RocksDB是Facebook在Google开源key-value存储LevelDB的基础上开发而来的单机存储引擎。LevelDB是一个精简基于LSM tree的数据库,而RocksDB在LevelDB的基础上进行了大量的优化和功能的添加,比如将LevelDB的单线程compaction改成多线程compaction,提高写入效率;实现了事务的功能,引入了列簇(column family)的概念。
主要解决写多读少的写密集型场景的性能问题,牺牲部分读性能来加速写性能;
LSM
LSM Tree(Log-Structured Merge-Tree)不是一个数据结构,而是一种数据存储引擎的设计思想和算法,主要为了提升写多读少场景下的性能。
LSM Tree提升写性能的关键点在于将所有的写操作都变成顺序写,避免随机IO。核心思想就是异步对数据做合并、压缩,维护数据的有序性。
整体架构
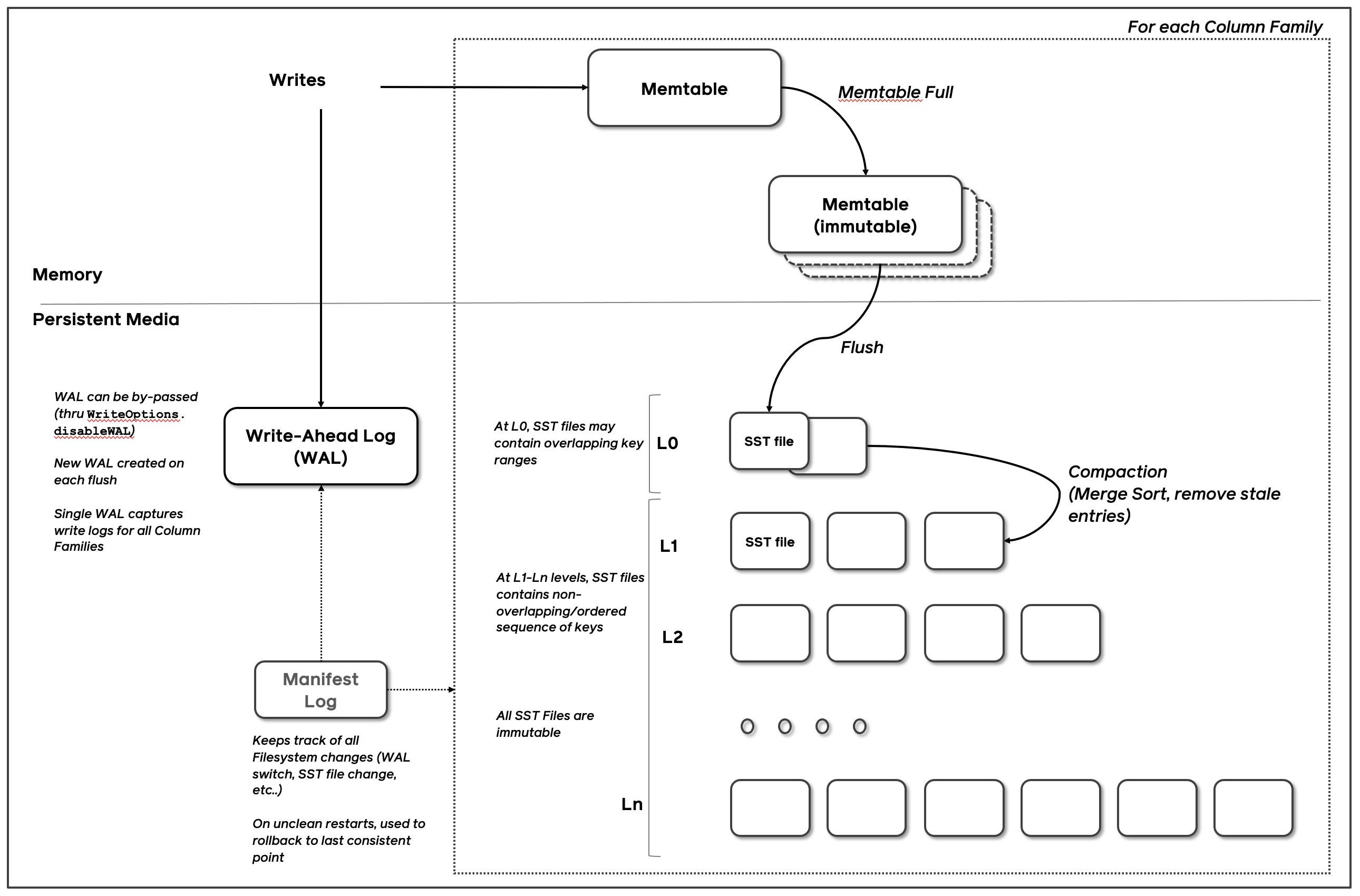
分级缓存的设计思想,越是上层的数据,修改时间越近,否则数据会逐渐下沉到最下层。
为什么不能只有两层?为了提高 Compaction 效率。假设 LevelDB 只有 2 层( 0 层和 1 层),那么时间一长,1 层肯定会累计大量的文件。当 0 层的文件需要下沉时,也就是 Major Compaction 要来了,假设只下沉一个 0 层文件,它不是简简单单地将文件元信息的层数从 0 改成 1 就可以了。它需要继续保持 1 层文件的有序性,每个文件中的 Key 取值范围要保持没有重叠。