Gossip协议是一个通信协议,一种传播消息的方式,灵感来自于:瘟疫、社交网络等。
区别于Paxos、Raft、ZAB 这些强一致性协议,Gossip是一种去中心化的最终一致性协议,Gossip原本用于分布式数据库中节点数据同步,后被广泛用于数据库复制、信息扩散、集群成员身份确认、故障探测等,使用Gossip协议的有:Redis Cluster、Consul、Apache Cassandra等。
原理
Gossip 的过程十分简单,它可以看作是以下两个步骤的简单循环:
- 如果有某一项信息需要在整个网络中所有节点中传播,那从信息源开始,选择一个固定的传播周期(譬如 1 秒),随机选择它相连接的 k 个节点(称为 Fan-Out)来传播消息。
- 每一个节点收到消息后,如果这个消息是它之前没有收到过的,将在下一个周期内,选择除了发送消息给它的那个节点外的其他相邻 k 个节点发送相同的消息,直到最终网络中所有节点都收到了消息,尽管这个过程需要一定时间,但是理论上最终网络的所有节点都会拥有相同的消息。
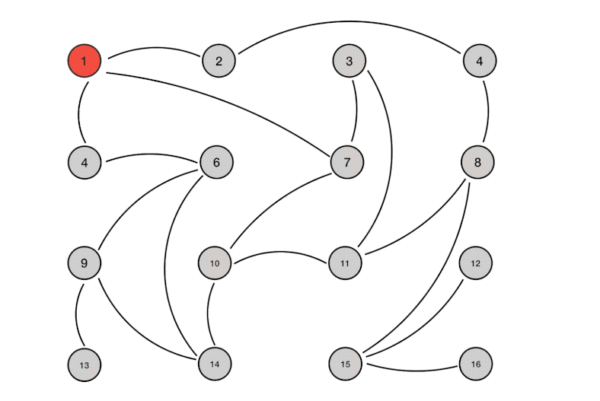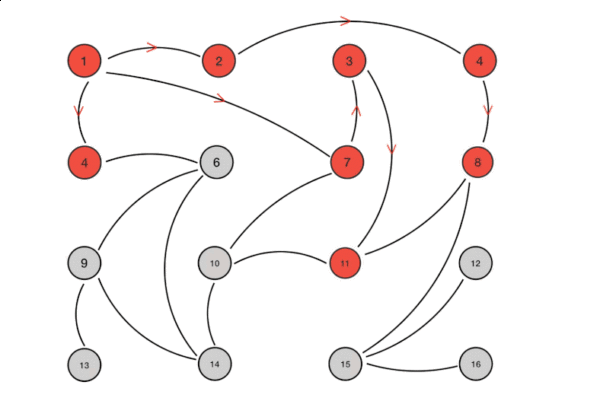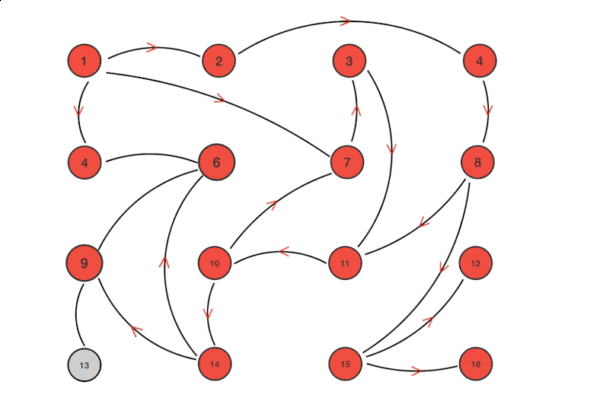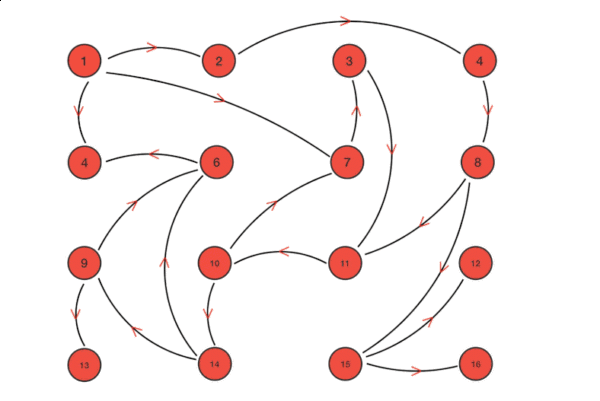
上图是 Gossip 传播过程的示意图,根据示意图和 Gossip 的过程描述,我们很容易发现 Gossip 对网络节点的连通性和稳定性几乎没有任何要求,它一开始就将网络某些节点只能与一部分节点部分连通(Partially Connected Network)而不是以全连通网络(Fully Connected Network)作为前提;能够容忍网络上节点的随意地增加或者减少,随意地宕机或者重启,新增加或者重启的节点的状态最终会与其他节点同步达成一致。Gossip 把网络上所有节点都视为平等而普通的一员,没有任何中心化节点或者主节点的概念,这些特点使得 Gossip 具有极强的鲁棒性,而且非常适合在公众互联网中应用。
