Paxos算法是Lamport提出的一种基于消息传递的分布式一致性算法。
其中提出了一个问题:
在古希腊有一个叫做Paxos的小岛,岛上采用议会的形式来通过法令,议会中的议员通过信使进行消息的传递。值得注意的是,议员和信使都是兼职的,议员随时有可能会离开议会厅,并且信使可能会重复的传递消息,也可能一去不复返。因此,议会协议要保证在这种情况下法令仍然能够正确的产生,并且不会出现冲突。
Paxos算法不是为了解决拜占庭将军问题的。 首先,拜占庭将军问题描述的是从理论上来说,在分布式计算领域,试图在异步系统和不可靠的通道上来达到一致性状态是不可能的。 因此在对一致性的研究过程中,都往往假设信道是可靠的。
- 在工程实践中,大多数系统都是部署在同一个局域网中的,因此消息被篡改的情况非常罕见;
- 另一方面,由于硬件和网络原因而造成的消息不完整问题,只需要通过简单的校验算法即可避免。 因此,在实际工程实践中,可以假设不存在拜占庭将军问题,也就是说可以假设所有消息都是完整的,没有被篡改。 而Paxos算法是基于没有拜占庭问题的假设下进行的。
算法流程
三种角色
Paxos将系统中的角色分为提议者 (Proposer),接受者 (Acceptor),和学习者 (Learner),它们之间的关系如下:
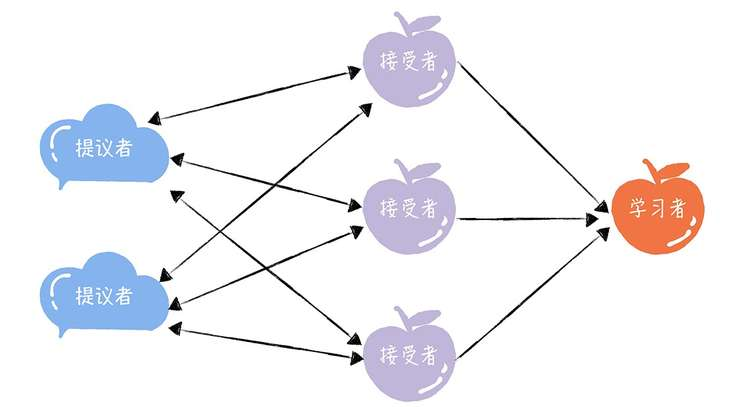
- 提议者 (Proposer):提议一个值,用于投票表决。在绝大多数场景中,集群中收到客户端请求的节点,就是提议者。
- 接受者 (Acceptor):对每个提议的值进行投票,并存储接受的值。一般来说,集群中的所有节点都在扮演接受者的角色,参与共识协商,并接受和存储数据。
- 学习者 (Learner):被告知投票的结果,接受达成共识的值,存储保存,不参与投票的过程,一般来说,学习者是数据备份节点,比如“Master-Slave”模型中的Slave,被动地接受数据,容灾备份。
系统中的节点可以身兼多个角色。
针对这三种角色,本质上代表的是三种功能:
- 提议者代表接入和协调功能,收到客户端请求后,发起二阶段提交,进行共识协商
- 接受者代表投票协商和存储数据,对提议的值进行投票,并接受达成共识的值,存储数据;