它不能直接将 0 层文件中的键值对分散插入或者追加到 1 层的所有文件中,因为 sst 文件是紧凑存储的,插入操作肯定涉及到磁盘块的移动。再说还有删除操作,它需要干掉 1 层文件中的某些已删除的键值对,避免它们持续占用空间。
为什么每层都分为多个小的文件?如果是单个文件,那么数据的合并压缩效率会很低,而且会影响读写的性能。多层的文件结构提供了写压力的“缓冲”能力。
如何进一步提升效率?每个小文件中的数据保持有序,利用多路归并的思想合并,提高合并效率。同时每个文件构建索引、Bloom Filter,提高查询效率。
产生的问题:
- 读放大:数据可能存在Memtable,immutable memtable,以及多层SST File中,所以一次读可能放大为多次数据查找(多层SST File的数据是存在重叠冗余的);
- 写放大:写放大主要是由Compaction引入的;
- 空间放大:数据在多层之间是冗余的,同时WAL日志也会占用一定的空间;
Memtable
数据在内存中的结构,分为memtable和immutable memtable,其中memtable为读写结构,当memtable增长到一定大小的时候就会变成immutable memtable,只读不写;
memtable 和 immutable memtable 的数据结构是一样的,其中LevelDB只支持一个immutable memtable,RocksDB在此基础上做了优化,支持多个immutable memtable,提高写入性能。