同时我们也很容易找到 Gossip 的缺点,消息最终是通过多个轮次的散播而到达全网的,因此它必然会存在全网各节点状态不一致的情况,而且由于是随机选取发送消息的节点,所以尽管可以在整体上测算出统计学意义上的传播速率,但对于个体消息来说,无法准确地预计到需要多长时间才能达成全网一致。另外一个缺点是消息的冗余,同样是由于随机选取发送消息的节点,也就不可避免的存在消息重复发送给同一节点的情况,增加了网络的传输的压力,也给消息节点带来额外的处理负载。
达到一致性耗费的时间与网络传播中消息冗余量这两个缺点存在一定对立,如果要改善其中一个,就会恶化另外一个,由此,Gossip 设计了两种可能的消息传播模式:反熵(Anti-Entropy)和传谣(Rumor-Mongering)。熵(Entropy)是生活中少见但科学中很常用的概念,它代表着事物的混乱程度。反熵的意思就是反混乱,以提升网络各个节点之间的相似度为目标,所以在反熵模式下,会同步节点的全部数据,以消除各节点之间的差异,目标是整个网络各节点完全的一致。但是,在节点本身就会发生变动的前提下,这个目标将使得整个网络中消息的数量非常庞大,给网络带来巨大的传输开销。而传谣模式是以传播消息为目标,仅仅发送新到达节点的数据,即只对外发送变更信息,这样消息数据量将显著缩减,网络开销也相对较小。
传播机制
在《Epidemic Algorithms for Replicated Database Maintenance》论文中主要论述了直接邮寄(direct mail)、反熵传播(anti-entropy)、谣言传播(rumor mongering)三种机制来实现数据更新。Gossip协议主要是通过反熵传播(anti-entropy)、谣言传播(rumor mongering)实现的。
direct mail,直接邮寄
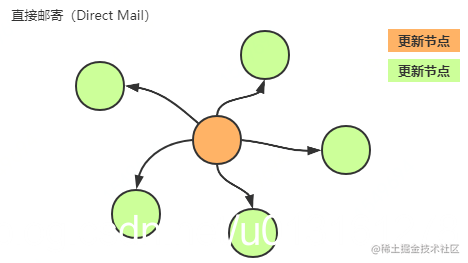 每个节点的变更都会直接同步到其他节点, 这种方式是通过遍历节点并发送更新的方式实现,它将消息排队,队列保存在服务器中,因此不会受到服务器崩溃的影响,能够及时且有效的实现更新同步,但主要缺点是:
每个节点的变更都会直接同步到其他节点, 这种方式是通过遍历节点并发送更新的方式实现,它将消息排队,队列保存在服务器中,因此不会受到服务器崩溃的影响,能够及时且有效的实现更新同步,但主要缺点是:
- 不可靠,在遇到网络通信故障、节点宕机等情况下没有办法容错和补偿,极端情况下无法保证分布式环境下各节点数据一致性的,当队列溢出或其目的地长时间不可访问时,邮件可能会被丢弃
- 节点之间要互相知道对方的存在,怎样感知对方存在也是一个难以解决的点,当节点感知不到对方时则会存在更新丢失的情况
- 发送的更新数量巨大且支持的节点数量有限,在稍大规模的集群中容易引起性能问题,随着网络规模的增加,节点的数据更新可能变得缓慢,甚至导致节点网络I/O过高而崩溃
anti-entropy,反熵传播
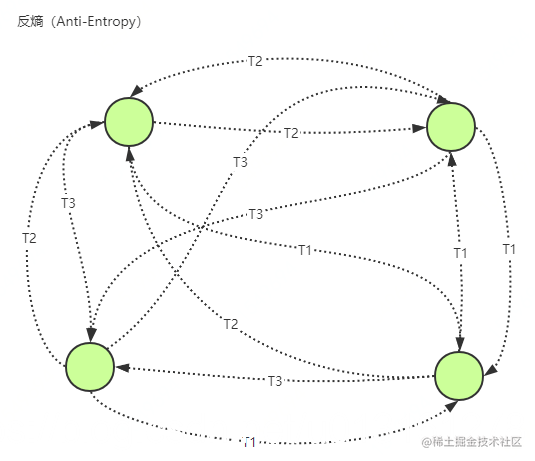
每个节点都会定期随机选择节点池中的一些节点,通过交换数据内容来解决两者之间的任何差异。
和直接邮寄(direct mail)相比的最大特点是解决了消息丢失无补偿导致数据不一致的致命问题,但因此也引入了新的问题:
- 消息数量大且无限制,通过定时重复发送消息保证数据达到最终一致,消息大量冗余,网络流量大。
- 定期发送的频率不好设定,每隔多久发送一次和数据更新的频率相关。
- 无论是采取push、pull还是push & pull的方式都需要发送全量数据进行对比更新,耗费网络流量大,虽然可通过checksum的方式实现对比,节点计算checksum,只有当checksum不一致时才发送全量数据进行对比,前提是在数据update很少时确实可以节省很多网络流量,但数据update通常很难再同一时间传播到所有节点,如果这时新的数据update又发送了并且随着网络流量的增大,节点处理也会越来越慢,checksum的机制作用将会越来越小。
rumor mongering,谣言传播
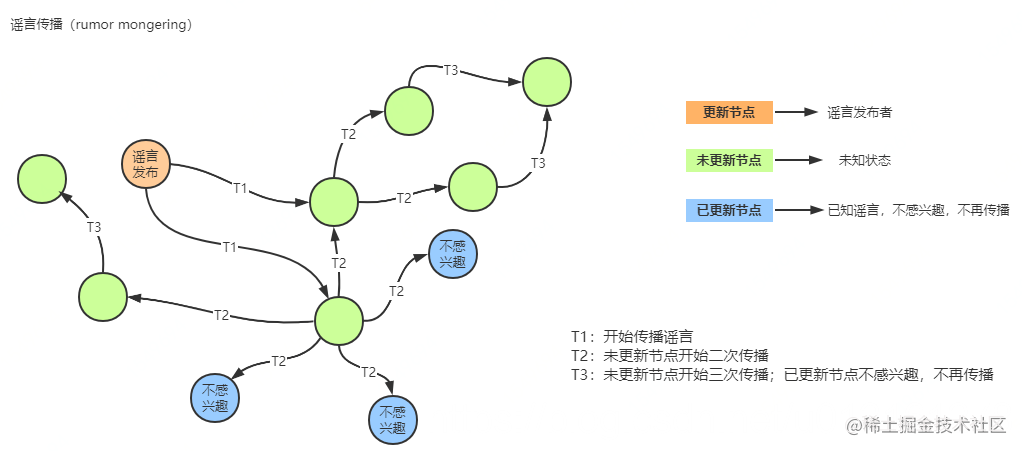
节点最初是“ignorant”状态,当一个节点收到一个新的更新时会成为一个“hot rumor”状态,当一个节点是hot rumor状态时,它会定期随机选择一些节点发生更新消息,当消息传播到大多数节点时就会停止谣言传播。
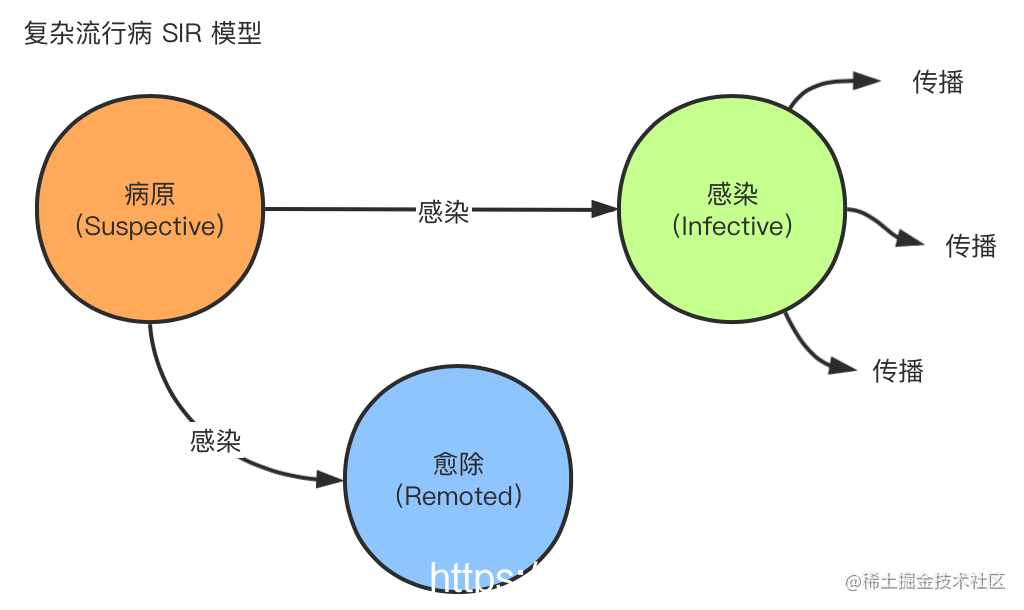
用流行病传播的方式可以将谣言传播(rumor mongering)中的节点状态定义Suspective(病原)、Infective(感染)、Removed(愈除)3个状态,也叫复杂流行病(complex epidemics)
- 消息生产节点即为Suspective(病原)状态。
- 消息接收节点即为Infective(感染)状态,会进行消息传播。
- 节点接收消息后即为Removed(愈除)状态,不再进行传播。
谣言传播优点是消息传播可以较快收敛,占用的资源比较少,但也引入了另外的一些问题:
- 不可靠,通过定期选择一些节点且当消息传播到大多数节点时就会停止传播,存在一定概率更新会传播不到所有节点。
- 实现复杂,如何确定消息发送到大多数节点,如何确定大多数节点收到了消息,这些都受网络延迟、节点宕机等影响。
通信模式
拉方式(Pull)–更新主动拉取的节点
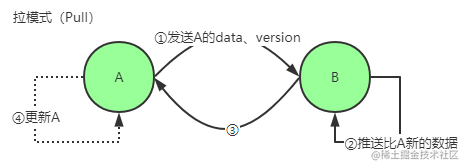
具体过程:
- A仅将数据 key, version 推送给 B
- B 将本地比 A 新的数据(Key, value, version)推送给 A
- 回传 B 数据给 A
- A 更新本地
推方式(Push)–更新被push的节点
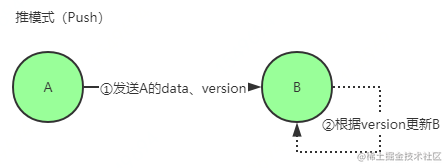
具体过程:
- 节点 A 将数据 (key,value,version) 推送给 B 节点
- B 节点更新 A 中比自己新的数据
推拉方式(Push&Pull)–双方节点都做更新
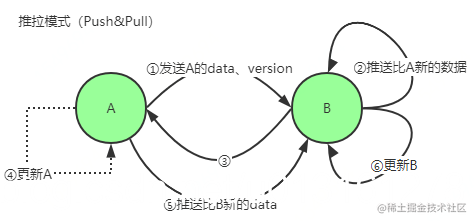
- A仅将数据 key, version 推送给 B
- B 将本地比 A 新的数据(Key, value, version)推送给 A
- 回传 B 数据给 A
- A 更新本地
- 推送比 B 新的数据
- 更新 B.