基础架构
ByteGraph整体架构自上而下分为两层:
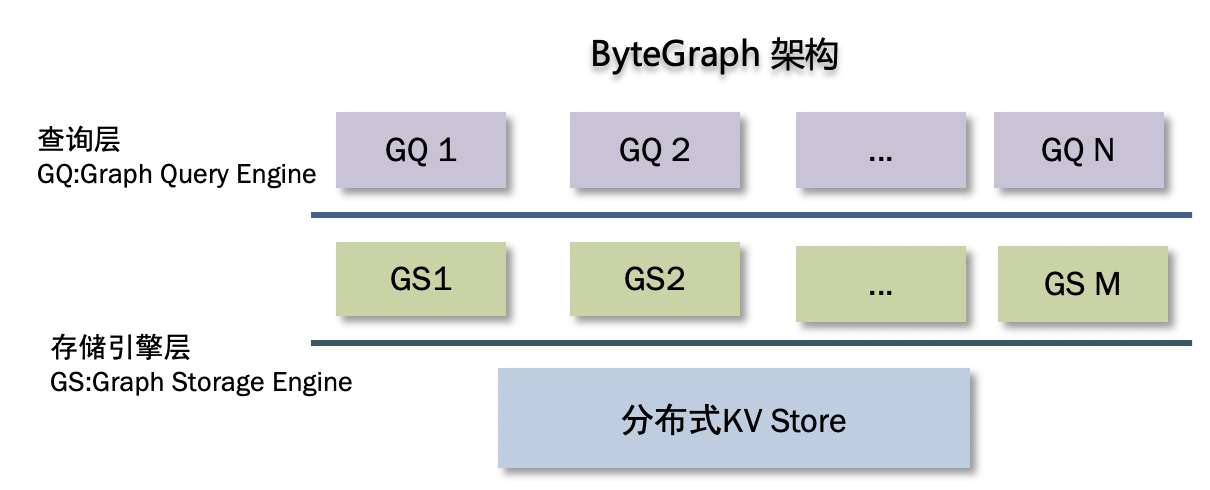
GQ查询层
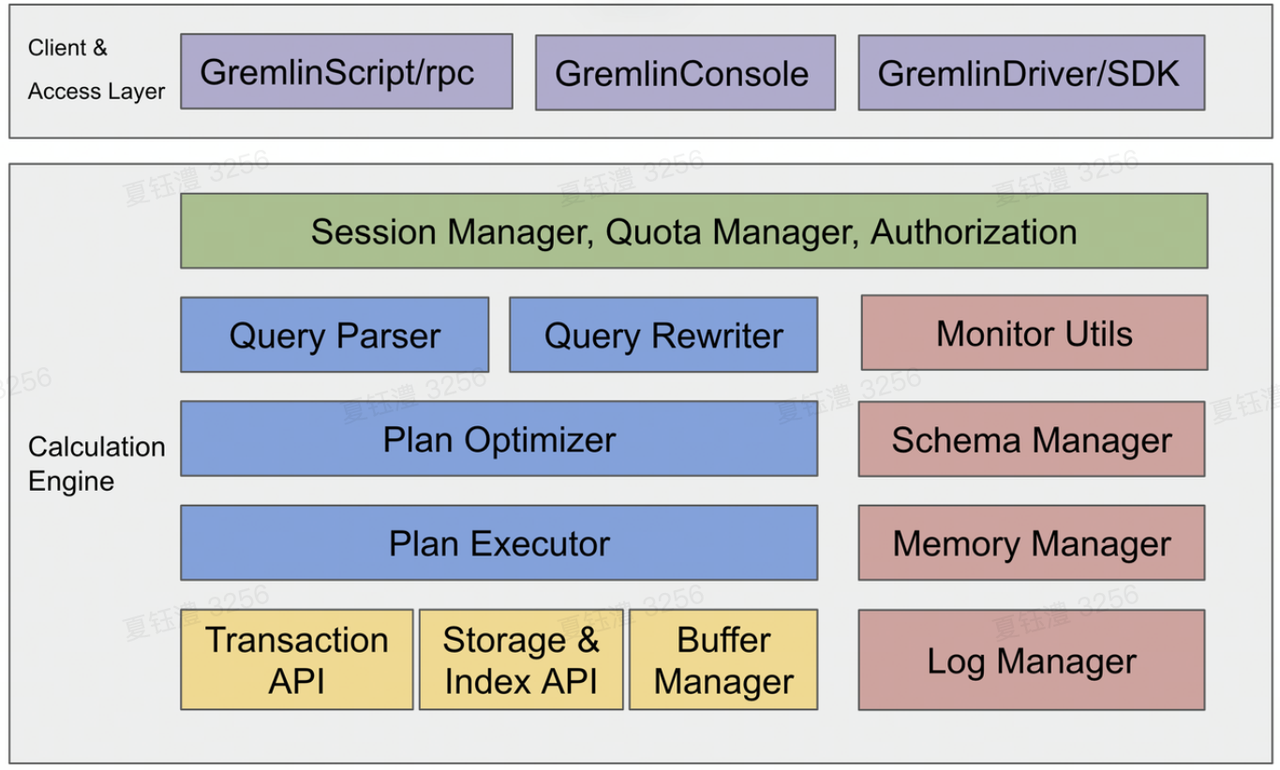
GQ 主要工作是做查询的解析和处理:
- parser阶段:把查询语言解析成一个查询语法树,为了提升parser效率,BG内部设置了查询计划缓存。
- 生成查询计划:把步骤1的查询语法树按照一定的查询优化策略(RBO & CBO)转成查询计划。
- 执行查询计划:与GS层交互,需要理解存储层分partition的逻辑,找到数据,下推算子,merge查询结果,完成查询。
GS存储引擎层