- 学习者代表存储数据,不参与共识协商,只接受达成共识的值,存储保存。
Basic Paxos
Paxos分准备阶段和批准阶段两个阶段完成,每个阶段后还需要判断该阶段的结果是否有效是否需要重来,另外需要注意提案编号全局递增且唯一。 注意:Basic Paxos只用于单值的共识,一旦这个值确定之后就不会再发生变化了。因此,在工程中是不会使用这个算法的,该算法一般用于科学研究。
算法步骤:
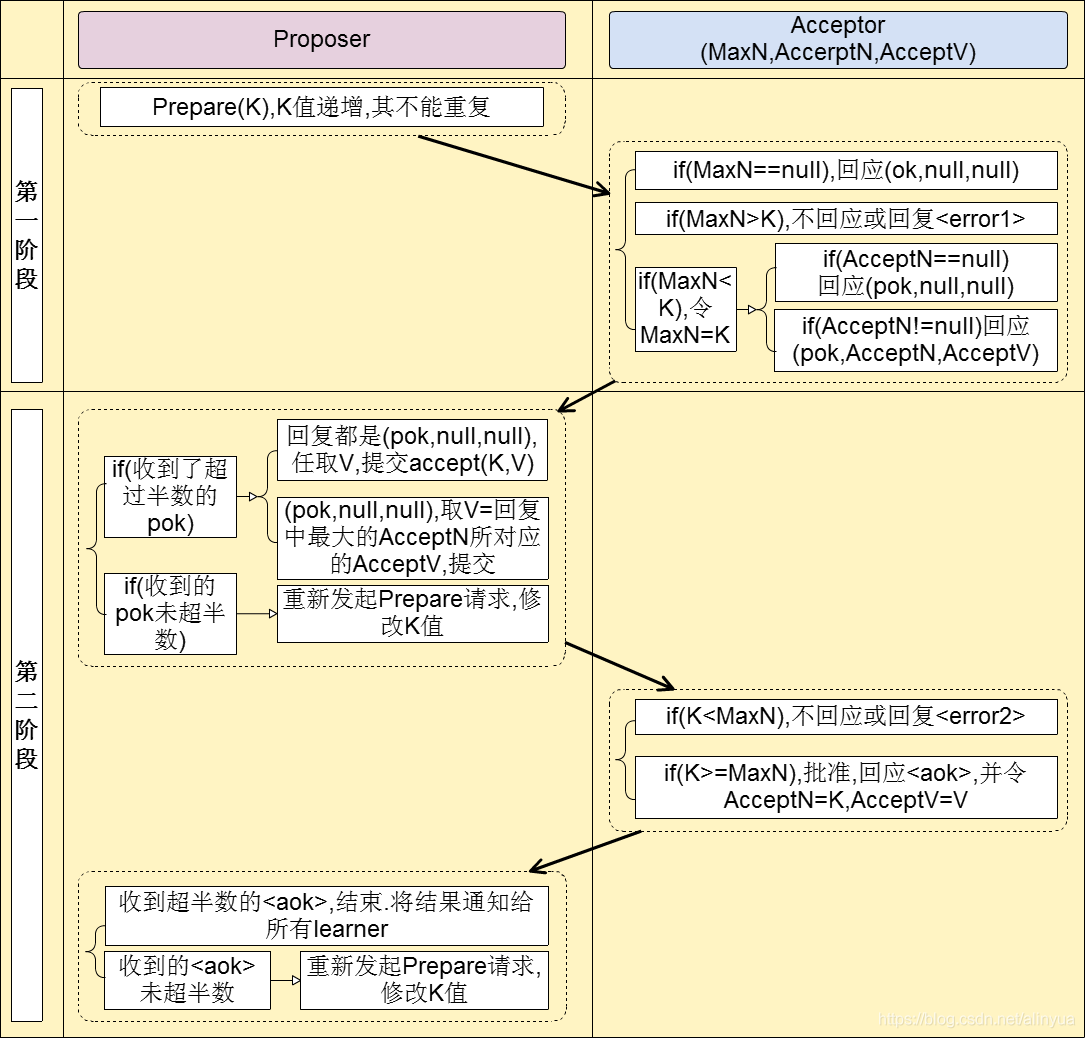
- 阶段一:prepare准备阶段(只需携带提案ID)
- 获取一个提案ID->K,为了保证提案ID唯一并且是递增的,可采用时间戳+Server ID生成;
- Proposer向所有Acceptors广播Prepare(K)请求;
- Acceptor收到Prepare请求会有以下三种情况:
- 情况1:Acceptor从未承诺(promise)过提案(即MaxNet==null),Acceptor记录最大提案编号MaxN为K,回应 ok
- 情况2:提案编号K < Acceptor的最大提案编号MaxN,不回应或回应错误提醒
- 情况3:提案编号K > Acceptor的最大提案编号MaxN,Acceptor记录最大提案编号MaxN为K,回应ok。如果已经接受过提案,则将接受过的提案编号和值(AcceptN和AcceptV)一并回复
- 如果Proposer收到超过半数的ok,则进入批准阶段,否则重新回到准备阶段
-
阶段二:批准阶段(携带提案ID和值)
- Proposer向所有回复ok的Acceptor发送accept请求,包括编号K和上一阶段拿到的最大的AcceptN 所对应的 AcceptV(如果没有已经接受的value,那么它可以自由决定value)。
- Acceptor收到accept请求,会有以下两种情况:
- 情况1:提案编号K < Acceptor的最大提案编号 MaxN,不回应或回应错误提醒
- 情况2:提案编号K >= Acceptor的最大提案编号 MaxN,批准请求,回应 ok,记录AcceptN=K,AcceptV=value(如果之前已经有AcceptN和AcceptV,这个时候也会覆盖!)