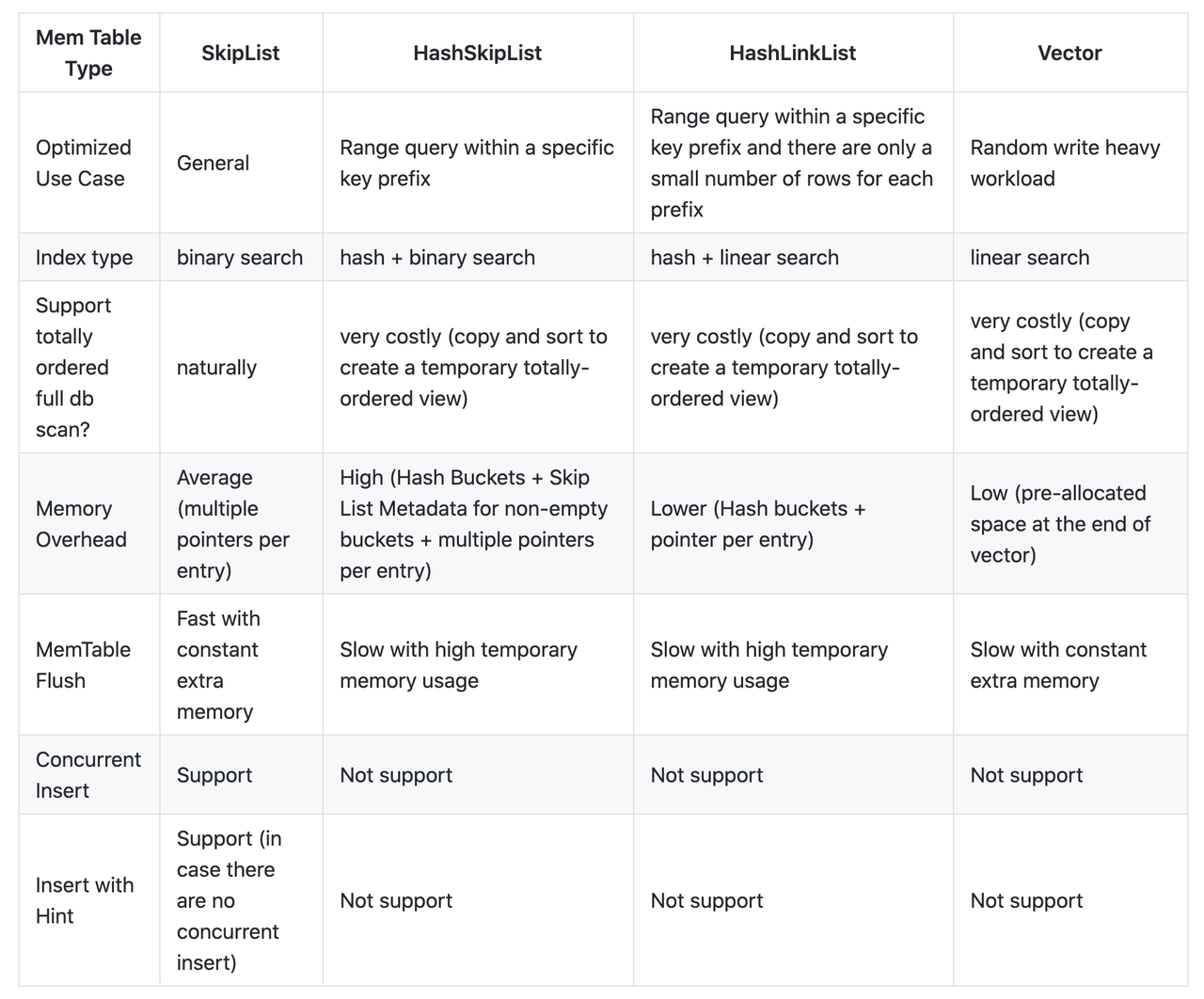
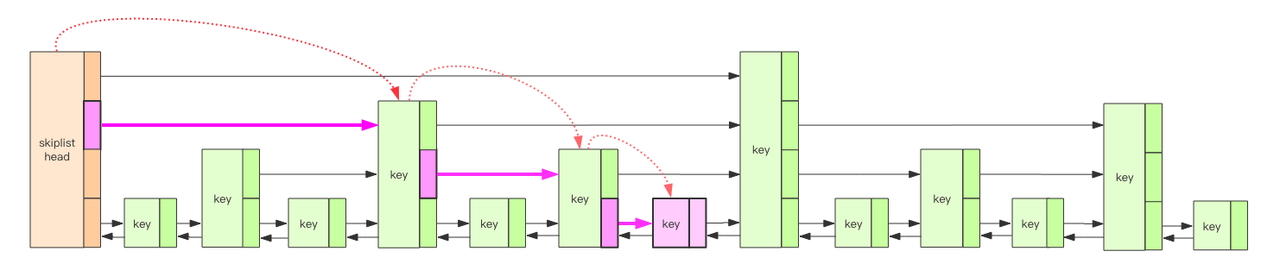
RockDB 默认使用跳表作为 memtable 的数据结构,跳表在读、写、范围查询、支持无锁并发方面都有较好的性能
WAL log
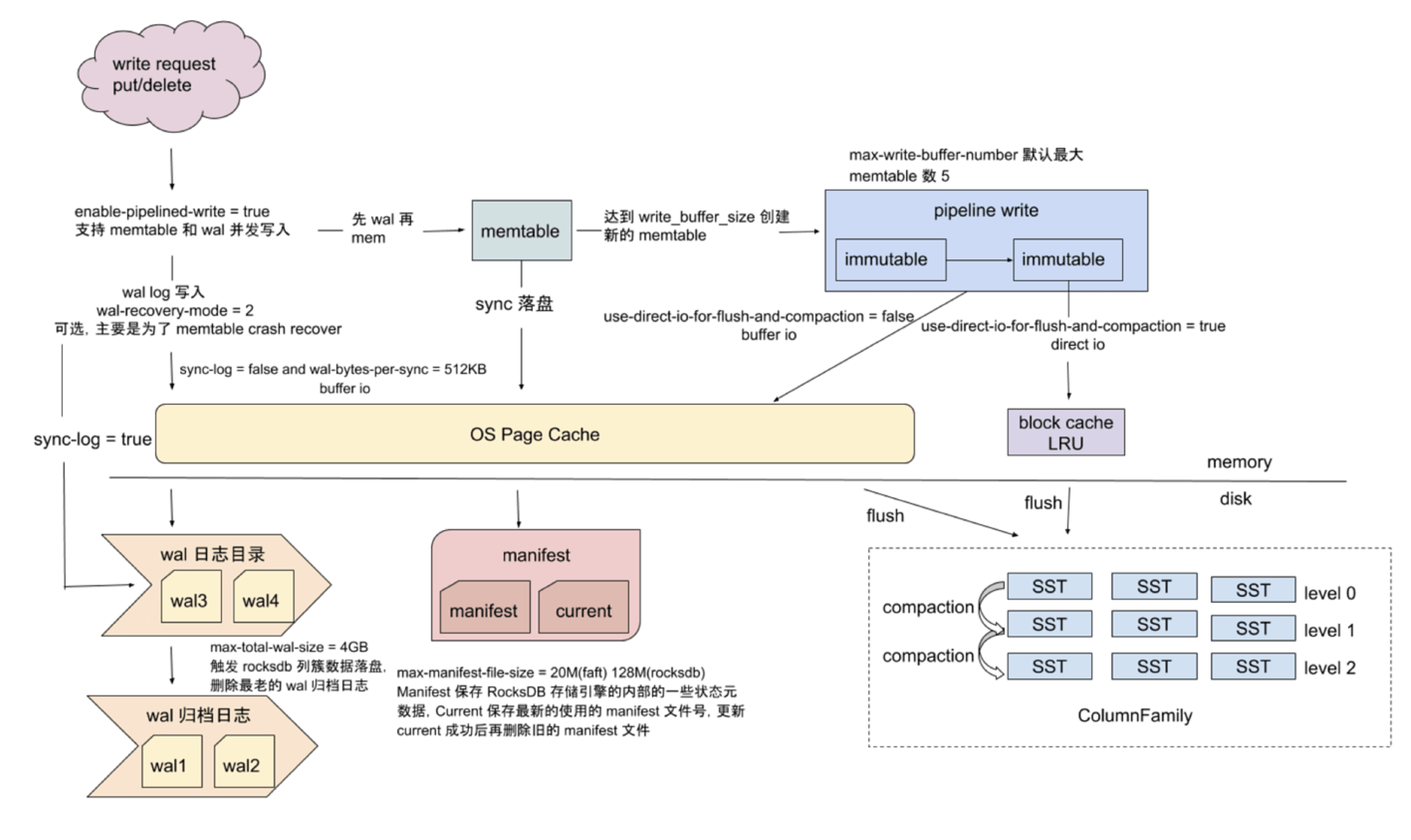
RocksDB 写入一个 Record 时,都会先向日志里写入一条记录,这种日志一般称为 Write Ahead Log,类似于 MySQL 的 Redo Log。这种日志最大的作用就是将对磁盘的随机写转换成了顺序写。当故障宕机时,可以通过 Write Ahead Log 进行故障恢复。控制每次写入磁盘的方式,可以控制最多可能丢失的数据量。如果全部数据刷入 SST File,Write Ahead Log 文件就会删除。
故障恢复级别:
故障恢复级别定义了 RocksDB 故障重启后,对未提交的数据的恢复策略。故障重启以后,日志文件可能不完整,读取的时候会产生错误,故障恢复级别就是针对这些错误所采取的不同策略。
- kTolerateCorruptedTailRecords:忽略一些在末尾写入失败的请求,数据异常仅限于log文件末尾写入失败。如果出现了其他的异常,都无法进行数据重放
- kAbsoluteConsistency:对一致性要求最高的级别,不允许有任何的 IO 错误,不能出现一个record的丢失