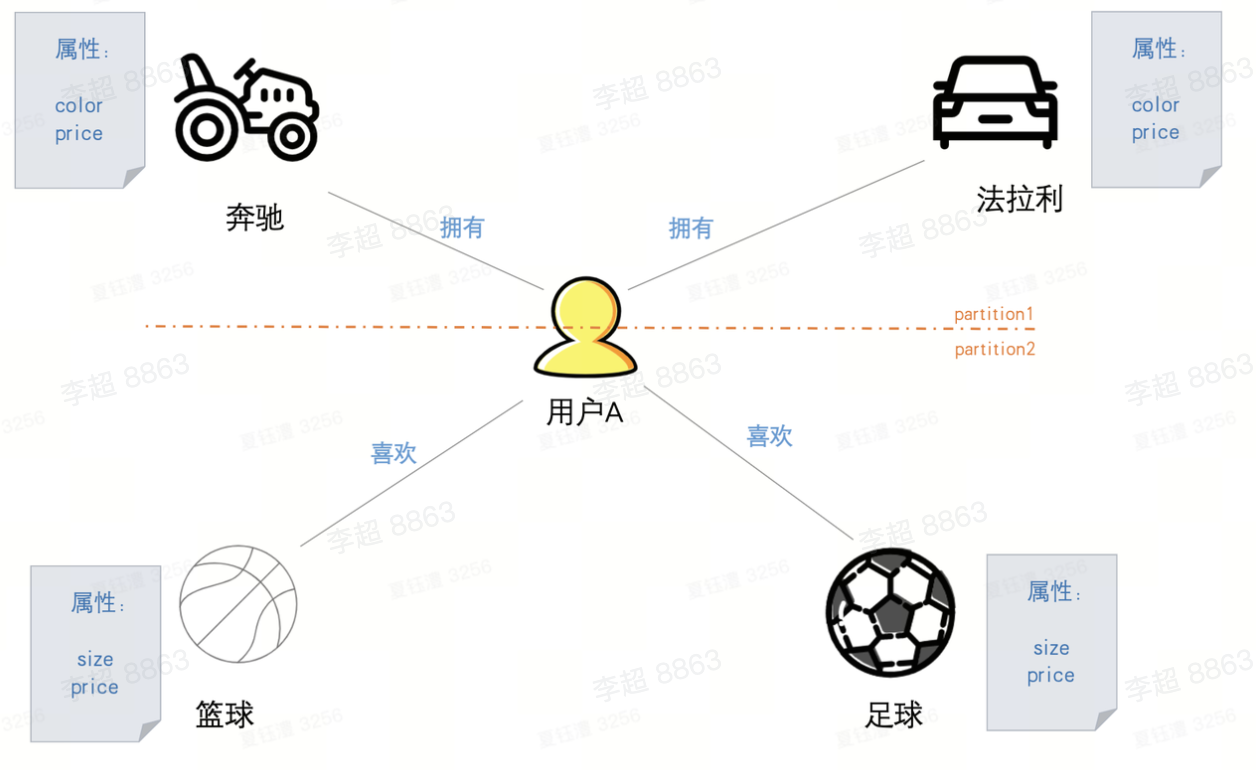
「分布式存储计算」的思想,采用不同的策略将图划分为不同的子图「Partition」,采用精巧的数据结构来进一步组织「Partition」的内存布局方式,并采用一定的策略来构建内存与磁盘的交换模式。
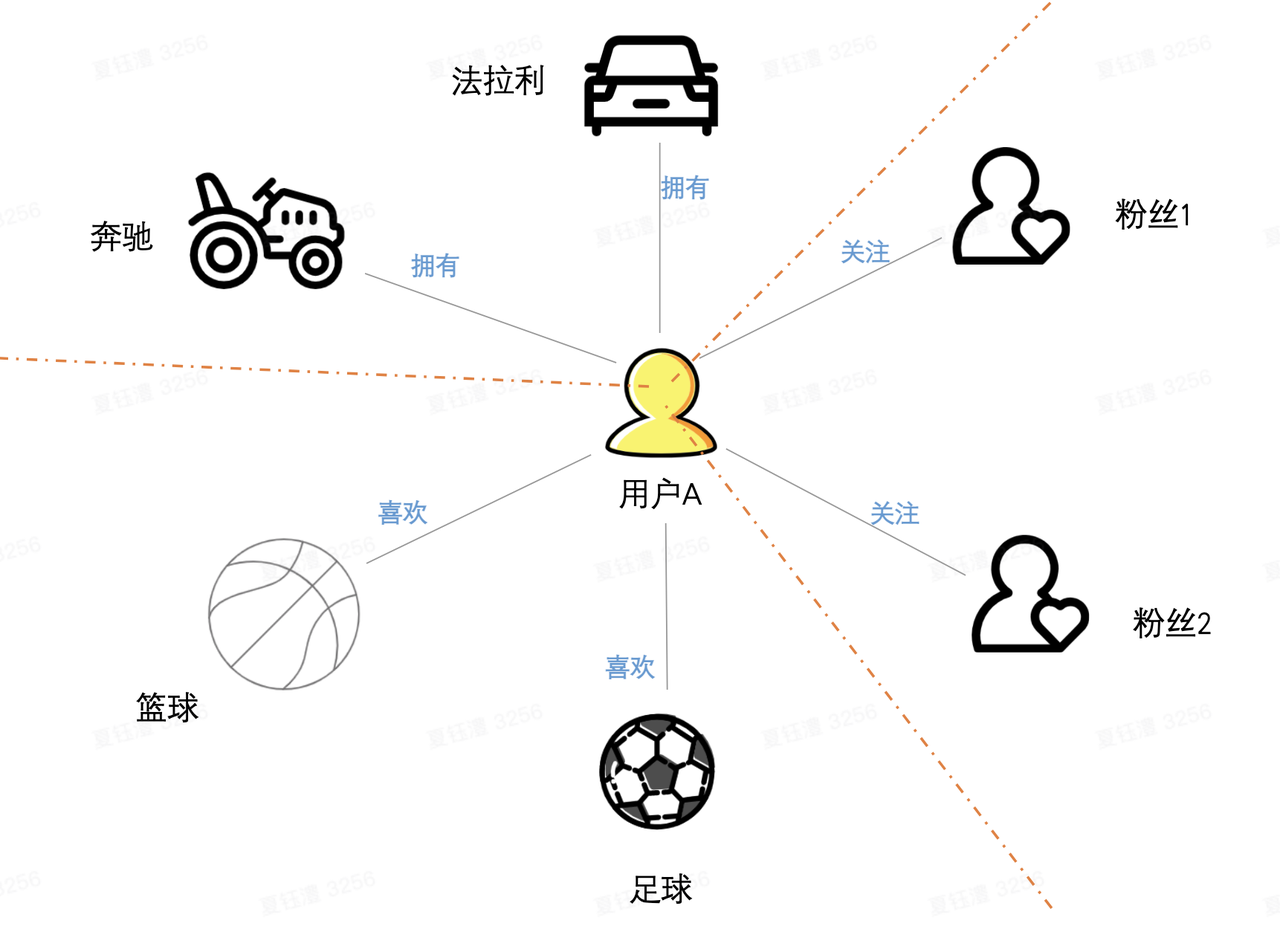
ByteGraph采用「点切法」划分出不同的「partition」,然后按照一定的策略将「partition」划分到不同的GS实例中。如图中用户A和建立用户A与奔驰、法拉利“拥有”关系的两条出边构成了一个「partition」。
Partition组织架构(一个GS实例):
