引子
客户端设置的字符区间参数 [start,end) 是什么维度?应该怎么来用?
- 评论文本: 👨👩👧👧@🌈新密海燕👨👩👧👧 一家 这是一条测试评论[捂脸];
- mention区间(@🌈新密海燕👨👩👧👧一家):{“Start”:11,”End”:32};
为什么 👨👩👧👧 这种 Emoji 占用 7 个 unicode?utf-16 中占用 11 个码元?
获取的用户昵称(nickname)中,为什么有乱码?需要如何处理?
- 用户真实 nickname:Let’s Peng 返回: Let's Peng
- 用户真实 nickname:屿&🐟 返回: 屿&🐟
创建数据表时,指定的CHARSET=utf8 和 CHARSET=utf8mb4 有什么区别?
各种开发语言中 使用什么编码 ?
uri 为什么需要 encode/decode ?
知识背景
基础概念
字符
字符(character)是各种文字和符号的统称,包括各国家文字、标点符号、图形符号、数字等。像英语中的 a 以及汉字中的 华 都被称为字符(character);
字符集
字符的集合即字符集(character set),比如拉丁字母集和中文汉字集。给字符集中的每一个字符赋予一个数字,这些数字构成的集合被称作编码字符集(coded character set),后文简称字符集;比如 ASCII 定义了一个编码字符集,其中 A 对应的数字为 0x41,0x41 这个数字被称作 码点(code point)。
编码
通常说的 编码(encoding)指的是将字符集转化成序列化的形式,意思是说将字符集中的码点映射到一个或多个字节中; 有些情况下,字符集和编码是一体的:例如 GBK 和 ASCII 是字符集和编码的统称;
码元
码元(Code Unit,也称“代码单元”)是指一个已编码的文本中具有最短的比特组合的单元。对于 UTF-8 来说,码元是 8 比特长;对于 UTF-16 来说,码元是 16 比特长;对于 UTF-32 来说,码元是 32 比特长。
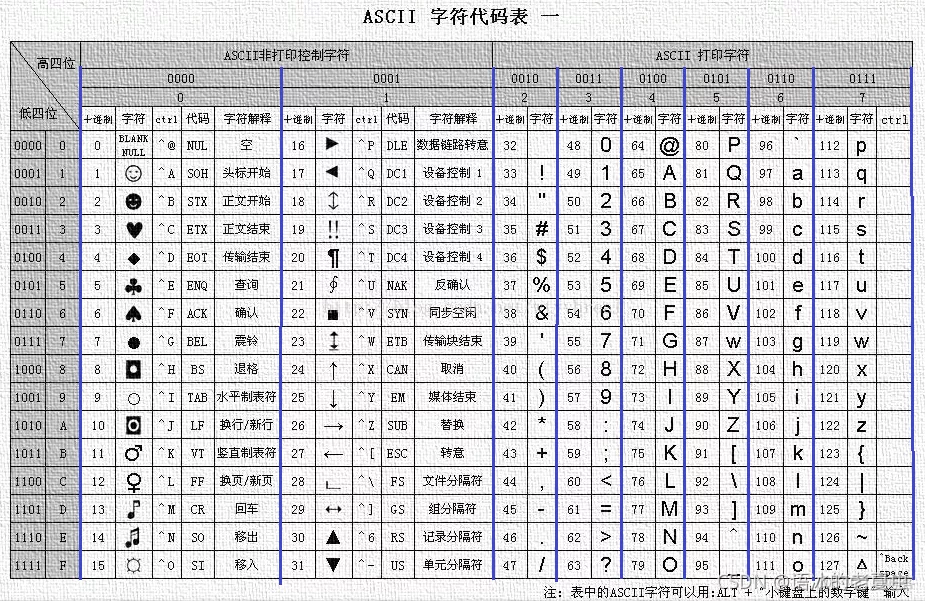
ASCII【字符集&编码】
ASCII (American Standard Code for Information Interchange) 码 是 7 位编码,编码范围为 0x00〜0x7F。ASCII 码字符集包括英文字符、阿拉伯数字、标点符号等。其中0x00〜0x20 和 0x7f 共 33 个特殊字符。忽略最高位,只有低 7 位有效。
仅兼容英语;
Unicode【字符集】
Unicode 中文名称为 统一码(又称万国码、统一字元码、统一字符编码),是信息技术领域的业界标准,其整理、编码了世界上大部分的文字系统,使得电脑能以通用划一的字符集来处理和显示文字,不但减轻在不同编码系统间切换和转换的困扰,更提供了一种跨平台的乱码问题解决方案。
Unicode 备受认可,被 ISO 纳入国际标准,成为通用字符集(英语:Universal Character Set, UCS),即 ISO/IEC 10646。Unicode 兼容 ISO/IEC 10646,能完整对应各个版本标准。
codepoints.net/ 网站中可查看每个字符对应的码点信息。
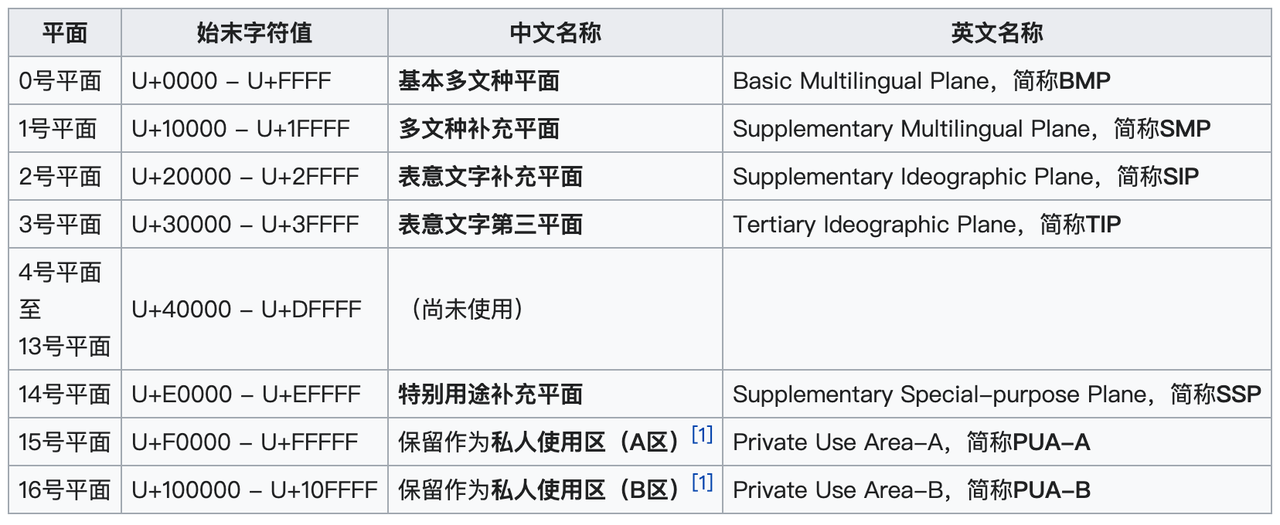
Unicode 字符平面
Unicode 字符分为 17 组编排,每组称为平面(Plane),而每平面拥有 65536(即2^16)个代码点。然而目前只用了少数平面。
{kind=link}
其中编号 0 对应的平面包括 U+0000 ~ U+FFFF,通常称为 BMP(the Basic Multilingual Plane),大部分位置都被 CJK 字符所使用。 CJK文字 是中文、日文和韩文的统称