- kPointInTimeRecovery:默认的 mode,当遇到 IO 错误的时候会停止重放,将出现异常之前的所有数据进行完成重放
- kSkipAnyCorruptedRecords:一致性要求最低的,会忽略所有的 IO error,尝试尽可能多得恢复数据
SST File
Sorted String Table File 数据按照key有序存储后,在磁盘上最终存储为SST File,通过Compaction来维护每层数据,其中最下面一层存储全量数据。 在磁盘上的文件分为多个level,其中level 0是特殊的,它包含了刚刚被flush的Memtable,因此存在level 0中的数据会比其他level更新。此外,Level 0的各文件之间并不是有序的,而其他Level中的各个SST File间是有序的。
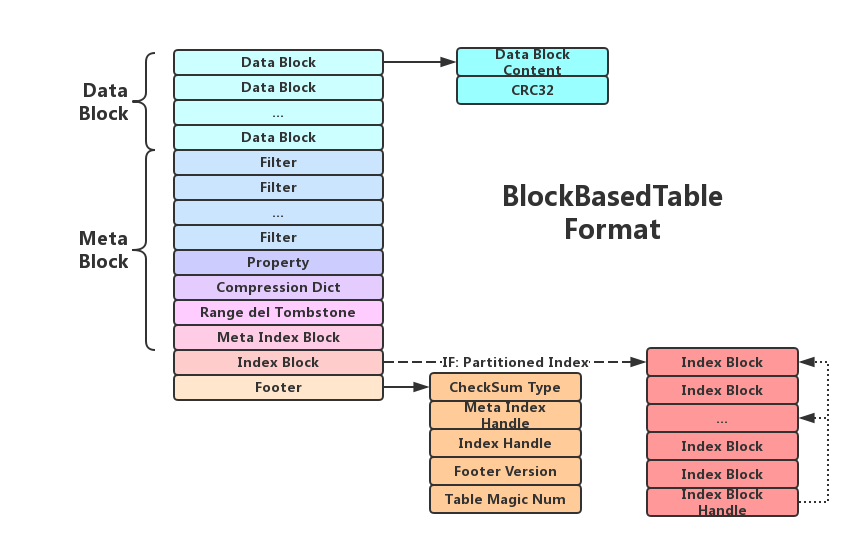
- 内置布隆过滤器
- 每个文件记录最小key和最大key
- DataBlock: 主要用来存放key和value

- MetaBlock: 存放关于key-value的元信息,包含index block、 filter block、range_del block,compression block,properties block等几种。
- filter block:用来保存一些bloom filter用来加速查找,可以挡住一部分无效查询
