分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。
设计目标
分布式系统就是一组计算机节点和软件共同对外提供服务的系统。但对于用户来说,操作分布式系统就好像是在请求一个服务器。因为在分布式系统中,各个节点之间的协作是通过网络进行的,所以分布式系统中的节点在空间分布上几乎没有任何限制,可以分布于不同的机柜、机房,甚至是不同的国家和地区。
分布式系统的设计目标一般包括如下几个方面:
- 可用性:可用性是分布式系统的核心需求,其用于衡量一个分布式系统持续对外提供服务的能力。
- 可扩展性:增加机器后不会改变或极少改变系统行为,并且能获得近似线性的性能提升。
- 容错性:系统发生错误时,具有对错误进行规避以及从错误中恢复的能力。
- 性能:对外服务的响应延时和吞吐率要能满足用户的需求。
特点
分布式系统的三大关键特征是节点之间并发工作,没有全局锁以及某个节点上发生的错误不影响其他节点。
- 分布性:分布式系统中的多台计算机都会在空间上随意分配,同时,机器的分布情况也会随时变动。
- 对等性:分布式系统中的计算机没有主从之分,既没有控制整个系统的主机,也没有被控制的从机,组成分布式系统的所有计算机节点都是对等的。
- 并发性
- 缺乏全局时钟
- 故障总是会发生:任何在设计阶段考虑到的异常情况,一定会在系统实际运行中发生,并且,在系统实际运行过程中还会遇到很多在设计时未能考虑到的异常故障。
CAP原理
CAP 理论表明一个分布式系统不可能同时满足一致性、可用性和分区容错性这三项基本需求,最多只能同时满足其中的两项。
- C - Consistent(一致性):这里的一致性特指强一致,通俗地说,就是所有节点上的数据时刻保持同步。一致性严谨的表述是原子读写,即所有读写都应该看起来是“原子”的,或串行的。所有的读写请求都好像是经全局排序过的一样,写后面的读一定能读到前面所写的内容。
- A - Availability(可用性):任何非故障节点都应该在有限的时间内给出请求的响应,不论请求是否成功。
- P - Partition tolerance(分区容错性):当发生网络分区时(即节点之间无法通信),在丢失任意多消息的情况下,系统仍然能够正常工作。
分布式系统的节点往往都是分布在不同的机器上进行网络隔离开的,这意味着必然会有网络断开的风险,这个网络断开的场景的专业词汇叫着「网络分区」。
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。一句话概括 CAP 原理: 网络分区发生时,一致性和可用性两难全。
AP系统
AP 满足但 C 不满足:如果既要求系统高可用又要求分区容错,那么就要放弃一致性了。因为一旦发生网络分区( P ),节点之间将无法通信,为了满足高可用( A ),每个节点只能用本地数据提供服务,这样就会导致数据的不一致(!C )。一些信奉BASE (Basic Availability, So丘state, Eventually Consistency )原则的NoSQL 数据库(例如, Cassandra 、CouchDB 等)往往会放宽对一致性的要求(满足最终一致性即可),以此来换取基本的可用性。
CP系统
CP 满足但 A 不满足:如果要求数据在各个服务器上是强一致的(C),然而网络分区(P)会导致同步时间无限延长,那么如此一来可用性就得不到保障了(!A)。坚持分布式事务ACID(原子性、一致性、隔离性和持久性)的传统数据库以及对结果一致性非常敏感的应用(例如,金融业务)通常会做出这样的选择。