组合字符
Unicode 支持通过组合将多个字符合并成一个字符的机制,包括带音标的字符、emoji 以及表意文字的组合。比如:
👨👩👧👧 = 👨+连接符+👩+连接符+👧+连接符+👧
Emoji 表情符号
2010年,Unicode 开始为 Emoji 分配码点。也就是说,现在的 Emoji 符号就是一个文字,它会被渲染为图形。
Unicode 只是规定了 Emoji 的码点和含义,并没有规定它的样式。举例来说,码点
U+1F600表示一张微笑的脸,但是这张脸长什么样,则由各个系统自己实现。
{kind=link}
Unicode 除了使用单个码点表示 Emoji,还允许多个码点组合表示一个 Emoji。 其中的一种方式是”零宽度连接符”(ZERO WIDTH JOINER,缩写 ZWJ)U+200D。举例来说,下面是三个 Emoji 的码点。
- U+1F468:男人
- U+1F469:女人
- U+1F467:女孩
上面三个码点使用
U+200D连接起来,U+1F468U+200DU+1F469U+200DU+1F467,就会显示为一个 Emoji 👨👩👧👧,表示他们组成的家庭。如果用户的系统不支持这种方法,就还是显示为三个独立的 Emoji 👨👩👧。
UTF-8【编码】
UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,实现了对 ASCII 码的向后兼容,它的最大特点就是可变长,也是一种前缀码。它可以用一至四个字节对 Unicode 字符集中的所有码点进行编码。编码规则如下:
- 对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
- 对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为 0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
- 解码过程:如果一个字节的第一位是 0 ,则说明这个字节对应一个字符;如果一个字节的第一位 1,那么连续有多少个 1,就表示该字符占用多少个字节。
{kind=link}
“汉”的 Unicode 码点是
0x6c49(110 1100 0100 1001),通过上面的对照表可以发现,0x0000 6c49 位于第三行的范围,那么得出其格式为 1110xxxx 10xxxxxx 10xxxxxx。接着,从“汉”的二进制数最后一位开始,从后向前依次填充对应格式中的 x,多出的 x 用 0 补上。这样,就得到了“汉”的 UTF-8 编码为 11100110 10110001 10001001,转换成十六进制就是 0xE6 0xB7 0x89。
UTF-32【编码】
UTF-32 是最直观的编码方法,每个码点使用四个字节表示。比如,码点 0 就用四个字节的 0 表示,码点 U+597D就在前面加两个字节的 0。
1
2
U+0000 = 0x0000 0000
U+597D = 0x0000 597D
UTF-32 的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比 ASCII 编码大四倍。这个缺点很致命,导致实际上没有人使用这种编码方法,HTML 5 标准就明文规定,网页不得编码成 UTF-32。
UTF-16【编码】
UTF-16 编码结合了定长和变长两种编码方法的特点。它的编码规则很简单:基本平面的字符占用 2 个字节,辅助平面的字符占用 4 个字节。也就是说,UTF-16 的编码长度要么是 2 个字节(U+0000 到 U+FFFF),要么是 4 个字节(U+010000 到 U+10FFFF)。
- 在基本平面内,从 U+D800 到 U+DFFF 是一个空段,即这些码点不对应任何字符。因此这个空段可以用来映射辅助平面的字符。
- 辅助平面的字符数共有 2^20 个,因此表示这些字符至少需要 20 个二进制位。UTF-16 将这 20 个二进制位分成两半:
- 前 10 位映射在 U+D800 到 U+DBFF(空间大小 2^10),称为高位(H)
- 后 10 位映射在 U+DC00 到 U+DFFF(空间大小 2^10),称为低位(L)
- 在解析码元时,如果值在0xD800 到 0xDBFF 之间,就可以断定,紧跟在后面的码元,应该在 0xDC00 到 0xDFFF 之间,这两个码元必须放在一起解读。 汉字”𠮷”的 Unicode 码点为 U+20BB7,该码点显然超出了基本平面的范围(U+0000 - U+FFFF),因此需要使用四个字节表示。首先用 0x20BB7 - 0x10000 计算出超出的部分(相当于平面序号减1,有16个辅助平面,所以需要减 1 处理),然后将其用 20 个二进制位表示(不足前面补 0 ),结果为 0001000010 1110110111。接着,将前 10 位映射到 U+D800 到 U+DBFF 之间,后 10 位映射到 U+DC00到 U+DFFF 即可。U+D800 对应的二进制数为 1101100000000000,直接填充后面的 10 个二进制位即可,得到 1101100001000010,转成 16 进制数则为 0xD842。同理可得,低位为 0xDFB7。因此得出汉字”𠮷”的 UTF-16 编码为 0xD842 0xDFB7。
UTF-16 取代了 UCS-2,或者说 UCS-2 整合进了 UTF-16。 准确来说,UCS-2 只包含 BMP 平面的 编码;
要决定 UTF-8 或 UTF-16 哪种编码比较有效率,需要视所使用的字元的分布范围而定。
ANSI
在 Unicode 编码方案问世之前,各个国家与地区为了用计算机记录并显示自己的字符,都在 ASCII 编码方案的基础上,独立设计了各自的编码方案。这些不同的编码既兼容 ASCII 又互相之间不兼容,统称为 ANSI 编码。
- 欧洲:ISO/IEC 8859
- 中国:GB 系列编码(“GB”为“国标”的汉语拼音首字母缩写)。
- GB2312
- GBK
- 日本:Shift_JIS
GB2312【字符集&编码】
GB2312 是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,简体GB0。
GB2312 共收录 6763 个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。
GB2312 基于区位码设计,对所收汉字/符号采用双字节编码。每区含有 94 个汉字/符号,共计 94 个区。实际上,只使用了 87 区。
在 GB2312 编码中,还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。
在 GB2312 编码中,一个小于 127 的字节的意义与 ASCII 码相同,但两个大于 127 的字节连在一起时,就表示一个汉字字符,前面的一个字节(高字节)是区码,从 0xA1(161) 用到 0xF7(247)(把 1–87 区的区号加 160 或0×A0)。后面一个字节(低字节)是位码,从 0xA1(161) 到 0xFE(254)(把 01–94 加上160 或0×A0)。
为什么区码\位码需要加 160 或0×A0:
- 为了避开 ASCII 字符中的 CR0 不可显示字符(十六进制为0×00至0×1F,十进制为0至31)及空格字符(十六进制为0×20,十进制为32),国标码(又称为交换码)参考 ISO 2022 规定表示非 ASCII 字符双字节编码范围为十六进制为 <21 21>-<7E 7E>,十进制为 (33, 33) 至 (126, 126)。因此,在进行码位转换时,须将“区码”和“位码”分别加上32(十六进制为0×20)作为国标码。
- 因为国标码和通用的 ASCII 码冲突,因此后续为了方便辨认单字节和双字节的编码,部分厂商在 ISO 2022 的基础上把双字节字符的二进制最高位都从 0 换成 1,即相当于把 ISO 2022 的每个字节都再加上128(十六进制为0×80)得到“机内码”表示,简称“内码”。
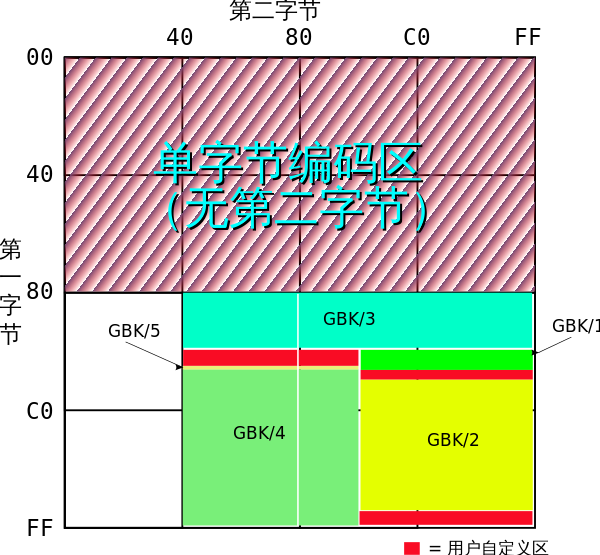
GBK【字符集&编码】
汉字内码扩展规范,简称GBK,全名为《汉字内码扩展规范(GBK)》。 GBK 是对 GB2312 编码的扩展,对汉字采用双字节编码。 GBK共收录 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。 GBK编码的第一字节向 0x81–0xFE (126个区) 、第二字节向 0x40–0xFE (191个位) 进行扩展。
{kind=link}
- GBK/1: 0xA1A1-0xA9FE,收录 GB 2312 非汉字符号区;
- GBK/2: 0xB0A1-0xF7FE,收录 GB 2312 汉字区 。收录 GB 2312 汉字 6763 个,按原顺序排列;
- GBK/3: 0x8140-0xA0FE。收录 GB 13000.1 中的 CJK 汉字 6080 个。
- GBK/4: 0xAA40-0xFEA0。收录 CJK 汉字和增补的汉字 8160 个。
- GBK/5: 0xA996 汉字“〇”安排在图形符号区;
- 用户自定义区:分为三个小区:
- 0xAAA1-0xAFFE,码位 564 个。
- 0xF8A1-0xFEFE,码位 658 个。
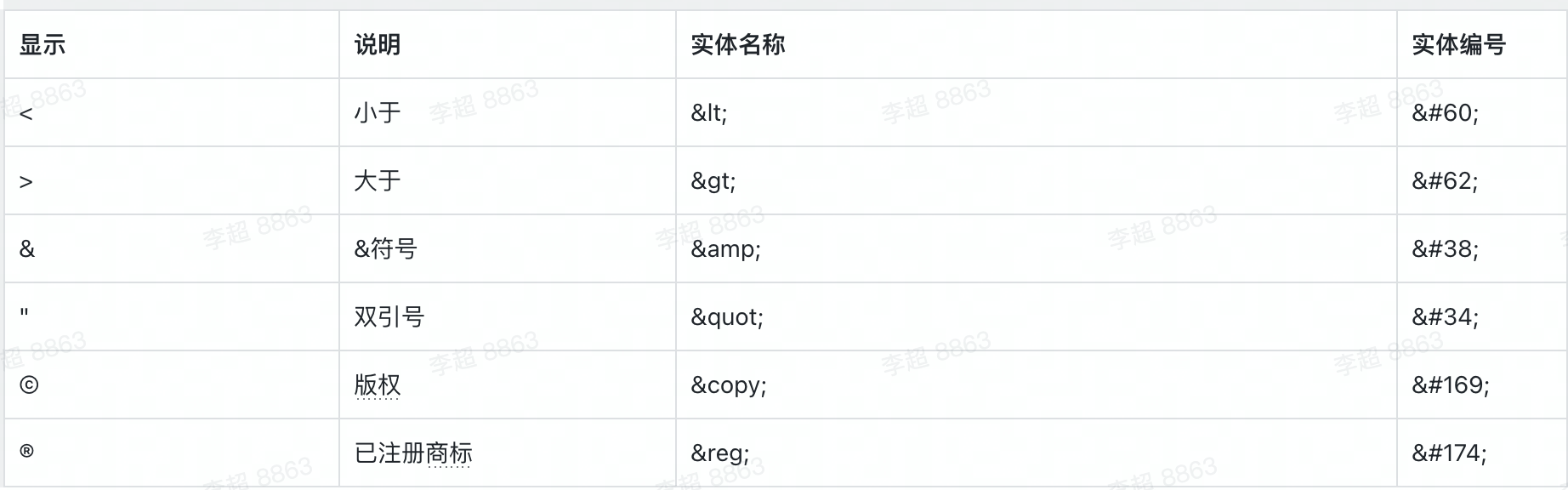
- 0xA140-0xA7A0,码位 672 个。 GB 13000.1 等同于 Unicode 1.1 版本; html 转义字符串 HTML中 <,>,& 等符号有特殊含义,不能直接使用。如果想要在网页中显示这些符号,就需要 HTML转义字符串(Escape Sequence)。 在HTML中,定义转义字符串的原因有两个:
- 像 < 和 > 这类符号已经用来表示 HTML 标签,因此就不能直接当作文本中的符号来使用。为了在HTML文档中使用这些符号,就需要定义它的转义字符串。当解释程序遇到这类字符串时,就把它解释为真实的字符。在输入转义字符串时,要严格遵守字母大小写的规则。
- 有些字符在 ASCII 字符集中没有定义,因此需要使用转义字符串来表示。 转义字符串的组成: 转义字符串(Escape Sequence)又称字符实体(Character Entity)分成三部分:
- 第一部分:是一个&符号,英文叫 ampersand;
- 第二部分:是实体(Entity)名字或者是#加上实体(Entity)编号;
- 第三部分:是一个分号。 比如,要显示小于号(<),就可以写 < 或者 <
用实体(Entity)名字的好处是比较好理解,一看 lt,大概就猜出是 less than 的意思,但是其劣势在于并不是所有的浏览器都支持最新的 Entity 名字。而实体(Entity)编号,各种浏览器都能处理。
{kind=link}
答案
客户端字符区间参数 [start,end) 是什么维度?