- Compression Dict meta Block:这个block是字典压缩block,这个部分的是为了节约datablock/filterblock/indexblock的存储空间而 设置的一个针对key的字典压缩后的数据存放区域。大多数情况下,只有当key-value数据写入到了最后一层的时候才会开始进行压缩
- range_del block:用于标识被批量删除前缀key的数据
- properties block:保存了一些当前SST文件的属性信息,同时也包括其他的各个block属性数据,例如有多少个datablock,index block,SST文件大小等各个维度的数据
- MetaIndex Block:key是filter的名称,主要用来存放meta block的索引,这个索引是由block的偏移量和大小组成。
- Index Block:key是对应块的最大key,value用来存放data block的索引,这个索引是由block的偏移量和大小组成。
- footer:主要是用来索引 meta index block 和 index block
Cache
table cache缓存的是sstable的索引数据,类似于文件系统中对inode的缓存。每个sst文件打开是一个TableReader对象,它会缓存在table_cache中。key值是SSTable的文件名称,Value部分包含两部分,一个是指向磁盘打开的SSTable文件的文件指针,这是为了方便读取内容;另外一个保存了SSTable的index内容以及用来指示block cache用的cache_id 。 Block Cache 是 RocksDB 的数据的缓存,这个缓存可以在多个 RocksDB 的实例下缓存。一般默认的Block Cache 中存储的值是未压缩的,而用户可以再指定一个 Block Cache,里面的数据可以是压缩的。用户访问数据先访问默认的 Block Cache,待无法获取后再访问用户 Cache,用户 Cache 的数据可以直接存入 page cache 中。 Cache 有两种:LRUCache 和 ClockCache。
核心流程
写入流程
由于有后台合并操作,所以常规写入的流程比较简单,主要有以下特点:
- 先写 WAL 再写 memery
- 内存支持并发写入
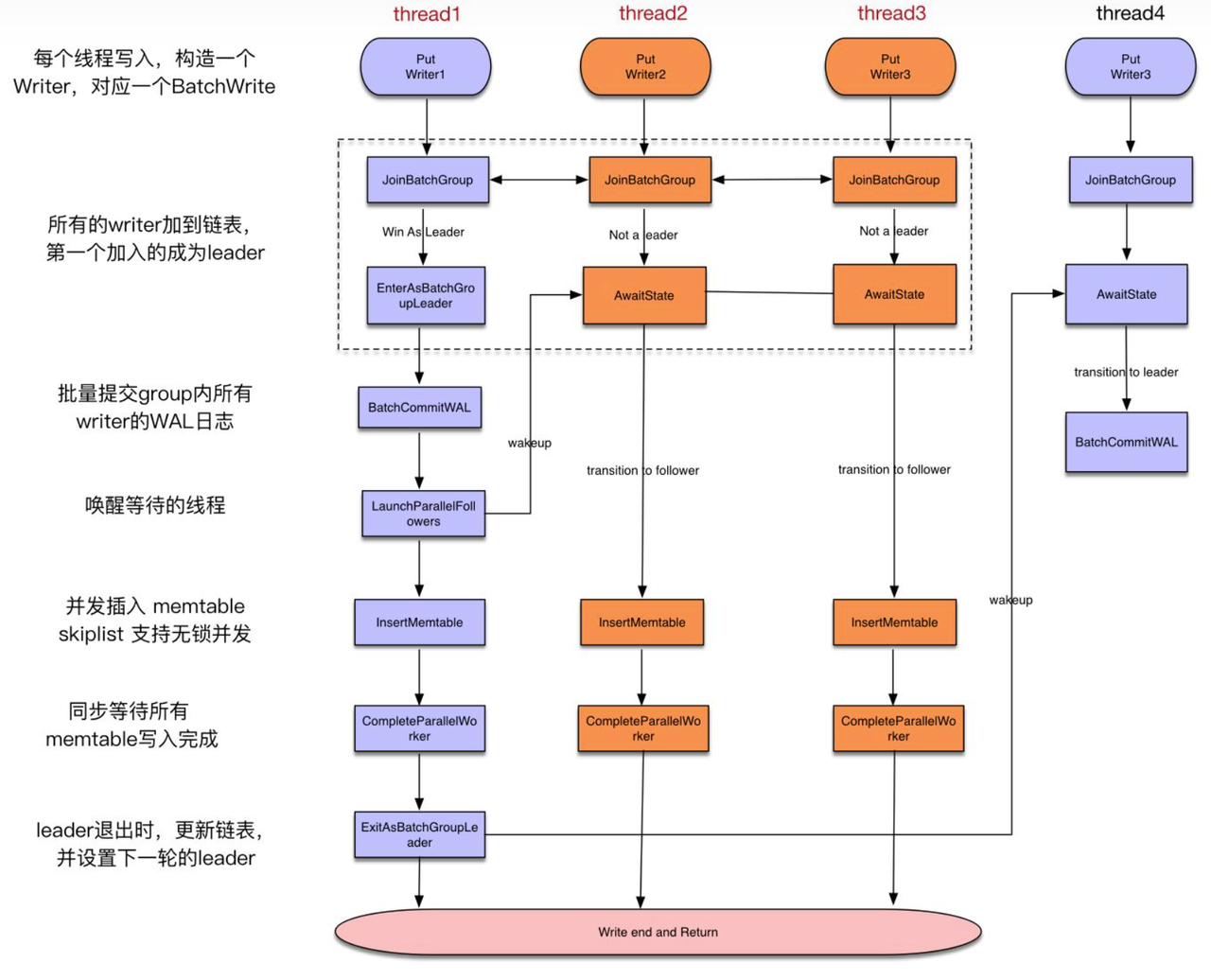
- Group Commit,类似 Innodb 的 Group Commit
Group Commit 机制
读取流程
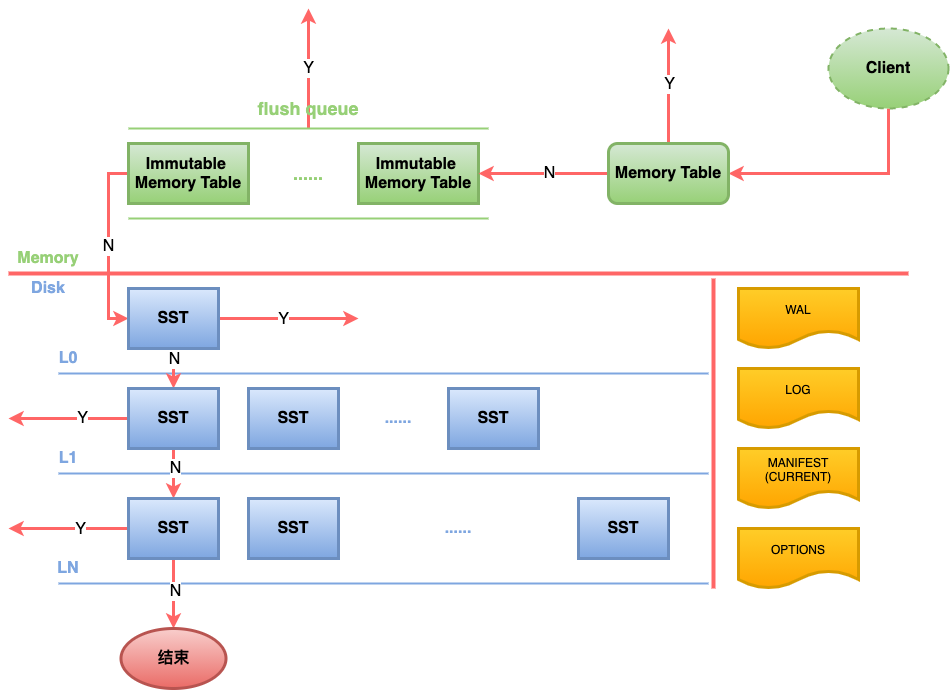
- 查询Memtable和Immutable,利用布隆过滤器加速
- 遍历L0层所有SST文件查询
- 对于非L0层,先确定本层需要查询的文件范围
- 对于每个非L0层的文件,采用二分查询查找
数据库中的读可分为当前读和快照读,所谓当前读,就是读取记录的最新版本数据,而快照读就是读指定版本的数据。
版本链
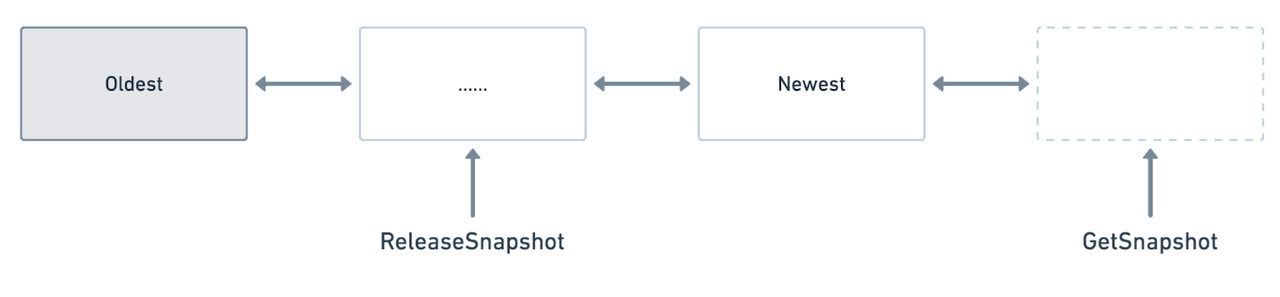