- 如果Proposer收到超过半数的ok,则选举结束,将结果通知给 Learner,否则重新回到准备阶段
实例
准备阶段:
假设客户端 1 的提案编号是 1,客户端 2 的提案编号为 5,并假设节点 A, B 先收到来自客户端 1 的准备请求,节点 C 先收到来自客户端 2 的准备请求。
客户端作为提议者,向所有的接受者发送包含提案编号的准备请求。注意在准备阶段,请求中不需要指定提议的值,只需要包含提案编号即可。
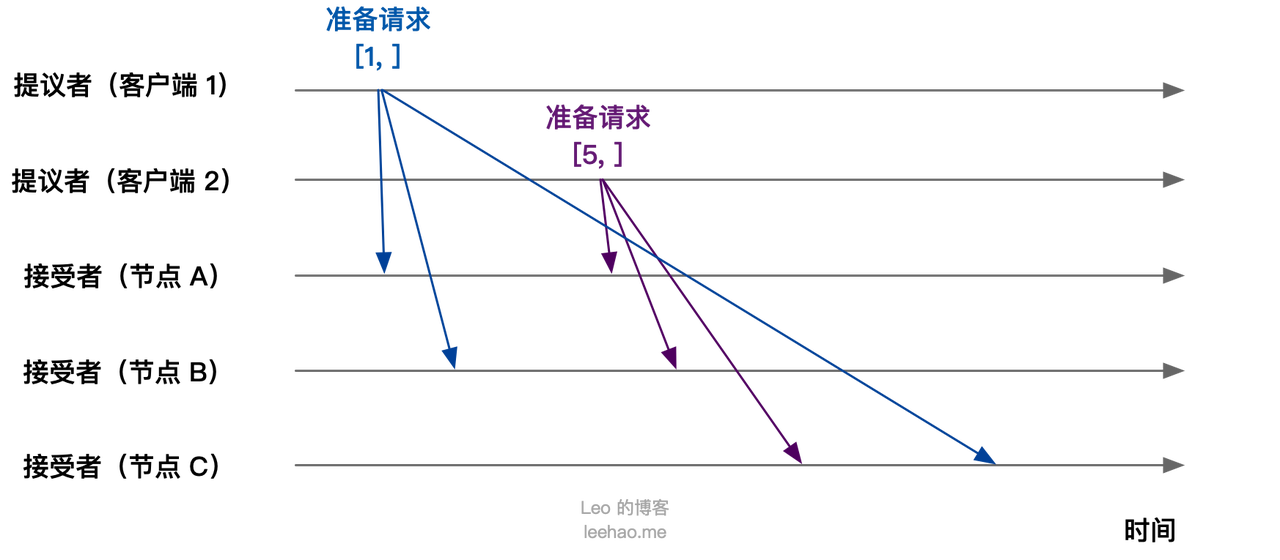
接下来,节点 A,B 接收到客户端 1 的准备请求(提案编号为 1),节点 C 接收到客户端 2 的准备请求(提案编号为 5)。
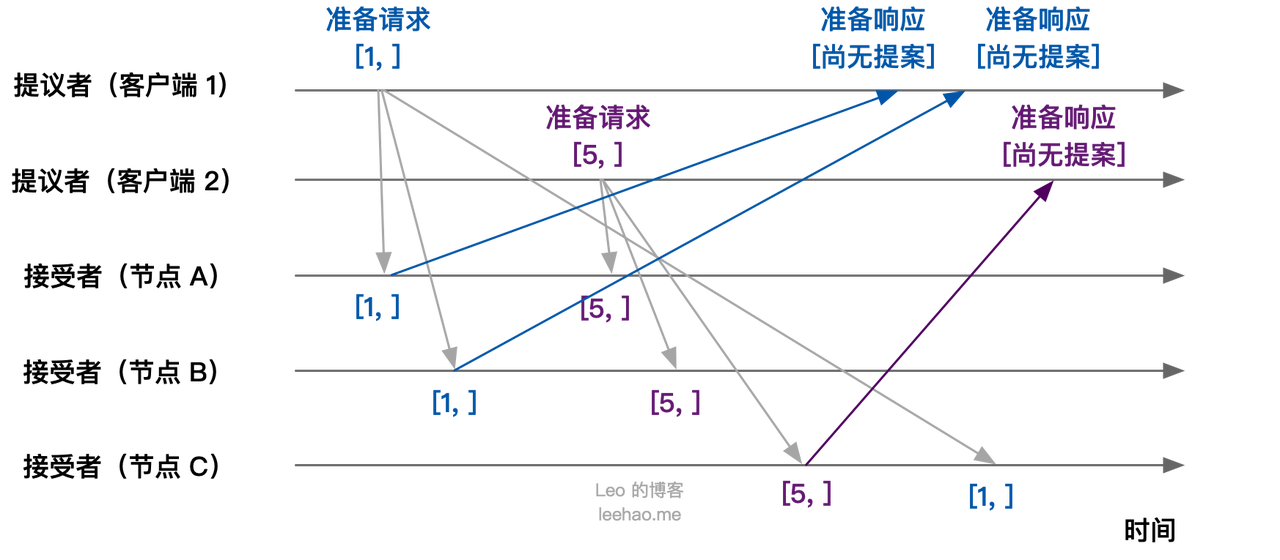
集群中各个节点在接收到第一个准备请求的处理:
- 节点 A, B:由于之前没有通过任何提案,所以节点 A,B 将返回“尚无提案”的准备响应,并承诺以后不再响应提案编号小于等于 1 的准备请求,不会通过编号小于 1 的提案
- 节点 C:由于之前没有通过任何提案,所以节点 C 将返回“尚无提案”的准备响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号小于 5 的提案
接下来,当节点 A,B 接收到提案编号为 5 的准备请求,节点 C 接收到提案编号为 1 的准备请求:
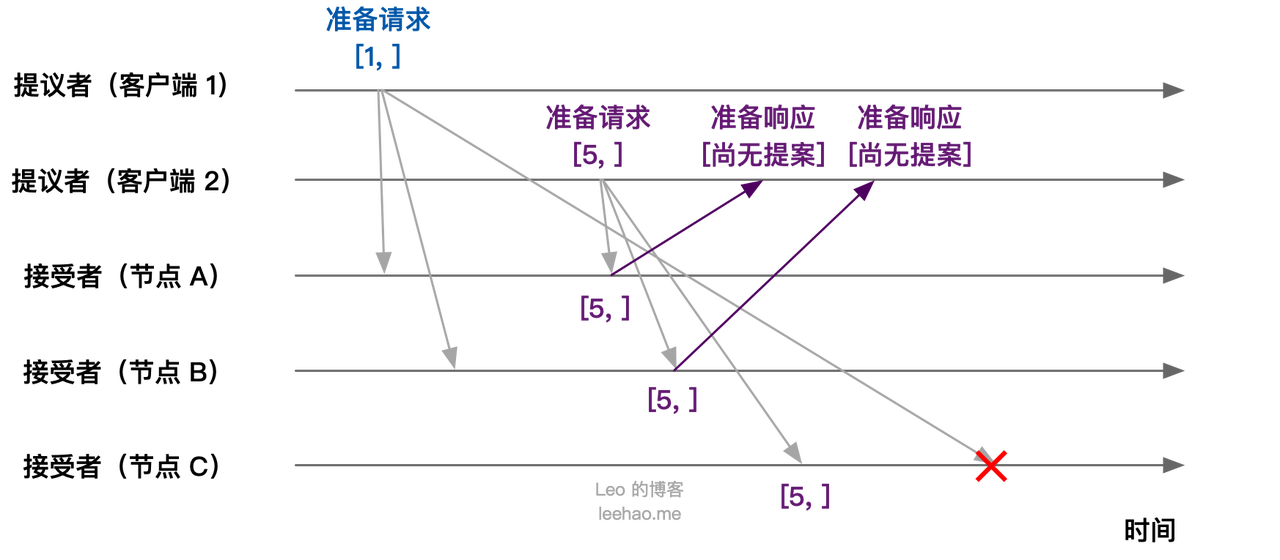
