引邻接/索引邻接
- 无索引邻接:每个节点都直接引用其相邻节点,充当所有附近节点的微索引,原生图一般是通过无索引邻接进行实现。具有查询快高效的特性,查询时间与搜索的跳数成正比,而不是随数据的整体大小而增加。
权衡之下的妥协:
「非原生图」模式在存储之上封装图的语义,其优点是易于开发,适合产品众多的大型公司,形成相互配合的产品栈,这些数据库支持图的表示和遍历,查询语言常采用Gremlin、或者类似SQL的语言,无论是底层的扩展还是业务的研发都具备难度更低的曲线,例如腾讯图计算TGraph
妥协之后的再生:
「非原生图」数据库由于受到底层存储模式的限制,在处理多层遍历时,其性能往往会受到影响。为此为了减少这种影响,最为直接的方案就是改变自身的存储模式,如ByteGraph目前是典型的依赖于KV(ABase/ByteKV)的「非原生图」数据库,探索图的原生存储是未来发展的一大方向。
图数据的切分与存储
业务规模通常以「海量数据」的形式呈现。
各具特色的数据分布形式
「正态分布」在自然界非常常见,它具有中间多,两头少的特点,比如身高多集中在平均身高区域,极矮或极高的人属于少数。
「幂律分布」它是一个不断下降的曲线,从最高的峰值开始极速下降,后面拖了一个长长的尾巴,比如微博大V拥有百万粉丝,而普通人的关注度则寥寥无几。
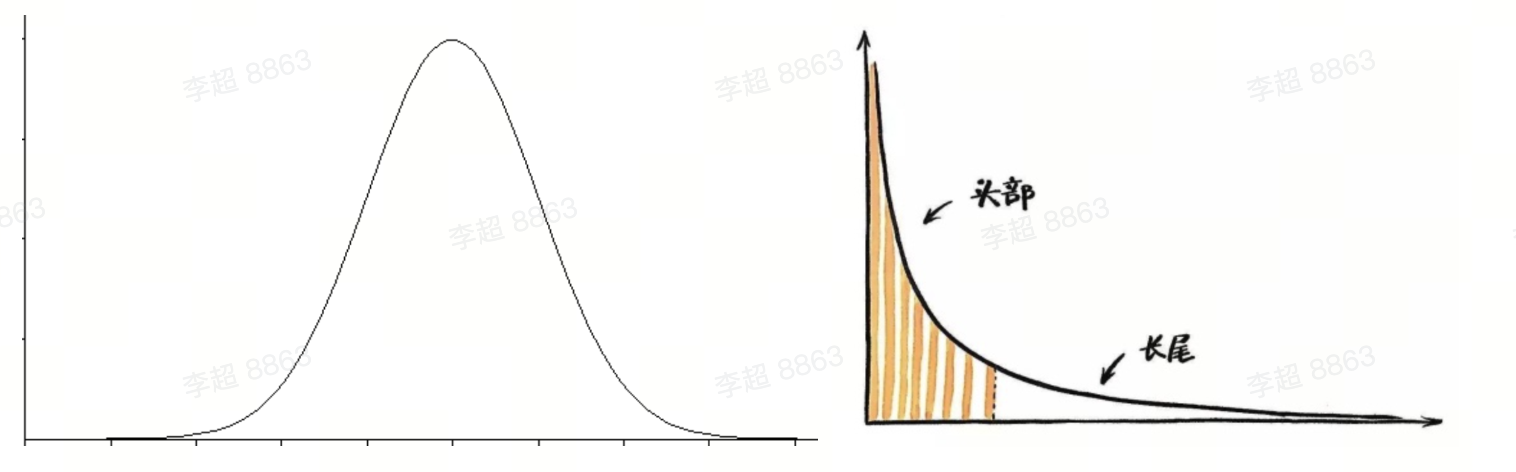
「数据倾斜」的情况非常常见,当一个点与图中大多数的点有联系,应该如何将这些点分开储存在不同的节点机房上,是尽量减少跨分块的边,牺牲内存减少节点与节点这间的通讯开销;还是减少内存消耗,转而增加通讯开销,都是一个值得权衡思考的问题。
几种常见的图切分方式
「海量数据」和「数据倾斜」两个座”大山”面前意味着很难用单台机器的模式完成存储和计算工作,所以「分布式存储计算」成为目前很多成熟图数据库的首选方案,而图的划分成为分布式的第一个门槛。
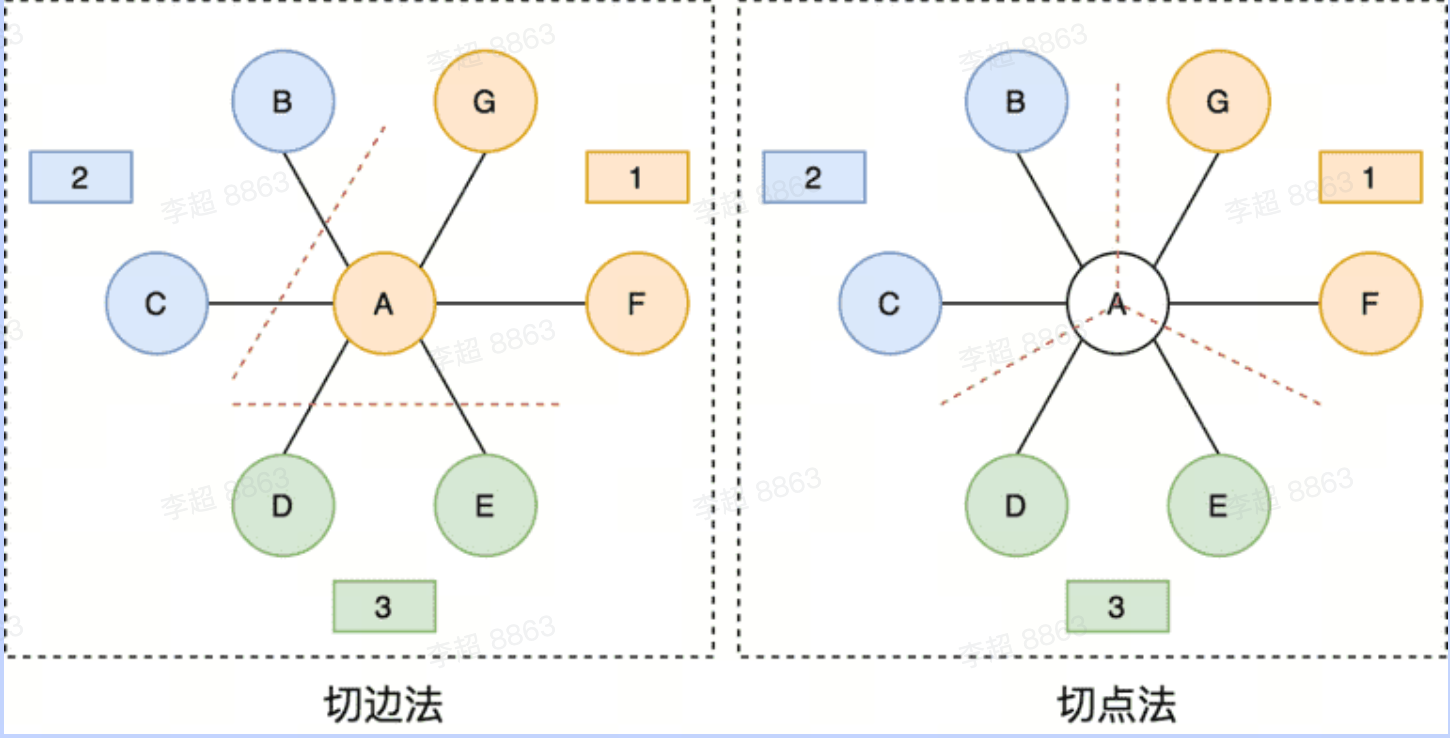
「边切分」每个顶点都仅存储一次,但是有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,需要跨机器通信传输数据,内网通信流量大。
「点切分」每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
总结
- 图的本质难题是什么?是数据的高度关联带来的严重的「随机访问」。
所以,传统的关系型数据库解决不了这个问题,因为在面对复杂的图状数据时它们采用二维表格的语义进行解释,如果单纯利用「关系模型」来”强行”解释「图状模型」,那么随着图的复杂度增加导致性能衰减得会越加厉害。
为此图数据库的发展目标仍然是面向磁盘优化的,尽可能利用磁盘顺序读写的优势。如一些开源「原生图」数据库(neo4J)利用原生的特性保证顺序的读写,而对于一些「非原生图」数据库则通过精心设计底层的存储逻辑来尽可能满足顺序的读写。
- 图的分区涉及分布式存储,是任何一款具备生产力图数据库必须跨越的问题。完美的最小割图分区算法是NP难题,而且在数据写入的情况下还要面临动态调整的难题。如果使用naive的分区算法,网络通讯开销是巨大瓶颈。
最后靠新硬件来解决当下的问题也是不错的选择,更廉价的大内存、NVRAM、RDMA高速网络、随机读写更强的SSD磁盘、有硬件事务支持的CPU等。