- 评论文本 unicode 编码 :[U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F467 U+0040 U+1F308 U+65B0 U+5BC6 U+6D77 U+71D5 U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F467 U+0020 U+4E00 U+5BB6 U+0020 U+8FD9 U+662F U+4E00 U+6761 U+6D4B U+8BD5 U+8BC4 U+8BBA U+005B U+6342 U+8138 U+005D]
- 评论文本 utf-16 编码 : [U+D83D U+DC68 U+200D U+D83D U+DC69 U+200D U+D83D U+DC67 U+200D U+D83D U+DC67 U+0040 U+D83C U+DF08 U+65B0 U+5BC6 U+6D77 U+71D5 U+D83D U+DC68 U+200D U+D83D U+DC69 U+200D U+D83D U+DC67 U+200D U+D83D U+DC67 U+0020 U+4E00 U+5BB6 U+0020 U+8FD9 U+662F U+4E00 U+6761 U+6D4B U+8BD5 U+8BC4 U+8BBA U+005B U+6342 U+8138 U+005D]
- 评论文本 utf-8 编码: [U+00F0 U+009F U+0091 U+00A8 U+00E2 U+0080 U+008D U+00F0 U+009F U+0091 U+00A9 U+00E2 U+0080 U+008D U+00F0 U+009F U+0091 U+00A7 U+00E2 U+0080 U+008D U+00F0 U+009F U+0091 U+00A7 U+0040 U+00F0 U+009F U+008C U+0088 U+00E6 U+0096 U+00B0 U+00E5 U+00AF U+0086 U+00E6 U+00B5 U+00B7 U+00E7 U+0087 U+0095 U+00F0 U+009F U+0091 U+00A8 U+00E2 U+0080 U+008D U+00F0 U+009F U+0091 U+00A9 U+00E2 U+0080 U+008D U+00F0 U+009F U+0091 U+00A7 U+00E2 U+0080 U+008D U+00F0 U+009F U+0091 U+00A7 U+0020 U+00E4 U+00B8 U+0080 U+00E5 U+00AE U+00B6 U+0020 U+00E8 U+00BF U+0099 U+00E6 U+0098 U+00AF U+00E4 U+00B8 U+0080 U+00E6 U+009D U+00A1 U+00E6 U+00B5 U+008B U+00E8 U+00AF U+0095 U+00E8 U+00AF U+0084 U+00E8 U+00AE U+00BA U+005B U+00E6 U+008D U+0082 U+00E8 U+0084 U+00B8 U+005D]
- utf-8 维度截取:👧👦@🌈�
- utf-16 维度截取:@🌈新密海燕👨👩👧👧 一家
- unicode 维度截取:海燕👨👩👧👧 一家 这是一条测试评论 IOS 和 Android 字符串都是 utf-16 编码,start\end 为 utf-16 维度的坐标。所以在截取字符串 [start,end) 时,应该先转成 utf-16 数组,再截取: textRune := []rune(param.Text) encodeText := utf16.Encode(textRune) // encode encodeUserName := encodeText[textExtra.Start+1 : end] decodeUserName := utf16.Decode(encodeUserName) // decode
为什么 👨👩👧👧 这种 Emoji 占用 7 个 unicode?utf-16 中占用 11 个码元?
- Emoji 是 Unicode 字符集的一部分。事物的组成方式:字节组合成字符编码单元(或者叫做代码点,unicode number),而字符编码单元组合成字形(视觉符号,visual symbols)。在 UTF-16 中,Emoji 的长度可能是 1 或 2 甚至更多。
- ⛱ :
- unicode:U+26F1
- utf-16:U+26F1
- 🌈 :
- unicode:[U+1F308]
- utf-16:[U+D83C U+DF08]
- 👨👩👧👧 = 👨+连接符+👩+连接符+👧+连接符+👧
- unicode:U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F467
- utf-16:U+D83D U+DC68 U+200D U+D83D U+DC69 U+200D U+D83D U+DC67 U+200D U+D83D U+DC67
- ⛱ :
在aweme.user.gouser 获取的用户昵称(nickname)中,为什么有乱码?需要如何处理?
- 在aweme.user.gouser 维护的用户信息中,历史用户的 nickname 中存储的数据是 HTML转义字符串(Escape Sequence),在上述示例中:
- ‘符号 的 HTML 特殊转义字符 实体编号为'
- &符号 的 HTML 特殊转义字符 实体名称为&
- 为了兼容历史数据,需要对 nickname 执行转义字符串解码: nickname := html.UnescapeString(nickname) MySQL 创建数据表时,指定的CHARSET=utf8 和 CHARSET=utf8mb4 有什么区别? utf8 最大仅支持三个 byte,因此仅能存储 BMP 字符,超出字符可能会错误或丢失,使用 utf8mb4 即可解决;
开发语言中 字符串 使用什么编码 ? Js 使用 UCS-2 编码方式;
uri 为什么需要 encode/encode ?
- 作用:将文本字符串编码为一个有效的统一资源标识符 (URI)。
- 一般来说,URI 只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。
- ”; / ? : @ & = + $ , #” 等保留符号在 URI 中有特殊含义,所以在表示这些符号本身时需要转义。
- 区别:
用途 不编码的字符 encodeURI 对整个URL进行编码 ASCII字母 数字 ~!()’@#$&=:/,;?+ encodeURIComponent 对URL的组成部分(如参数)进行编码 ASCII字母 数字 ~!()’
- 编码规则:
- 保留字符:把该字符的ASCII的值表示为两个16进制的数字,然后在其前面放置转义字符百分号(“%”)
- 非ASCII字符: 需要转换为UTF-8字节序列, 然后每个字节按照保留字符的方式表示
- 对百分号字符%:”%25”
参考
- 刨根究底字符编码之七——ANSI编码与代码页
- Unicode 与字符编码
- 彻底弄懂Unicode编码
- 关于字符编码的一些总结
- 数据编码与演化(Encoding and Evolution)
- 关于字符编码,前端应该知道的
- Emoji 简介