- 节点 A, B:由于提案编号 5 大于之前响应的准备请求的提案编号 1,且节点 A, B 都没有通过任何提案,故均返回“尚无提案”的响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号小于 5 的提案
- 节点 C:由于节点 C 接收到提案编号 1 小于节点 C 之前响应的准备请求的提案编号 5 ,所以丢弃该准备请求,不作响应
接受阶段:
Basic Paxos 算法第二阶段为接受阶段。当客户端 1,2 在收到大多数节点的准备响应之后会开始发送接受请求。
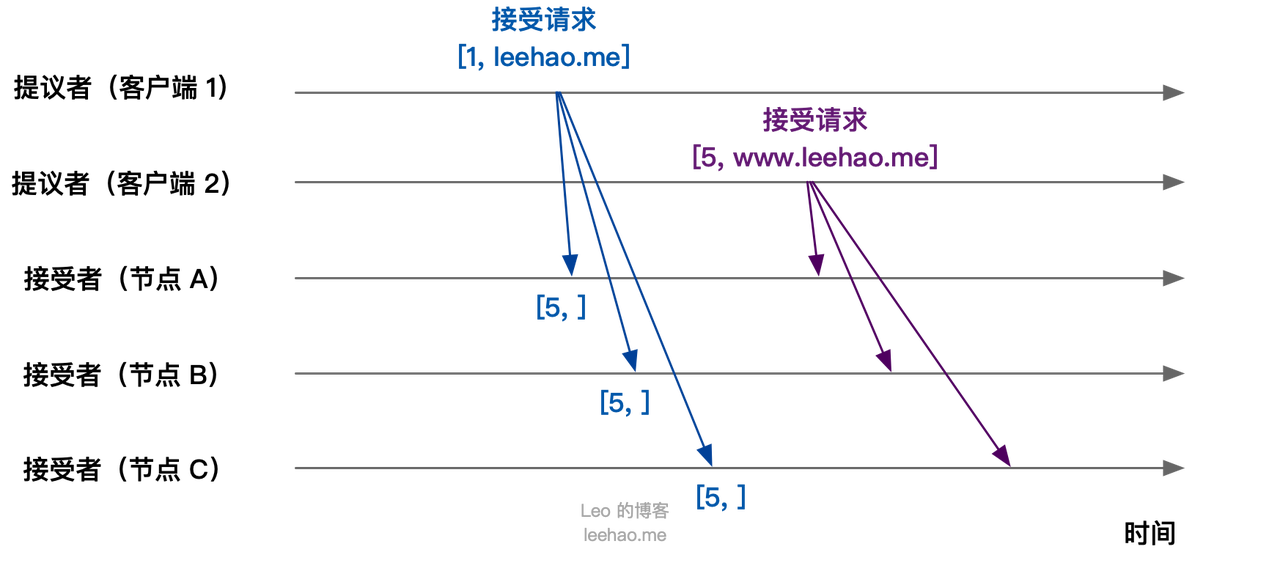
- 客户端 1:客户端 1 接收到大多数的接受者(节点 A, B)的准备响应后,根据响应中的提案编号最大的提案的值,设置接受请求的值。由于节点 A, B 均返回“尚无提案”,即提案值为空,故客户端 1 把自己的提议值 “leehao.me” 作为提案的值,发送接受请求 [1, “leehao.me”]
- 客户端 2:客户端 2 接收到大多数接受者的准备响应后,根据响应中的提案编号最大的提案的值,设置接受请求的值。由于节点 A, B, C 均返回“尚无提案”,即提案值为空,故客户端 2 把自己的提议值 “www.leehao.me” 作为提案的值,发送接受请求 [5, “www.leehao.me”]
当节点 A, B, C 接收到客户端 1, 2 的接受请求时,对接受请求进行处理:
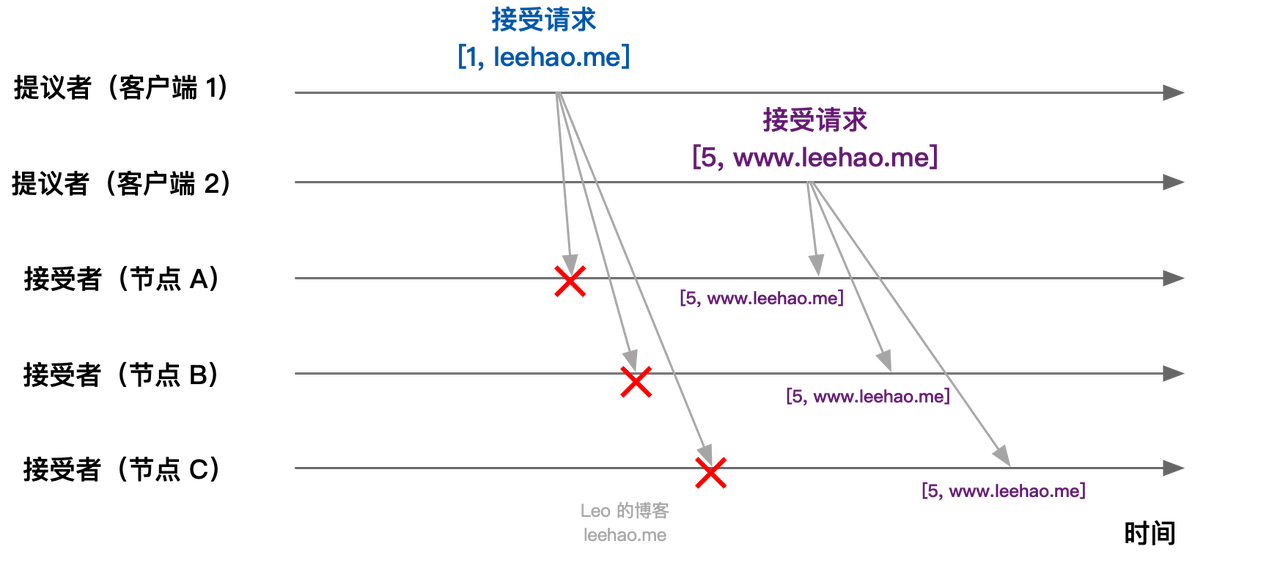