通过一个全局双向链表,维护当前 DB 中的版本链。和 B+树对比,由于 B+树的 in-place update 特性,所以需要通过 undo log 来记录版本;RocksDB 依靠其天然的 AppendOnly 特性,所有的写操作都是后期 merge,自然地就是 key 的多版本,所以实现 MVCC 更加方便。
隔离级别
RocksDB 实现了 ReadCommited 和 RepeatableRead 隔离级别
需要读取比某个 lsn 小的历史版本,只需要在读取时指定一个带有这个 lsn 的 snapshot,即可读到历史版本。所以,在需要一致性非锁定读读取操作时,默认 ReadCommited 只需要按照当前系统中最大的 lsn 读取(这个也是默认 DB::Get() 的行为),即可读到已经提交的最新记录(提交到 memtable后的记录一定是已经 commit 的记录,未 commit 之前记录保存在 transaction 的临时 buffer 里)。在 RepeatableRead 下读数据时,需要指定该事务的读上界(即创建事务时的 snapshot(lsn) 或通过 SetSnapshot 指定的当时的 lsn),已提交的数据一定大于该 snapshot(lsn),即可实现可重复读。
合并(Compaction)
Compaction 时机包括:
- 后台线程定期执行
- L0 层文件数达到阈值
- 非 L0 层文件总大小超过阈值
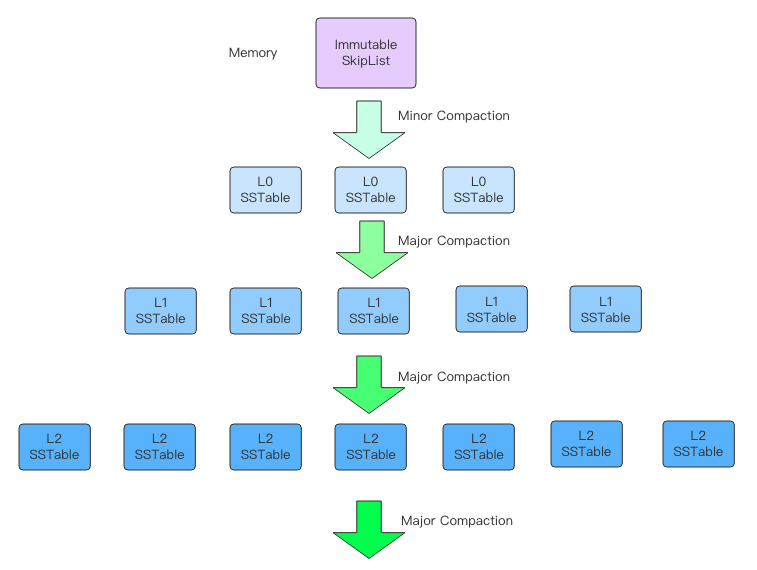
L0层:
Minor Compaction做的事就是将Immutable完整地序列化成一个L0层的文件,速度快,耗费资源少。
因为是按照时间对Immutable的序列化,所以L0层的文件之间key是非有序的,查询的时候需要遍历全部文件。L0层文件不能太多,否则会影响查询效率。
非L0层:
每个文件内部数据有序,文件之间数据有序。
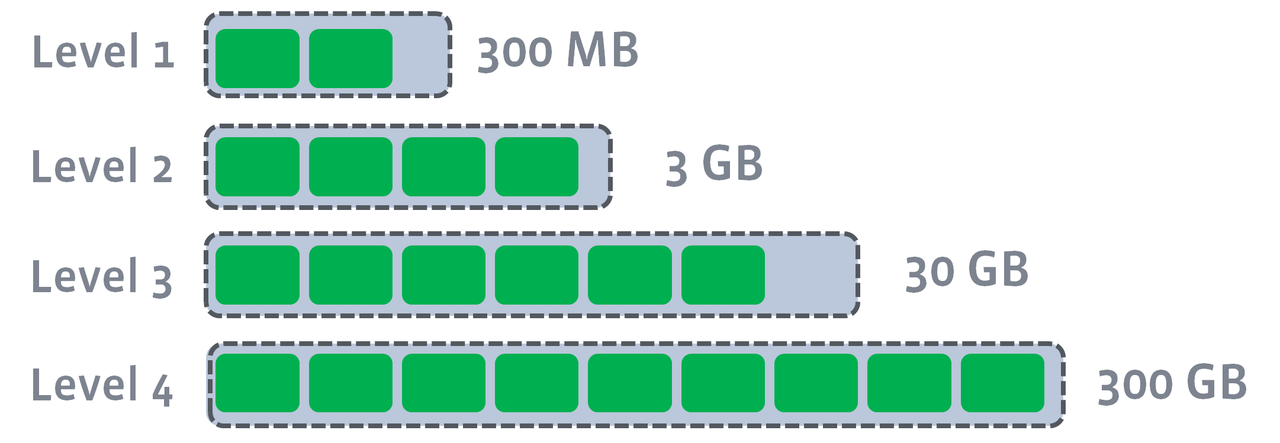
Major Compaction 涉及到多个文件之间的合并操作,耗费资源多,速度慢。层级越深的文件总容量越大
Paralleled Compact:
多层 Compaction 可以并行处理,提升性能
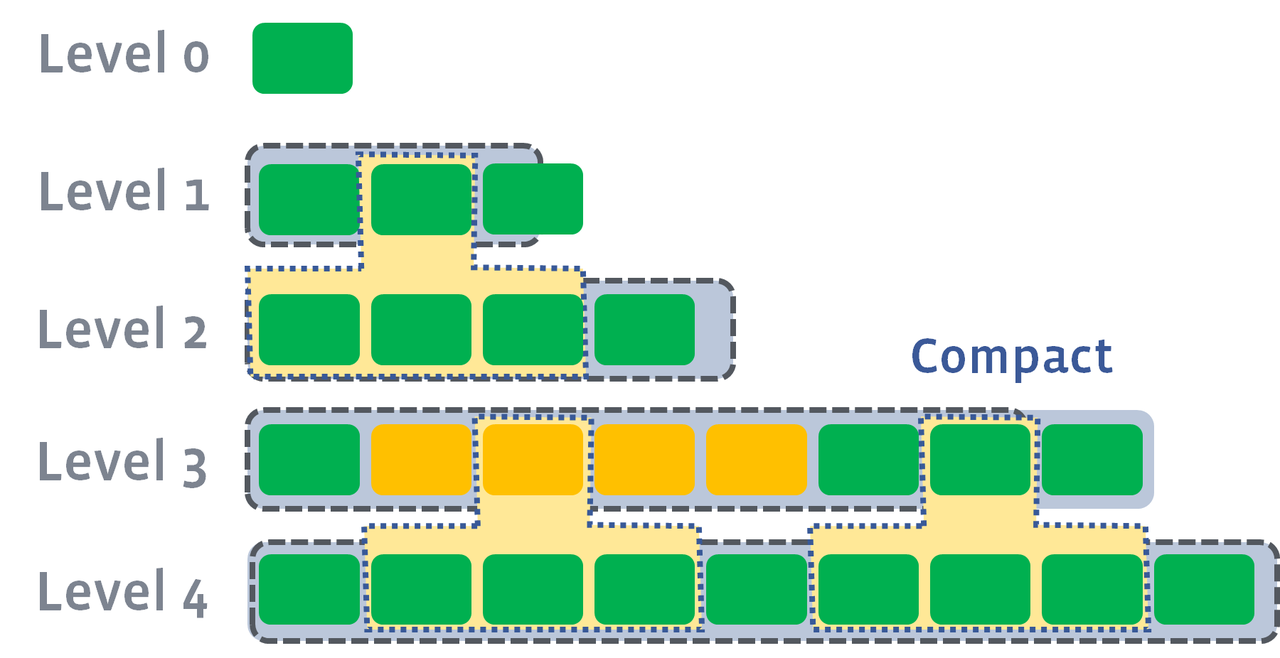
L0到 L1 层的 compaction 默认不并行处理,可以通过 sub-compact 加快速度。
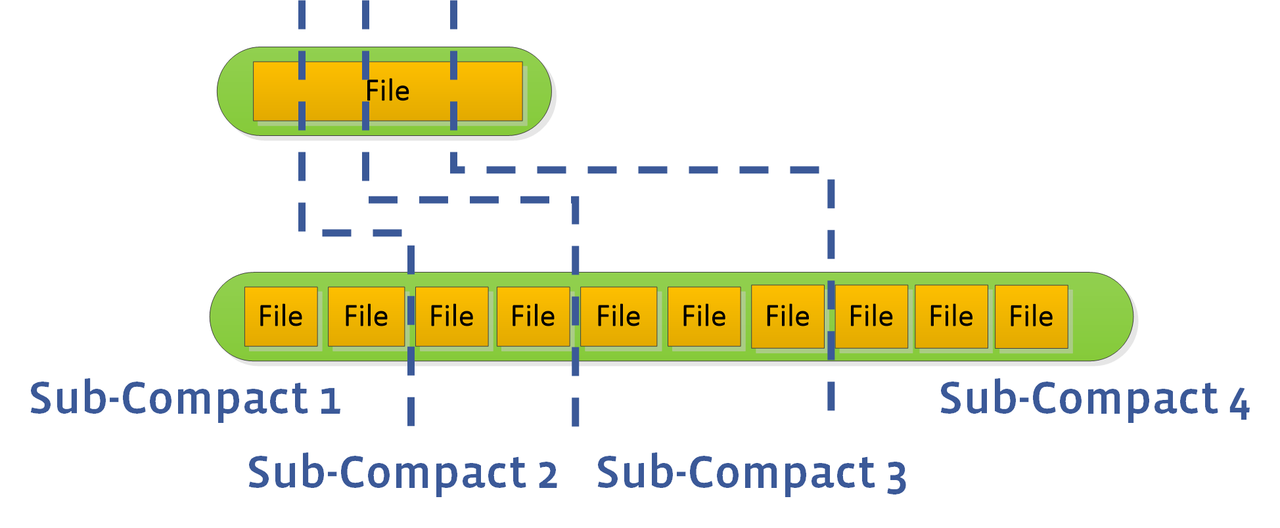
Tombstone(墓碑)
RocksDB 的删除操作其实只是写入了一个 tombstone 标记,而这个标记往往只有被 compact 到最底层才能被丢掉。为什么不直接删除呢?因为数据在多层之间存在重叠,删除的话非常消耗资源。
数据的频繁 update 会在 SST 文件中产生较多的“墓碑”数据。
压缩
默认采取两种比较轻量级的压缩算法。可以为每层定制压缩算法,参数:options.compression_per_level