BASE 理论
BASE 是指基本可用(BasicallyAvailable)、软状态(SoftState)和最终一致性(EventuallyConsistent)。其核心思想是即使无法做到强一致性,但每个应用都可以根据自身的业务特点,采用适当的方式使系统达到最终一致性。
BASE 是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结。
基本可用(Basically Availability)
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性,即保证核心可用。
- 响应时间上的损失
- 功能上的损失: 服务降级
弱状态(Soft-State)
弱状态也称软状态,指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
相对于 ACID 中的原子性(Atomicity)而言,要求多个节点的数据副本都是一致的,这是一种 “硬状态”。数据库读写分离,写库同步到读库(主库同步到从库)会有一个延时,这样实际是一种柔性状态
最终一致性
最终一致性是指系统中所有的数据副本,再经过一段时间的同步后,最终能够达到一个一致的状态。在实际工程实践中,最终一致性存在以下五类主要变种:
- 因果一致性:因果一致性是指,如果进程 A 在更新完某个数据项后通知了进程B,那么进程B之后对该数据项的访问都应该能够获取到进程A更新后的最新值,并且如果进程B要对该数据项进行更新操作的话,务必基于进程 A 更新后的最新值,即不能发生丢失更新情况。
- 读已之所写:进程A更新一个数据项之后,它自己能够访问到更新过的最新值,而不会看到旧值。
- 会话一致性:系统能保证在同一个有效的会话中实现“读已之所写”的一致性。
- 单调读一致性:如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。
ACID 和 BASE 的区别与联系
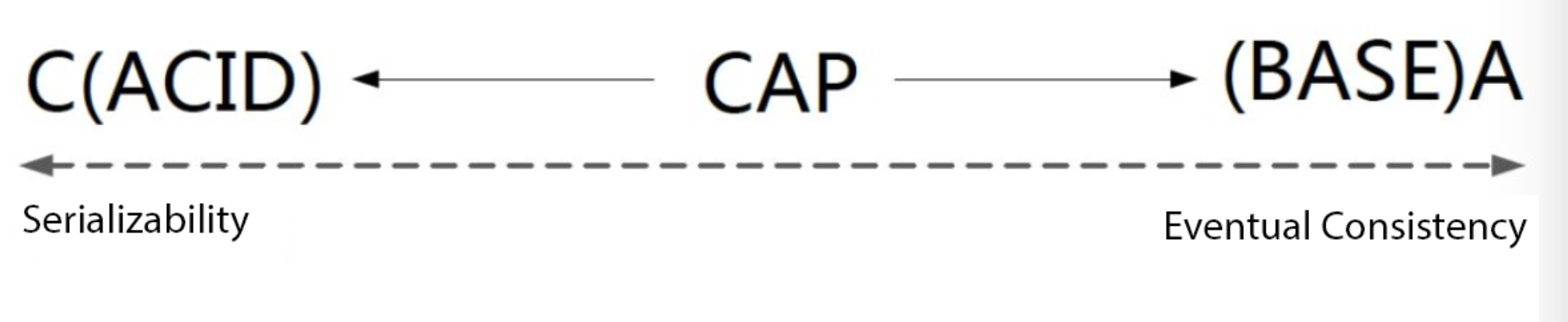
ACID 和 BASE 代表了两种截然相反的设计哲学,而 CAP 也正是 ACID 和 BASE 长期博弈(trade off)的结果。
ACID 是传统数据库常用的设计理念,追求强一致性模型。因此 ACID 伴随数据库的诞生定义了系统基本设计思路,
2000 年左右,随着互联网的发展,高可用的话题被摆上桌面,所以提出了 BASE ,即通过牺牲强一致性获得高可用性。从此 C 和 A 的取舍消长此起彼伏,其结晶就是 CAP 理论。
在高可用与高性能的应用场景,分布式事务的最佳实践是放弃 ACID,遵循 BASE 的原则重构业务流程。
CAP 并不与 ACID 中的 A(原子性)冲突,值得讨论的是 ACID 中的 C(一致性)和 I(隔离性)。ACID 的 C 指的是事务不能破坏任何数据库规则,如键的唯一性。与之相比,CAP 的 C 仅指单一副本这个意义上的一致性,因此 CAP 的 C 只是 ACID 一致性约束的一个严格的子集。
如果系统要求ACID中的I(隔离性),那么它在分区期间最多可以在分区一侧维持操作。事务的可串行性(serializability)要求全局的通信,因此在分区的情况下不能成立。