- 节点 A, B, C 接收到接受请求 [1, “leehao.me”] ,由于提案编号 1 小于三个节点承诺可以通过的最小提案编号 5,所以提案 [1, “leehao.me”] 被拒绝
- 节点 A, B, C 接收到接受请求 [5, “www.leehao.me”],由于提案编号 5 不小于三个节点承诺可以通过的最小提案编号 5 ,所以通过提案 [5, “www.leehao.me”],即三个节点达成共识,接受 X 的值为 “www.leehao.me”
如果集群中还有学习者,当接受者通过一个提案,就通知学习者,当学习者发现大多数接受者都通过了某个提案,那么学习者也通过该提案,接受提案的值。
对于 Basic Paxos,假设一个集群有 5 台服务器,其中 3 台接受了(accepted)提案编号 5 和对应的提案值 X,在这种情况下,集群中的任意服务器是否有可能接受不同的值Y?解释你的答案。
是。如果 S1,S2 和 S3 接受了提案 <5, X>,其它服务器仍然可能接受更早的提案编号的提案值 Y。 例如,S4 先发送 Prepare(3) 发现并没有已接受的提案值,接着 S1 发送 Prepare(5)到 S1,S2,S3,然后 S1,S2,S3 接受了<5, X>,此时 S4 仍然可能在 S4,S5 完成提案 <3, Y>
存在问题

为了解决上述的活锁问题,可以通过引入领导者和优化Basic Paxos执行来解决。
领导者(Leader)