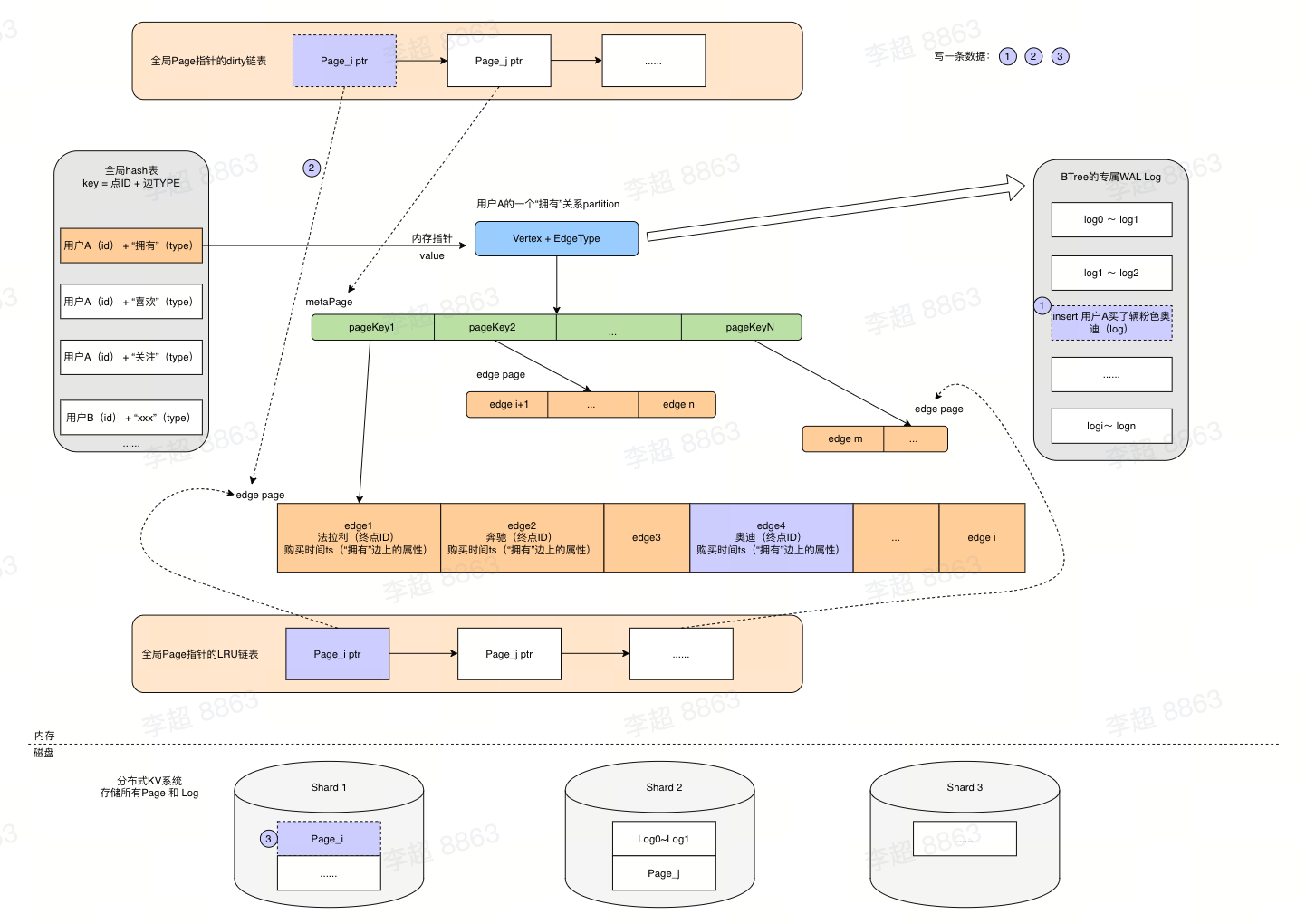
- 全局hash表: 全局hash表中,key可以理解为「顶点ID」➕「边TYPE」构成的一个唯一值,value则指向一个「partition」,实现了确定某个点后快速检索定位对应「partition」的能力。
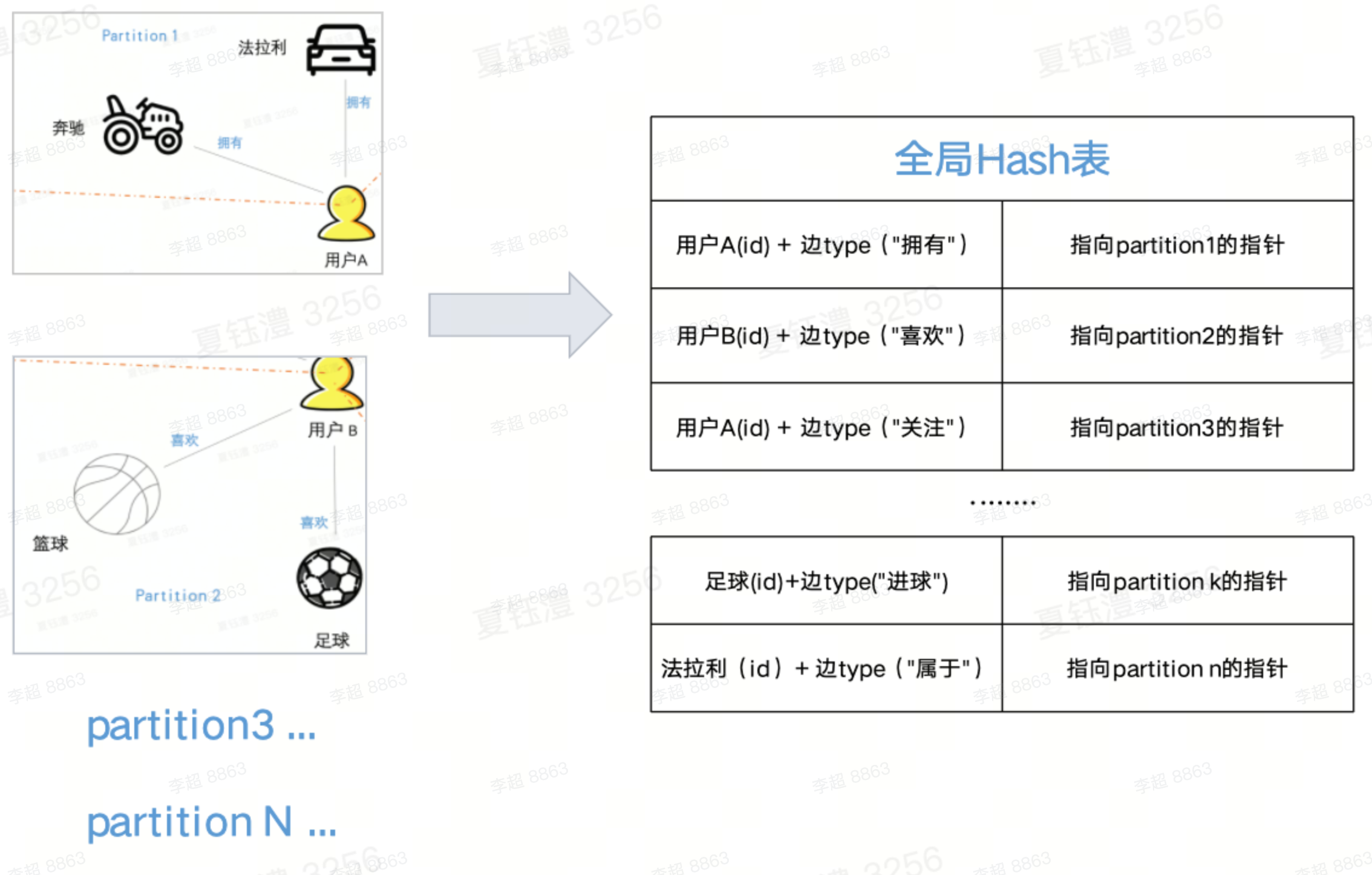
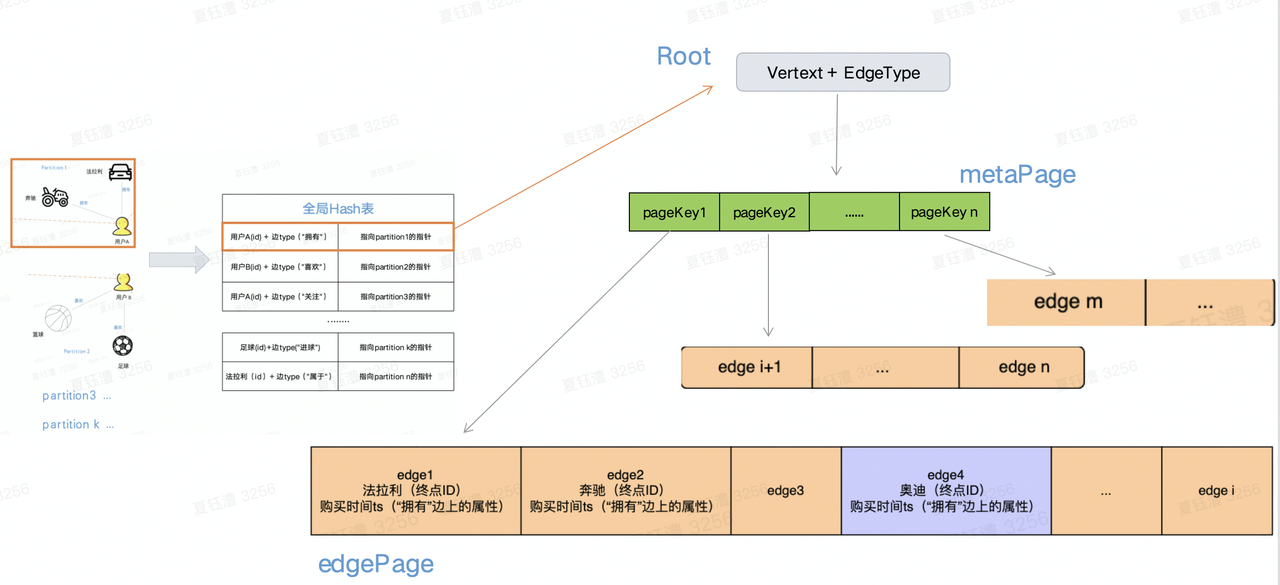
- Partition: 在内存中「partition」被组织为BTree的模式,通过「全局hash表」的指针定位到具体的Btree,其中Btree的根节点和叶子节点在内存中被组织为「Page」的模式,具体包括以下page:
- 「metaPage」: 非叶子节点,存储指向子节点的内存指针,作为BTree的索引节点
- 「edgePage」: 叶子节点,存储边数据(终点ID➕边上的属性),每个page存储边的数量可供配置
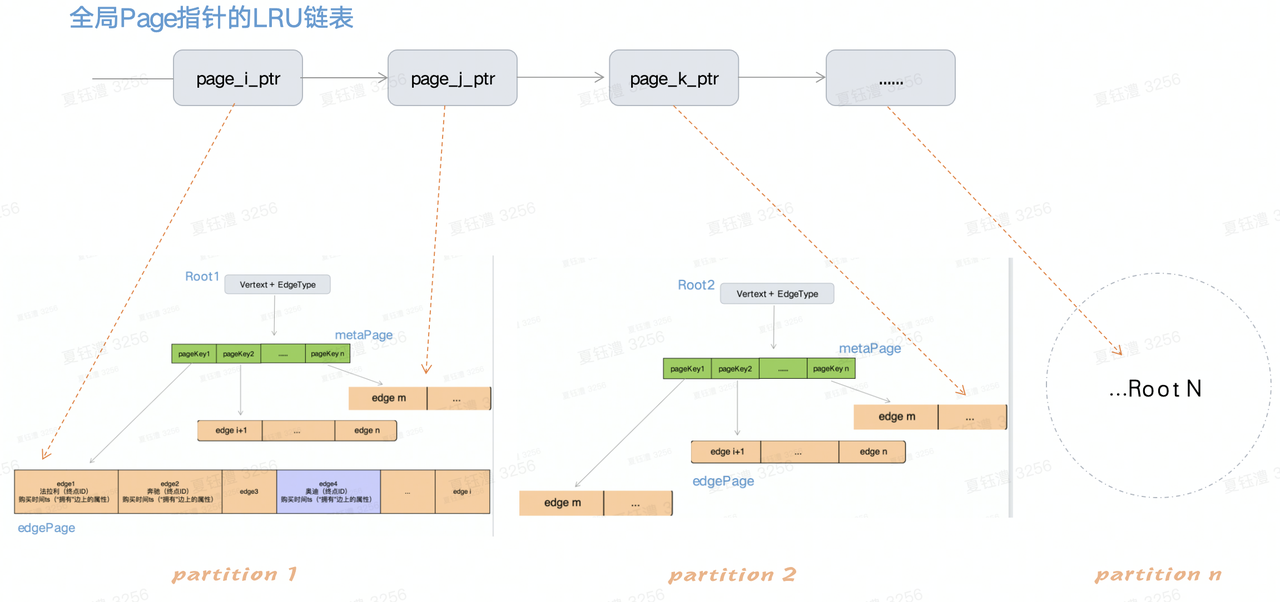
- 全局LUR链表: 全局LRU链表中存放指向「Page」的指针,「Page」分布于每一个「partition」的Btree结构中。其中「Page」按需加载到内存,全局LRU链表对解决数据的冷热沉降非常实用。非热点数据直接存放于磁盘,热点数据常驻内存。
-
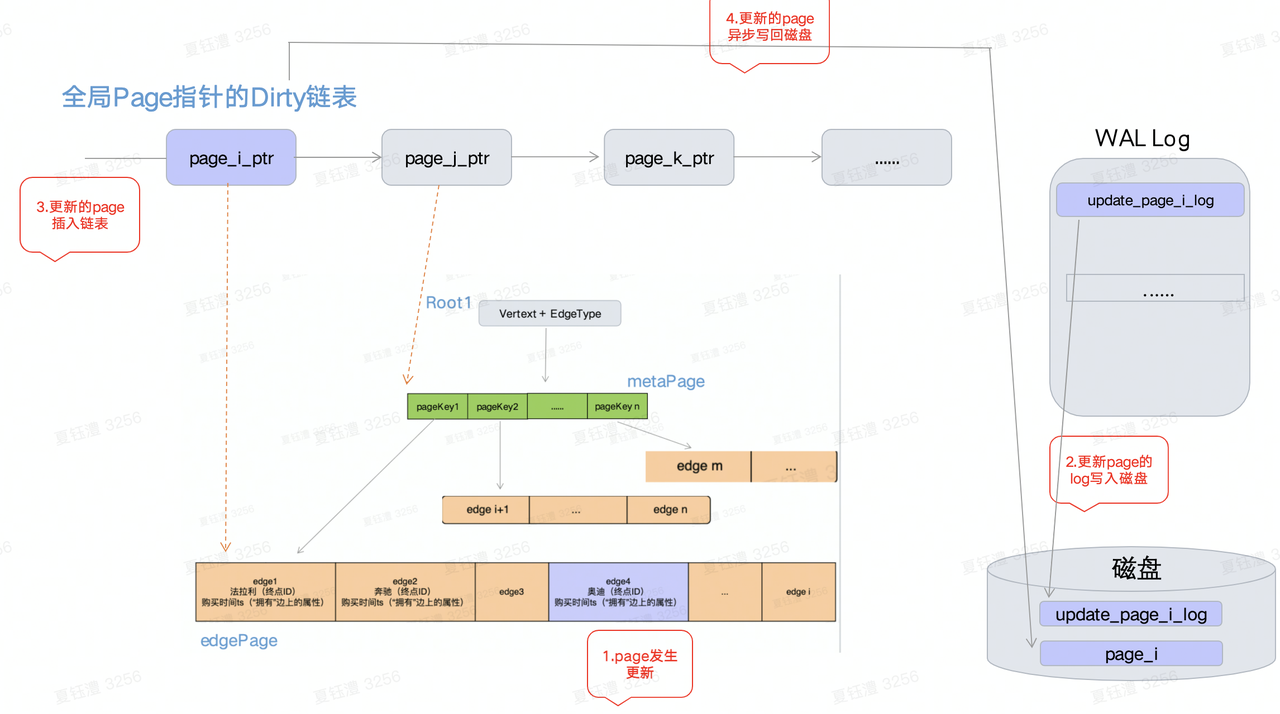
全局dirty链表: 全局链表中存放指向「Page」的指针,「Page」分布于每一个「partition」的Btree结构中。「dirty」链表中存放的是刚刚被修改的「Page」指针,在数据发生修改的过程中会经历4步如图。内存中的「page」与磁盘中的「page」数据采用异步方式同步,会出现数据不一致的现象,对于同一个「page」的多次写可以一次i/o完成。
-
WAL Log: 每个「Partition」/Btree都维护自己的一个WAL log(redo log), 每次写入搭配全局Dirty链表可以实现与磁盘的异步交互。若干条 log会聚合成一个类似「Page」的结构便于磁盘统一存储
-
分布式KV系统(磁盘): 在ByteGraph中,「partition」的各个结构,BTree、WAL Log等都被组织为「Page」的模式,底层的磁盘也正是按照这种「Page」的组织方式来存放数据。目前底层磁盘采用现有而且比较成熟的分布式基建(Abase/ByteKV)。
索引问题
对于索引结构背后的基本想法都是保留一些额外的元数据,这些元数据作为路标,帮助定位想要的数据。如果希望用几种不同的方式搜索相同的数据,在数据的不同部分,可能定义多种不同的索引。
边上属性的索引
边上的索引最为直观的表现是根据边上的属性有效快速检索需要的边或的定点。而在检索的过程中基于partition划分子图的模式又分为局部检索和全局检索
局部索引
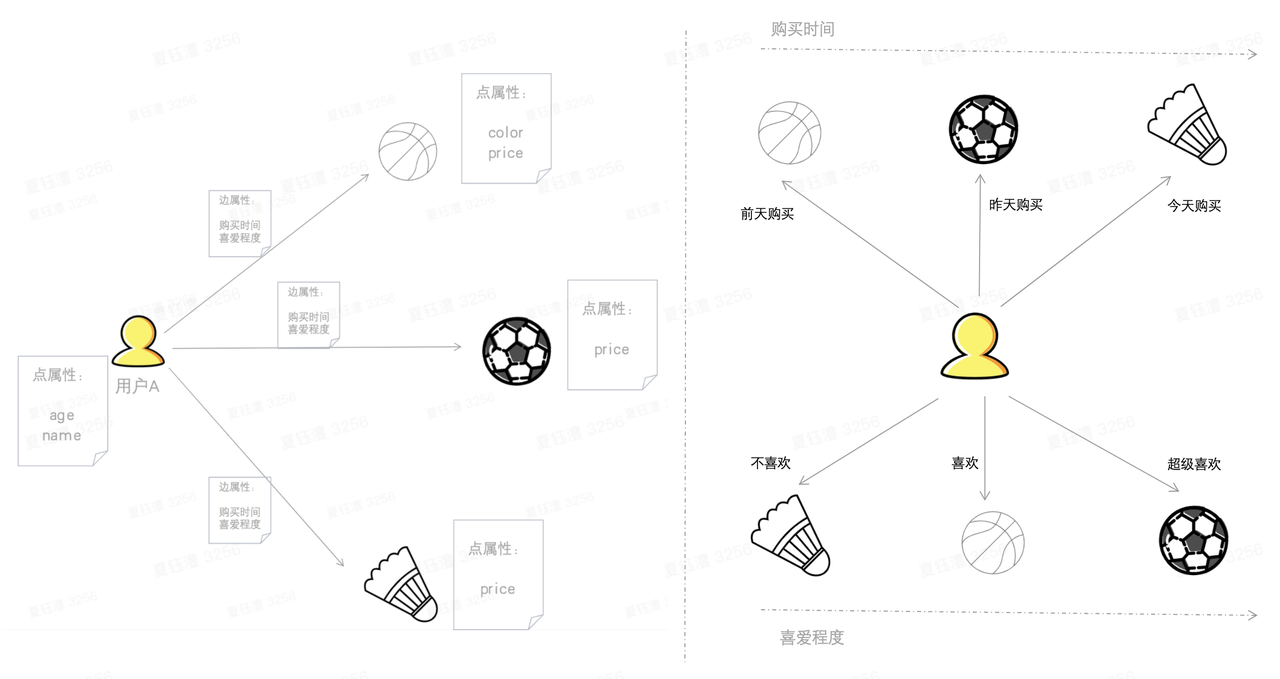
局部索引限定了一个范围,把检索的数据确定在一个partition中。按照partition内存组织模式(BTree),当一个起点具备多条出边的时候,图上的一跳查询在建立了局部索引后性能上可以获得巨大提升
- 支持边上某个属性的有序索引
- 支持指定属性范围查找边
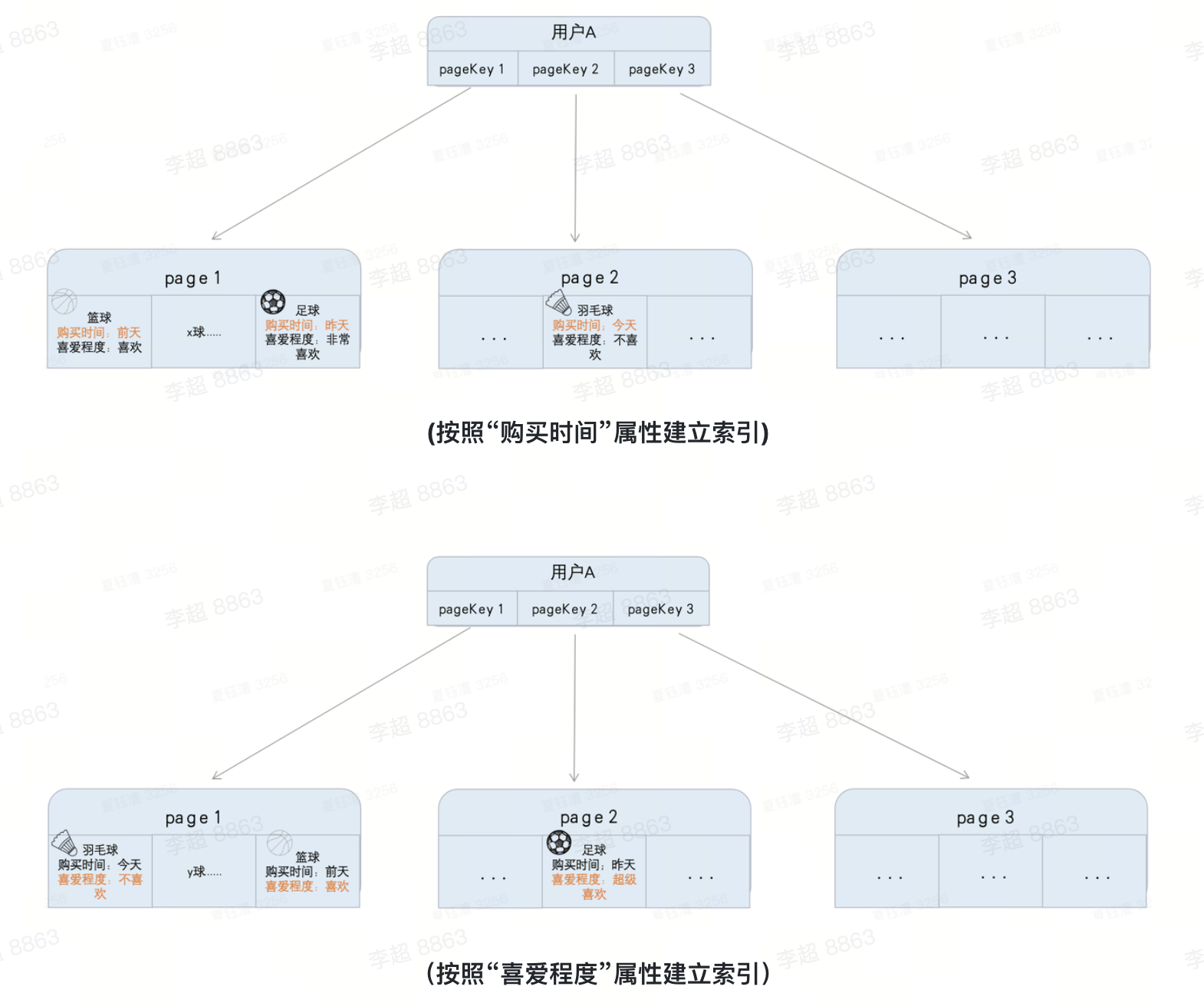
如果在建图的时刻仅仅默认构建了“购买时间”属性索引,没有构建“喜爱程度”属性索引
- 按照“购买时间”序拉取一个球类列表,可以走“购买时间”属性索引,局部Btree的logn复杂度
- 按照“喜爱程度”序拉取一个球类列表,由于没有构建“喜爱程度”属性索引,所以需要遍历整个Btree
全局索引
全局边的搜索涉及跨Partition的复杂检索,同时数据规模庞大以及基于性能的考虑暂不支持基于边属性的全局索引
点上属性的索引
点上的索引较为直观的应用是基于某些属性值反向查找到相关的点列表,涉及的检索模式为全局检索。点的属性索引采用BTree格式存储,索引树的大小与整个图中点的数量规模一致。
小结
索引是基于原始数据派生而来的额外数据结构,很多数据库允许单独添加和删除索引,而不影响数据库的内容,它只会影响查询性能。维护额外的结构势必会引入开销特别是在新数据写入时,对于写入很难通过简单的追加文件方式来实现,任何类型的索引都会影响写的速度。