可以通过引入领导者节点,也就是说,领导者节点作为唯一提议者,这样就不存在多个提议者同时提交提案的情况,也就不存在提案冲突的情况了:
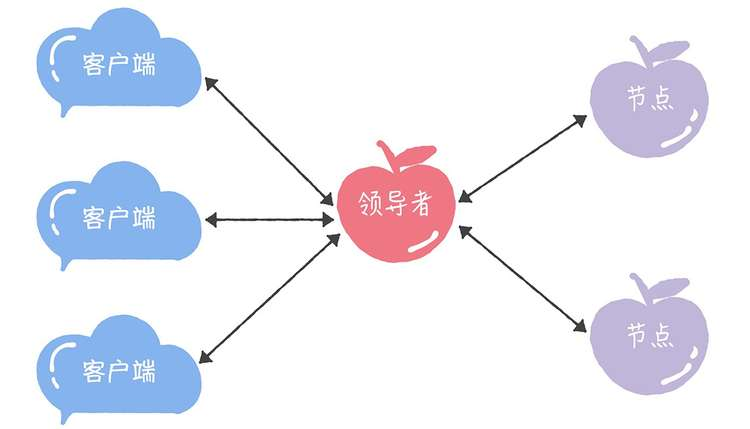
在论文中,Lamport没有说如何选举领导者,需要在实现 Multi-Paxos 算法的时候自己实现。 比如在 Chubby 中,主节点(也就是领导者节点)是通过执行 Basic Paxos 算法,进行投票选举产生的。
优化 Basic Paxos 执行
可以采用“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段”这个优化机制,优化 Basic Paxos 执行。也就是说,领导者节点上,序列中的命令是最新的,不再需要通过准备请求来发现之前被大多数节点通过的提案,领导者可以独立指定提案中的值。这时,领导者在提交命令时,可以省掉准备阶段,直接进入到接受阶段。
和重复执行 Basic Paxos 相比,Multi-Paxos 引入领导者节点之后,因为只有领导者节点一个提议者,只有它说了算,所以就不存在提案冲突。另外,当主节点处于稳定状态时,就省掉准备阶段,直接进入接受阶段,所以在很大程度上减少了往返的消息数,提升了性能,降低了延迟。
过程实现
在实际系统中,该如何实现 Multi-Paxos 呢?接下来,以 Chubby 的 Multi-Paxos 实现为例,具体讲解一下。
- 首先,它通过引入主节点,实现了Lamport提到的领导者(Leader)节点的特性。也就是说,主节点作为唯一提议者,这样就不存在多个提议者同时提交提案的情况,也就不存在提案冲突的情况了。
- 另外,在 Chubby 中,主节点是通过执行 Basic Paxos 算法,进行投票选举产生的,并且在运行过程中,主节点会通过不断续租的方式来延长租期(Lease)。比如在实际场景中,几天内都是同一个节点作为主节点。如果主节点故障了,那么其他的节点又会投票选举出新的主节点,也就是说主节点是一直存在的,而且是唯一的。
- 其次,在 Chubby 中实现了Lamport提到的,“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段”这个优化机制。
- 最后,在 Chubby 中,实现了成员变更(Group membership),以此保证节点变更的时候集群的平稳运行。
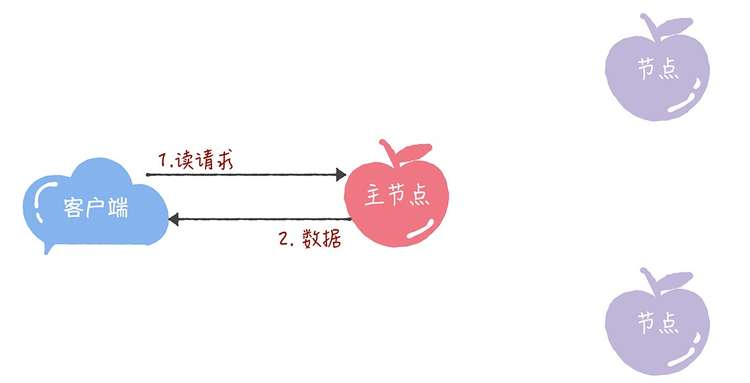
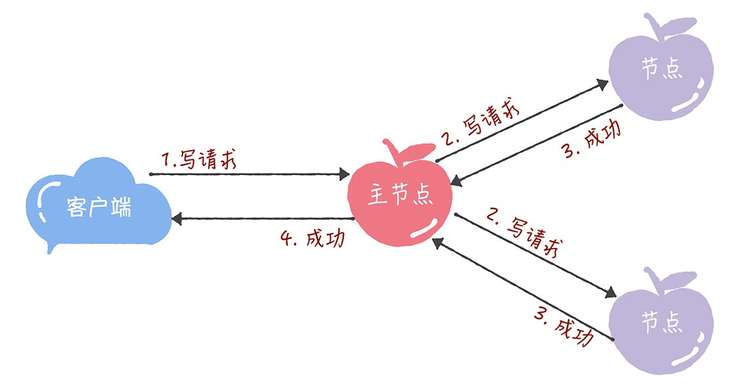
在 Chubby 中,为了实现了强一致性,读操作也只能在主节点上执行。 也就是说,只要数据写入成功,之后所有的客户端读到的数据都是一致的。具体的过程,就是下面的样子。
- 所有的读请求和写请求都由主节点来处理。当主节点从客户端接收到写请求后,作为提议者,执行 Basic Paxos 实例,将数据发送给所有的节点,并且在大多数的服务器接受了这个写请求之后,再响应给客户端成功:
- 当主节点接收到读请求后,处理就比较简单了,主节点只需要查询本地数据,然后返回给客户端就可以了: