分区/分片(Partition/Shard):原来一个整体的数据,按照一定的规则拆分成多个分片数据。
以数据库表为例:
- 垂直分片:单表 10 个字段 N 行,拆分为两个 5 字段 2*N 行的表;
- 水平分片:单表 10 个字段 N 行,拆分为两个 10 字段 N/2 行的表;
垂直分片和早期微服务拆分思路类似,一个很大的系统,逐渐拆分为多个子系统,原来很多字段的表或者很多表的库,被随之拆分为多个表多个库。
水平分片主要解决单个节点读写负载过高的问题;当拆分为多个分片后,每个节点(机器)可以分别承受若干个分片的负载,从而支持水平扩展(通过加机器数量 而非 增加单机性能 提升读写性能);拆分后,哪些数据存在哪个节点上,这将具体的分片规则确定了。
垂直分片通常和业务层的紧关联的,本节余下内容主要指水平分片。
这里讨论的分区/分片,在不同的组件对分片有不同的称呼,它对应 MongoDB/ElasticSearch 等中的 Shard、Kafka中的 Partition、RocketMQ中的 Queue、HBase 中的Region、Bigtable 中的 Tablet、Cassandra 和 Riak 中的 vnode 等。
分片策略
简单的轮询
从客户端的角度看,一个简单的负载均衡策略就是轮询:比如四个分片0/1/2/3,第一次请求打到0,第二次打到1、第三次打到2、第四次打到3、第五次又打回0…
常见的队列(如RocketMQ、Kafka等)在生产者端,写入消息时就是使用这种方式。
如下图中的TopicA,共有四个分片,每个节点各有两个分片:
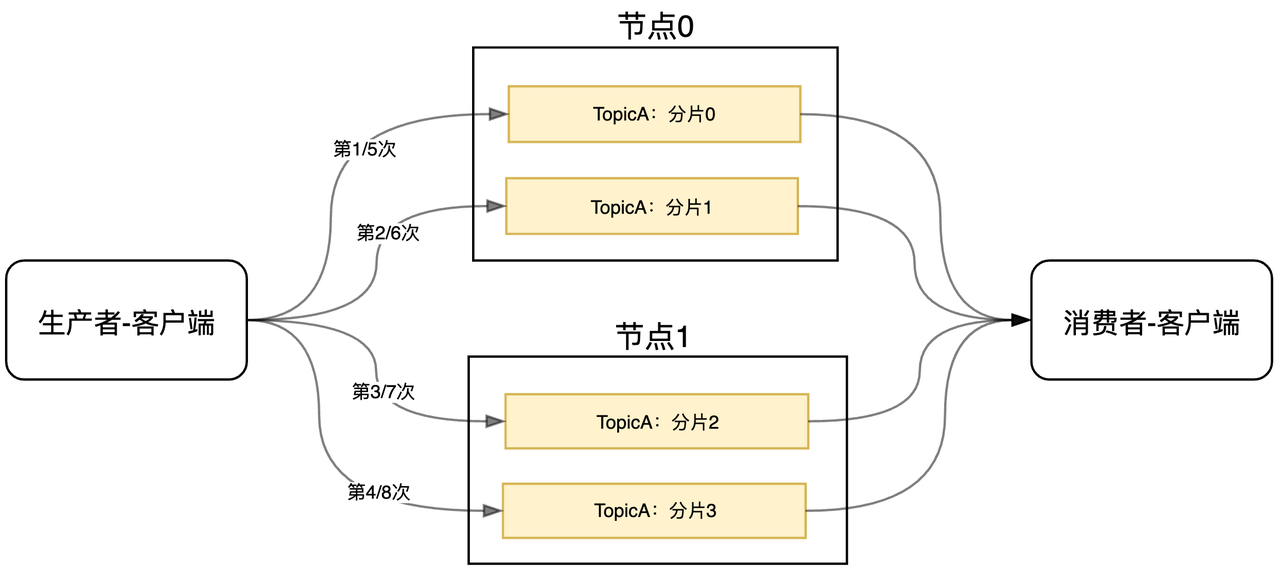
RocketMQ把分片叫队列(Queue),Kafka则叫分区(Partition);当支持轮询的负载策略时,往往意味着其他的负载算法也会支持(比如随机、一致性Hash等)
然而轮询对于一些存储场景并不合适,比如:
- 第一次请求:set name_a zhangsan,分片 1 记录了 KV 数据:name_a =zhangsan;
- 第二/三/四次请求:get name_a,这时轮询到了 分片2/3/4,这时是无法获取到数据的。
我们自然是希望数据A写入成功后,再来找A时,是可以正常找到的(无论是读还是更新),无论下游有几个分区/节点。而此时就可以考虑基于Hash的负载算法了
Hash分片
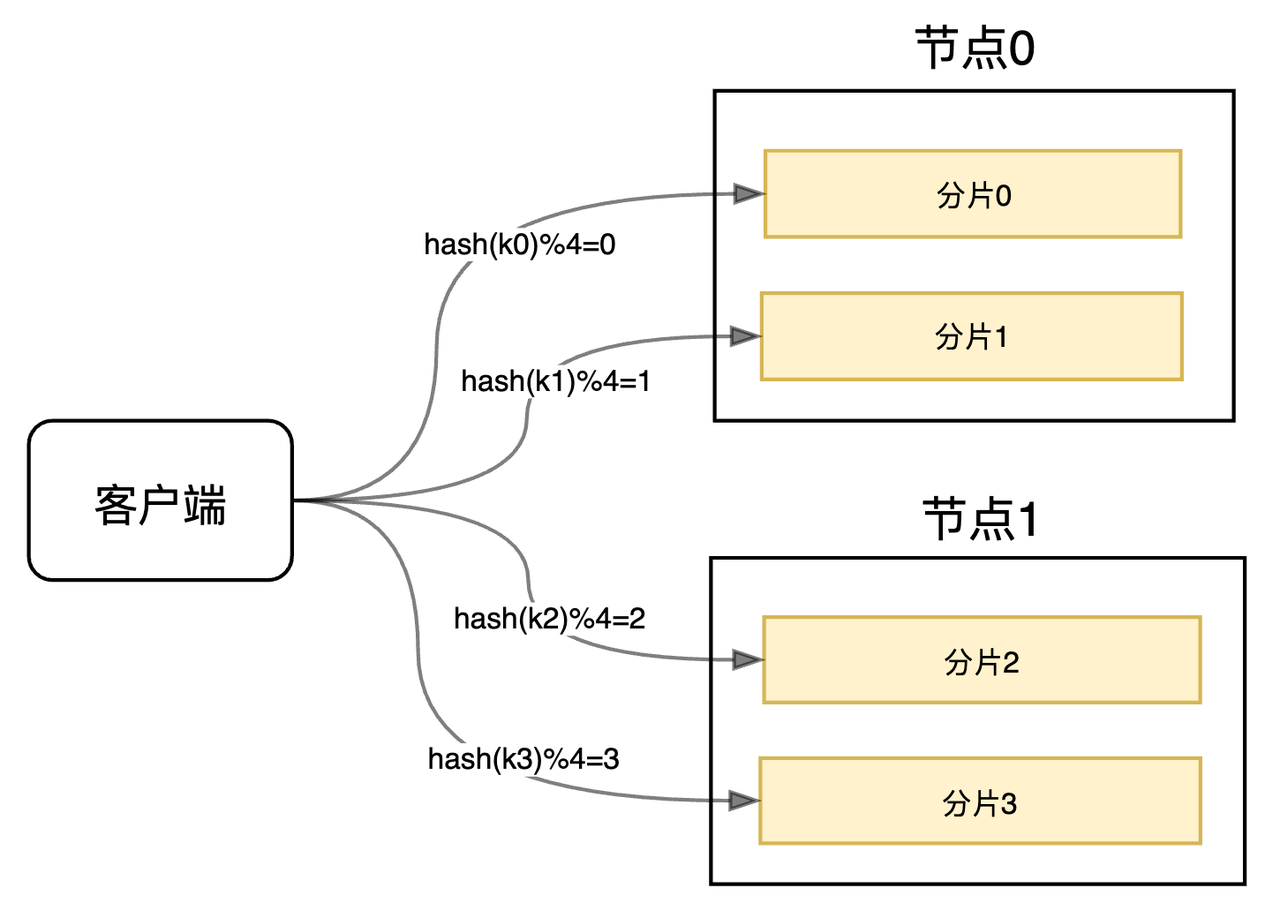
Hash取模:基于 Hash 的一个简单实现
- 第一次请求:
set name_a zhangsan,选择的分区为:hash("name_a") % (分区总数); - 第二次请求:
get name_a,选择的分区同样为:hash("name_a") % (分区总数);
这就保证了只要 key 一样,总是能打到同一个分区(节点)的。
这个Key通常被称之为分片键(Shard Key),它可以是关系型数据库的某个字段、KV数据库的Key、文档数据库中集合的某个字段等,我们将基于这个分片键确定它最终的归属(落到哪个节点)。
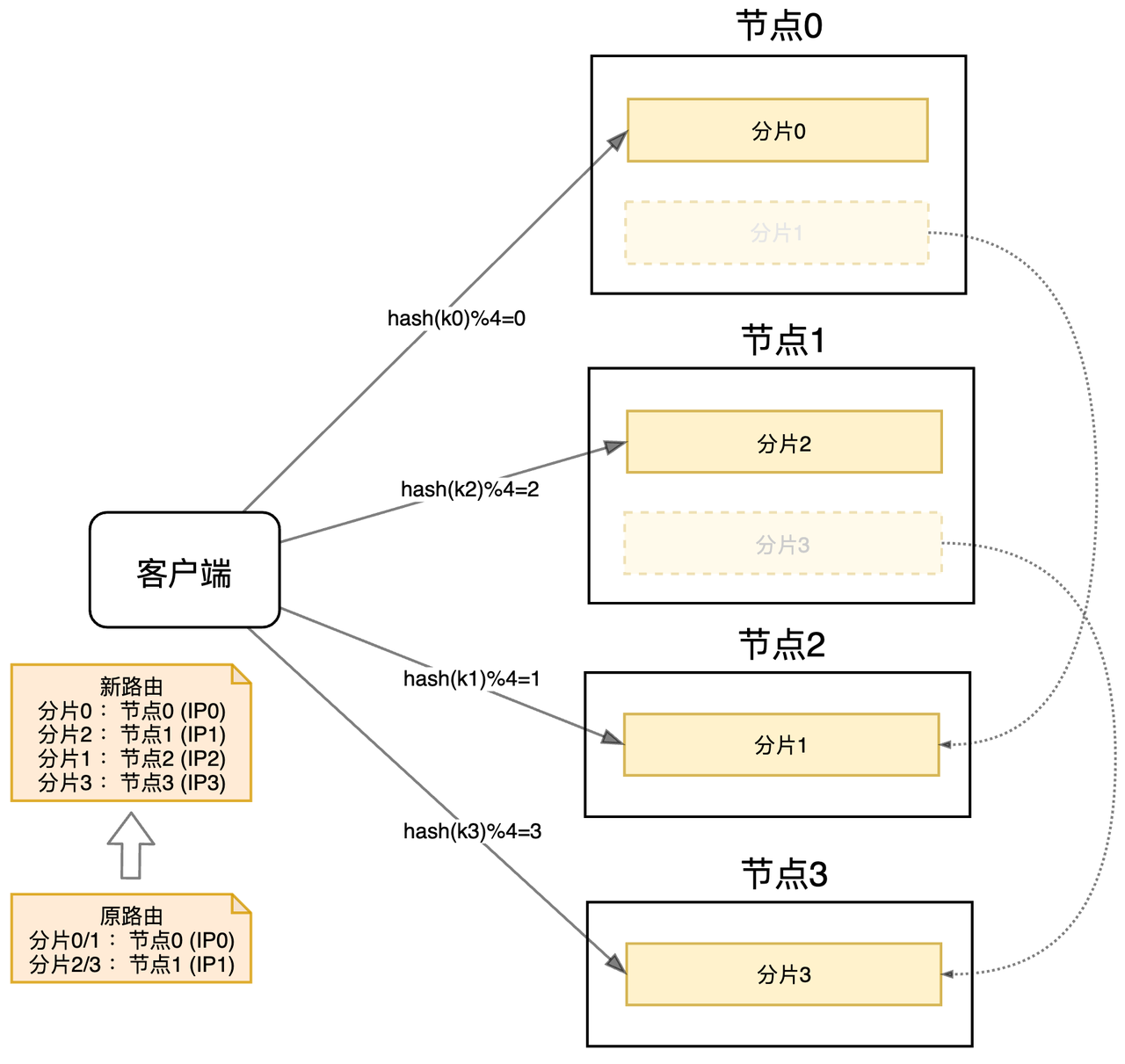
下面考虑下扩容的问题,当2个节点扛不住压力的时候,我们需要进行扩容,比如这里扩容到4个节点,我们只需要以分片为维度,将数据迁移到新节点即可(客户端需要更新分片路由)
工程实现上:
- ==MySQL 制定主机实例数(默认3)和分片数(默认101),其实就是一开始有101个库,用三台主机来抗,扩容时,再搞多几台主机,然后把库挂过去即可。==
- ==Redis Cluster:规定16384个分片(slot槽),只有全部分片 都分配了节点,Redis才正常服务;扩缩容时,也会有一个数据迁移的过程(MIGRATE)。==
如果四个节点后仍然扛不住负载呢?这时候只能增加分片数量了。 比如增加到5个分片,对应的节点数才能加到5个,这时候的数据迁移就不能以分片维度了,而要具体到所有分片中的记录维度了。比如分片0中的数据,我们将基于它的 分片键 进行迁移:
hash(Key) % 5 == 0:保持原来的位置;hash(Key) % 5 == 1:迁移至分片1;hash(Key) % 5 == 2:迁移至分片2;hash(Key) % 5 == 3:迁移至分片3;hash(Key) % 5 == 4:迁移至分片4; 同样地,分片1/2/3也要做相同的操作。显然这个迁移的成本会高很多,我们应该尽量避免。
举两个应用场景:
- MySQL早期没有做分片,一个库抗所有;后来规模变大后想做分片,此时会触发上述的迁移动作;
- 现在MySQL默认的分片为101片,假设101个主机实例都扛不住了,那只能再增加分片了,比如提到1000片,然后搞200个主机实例。
在一些场景下,以缓存系统为例,丢失部分数据是可以容忍的,这时就可以直接丢弃而非迁移了。但是我们希望丢失的数据尽量少。
在Hash取模中,扩容时,比如3个扩到4个,只有 hash(key)%3 == hash(key)%4 才能打到原来节点,只有1/4的key满足,数据丢失3/4,一致性Hash则可以帮我们尽量减少扩缩容的数据丢失。
优点
这种方式的突出优点是简单性,常用于数据库的分库分表规则。一般采用预分区的方式,提前根据数据量规划好分区数,比如划分为 512 或 1024 张表,保证可支撑未来一段时间的数据容量,再根据负载情况将表 迁移到其他 数据库 中。扩容时通常采用 翻倍扩容,避免 数据映射 全部被 打乱,导致 全量迁移 的情况。
缺点
当 节点数量 变化时,如 扩容 或 收缩 节点,数据节点 映射关系 需要重新计算,会导致数据的 重新迁移。
一致性 Hash
假设一个节点就是一个分片,这里简单介绍下一致性 Hash:
- 画一个Hash环,环上有
0~2^32-1个点(数); - 确定节点位置:
hash(节点IP+端口) % 2^32得到的数,即节点落在环上的位置; - 客户端请求时,
hash("name") % 2^32,也落在环上了,然后顺时针找到第一个节点即可;
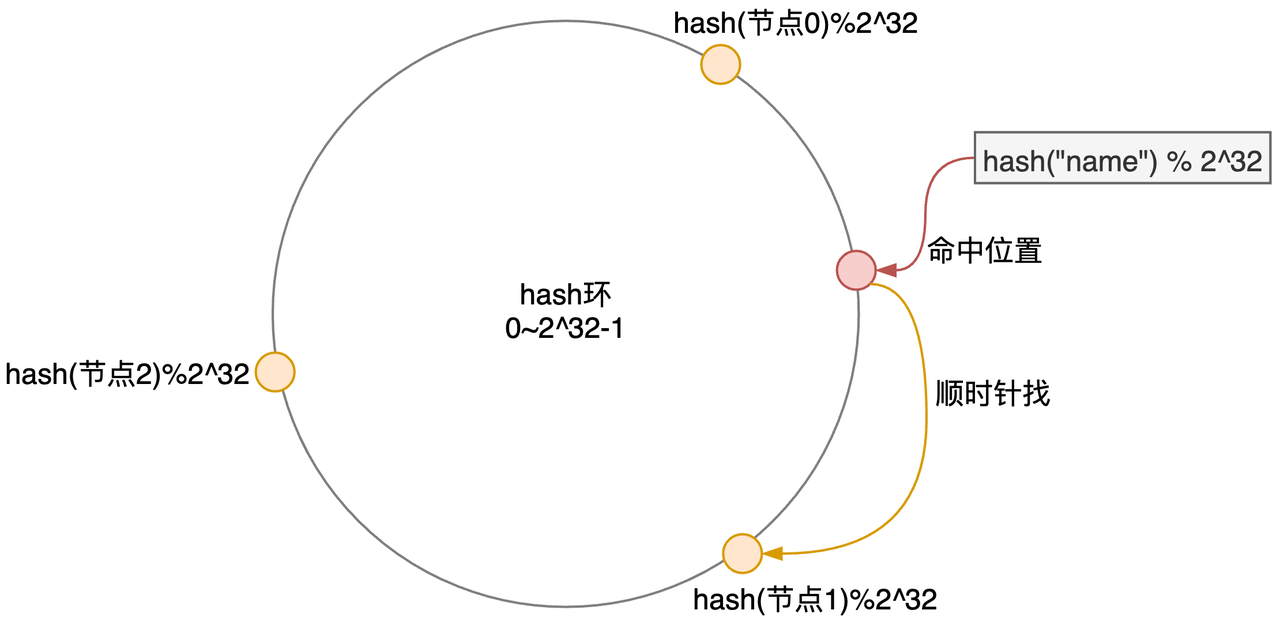
假设运气比较好,三个节点分布得比较均匀,一开始各占1/3的负载;
当扩容到第四个节点时,它落在了节点0和1的中间,此时仍然有 2/3 + 1/(3*2) = 5/6 的数据会找回原来的节点,这对于原来的1/4已经是一个很大的进步了;不过此时负载已经不太平衡了。
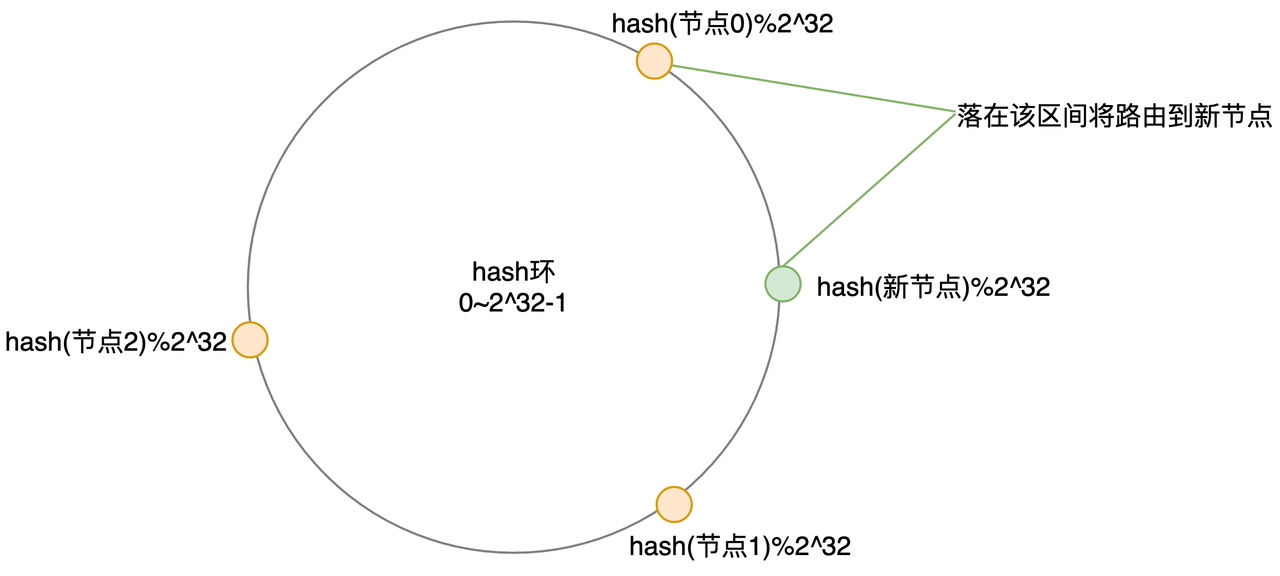
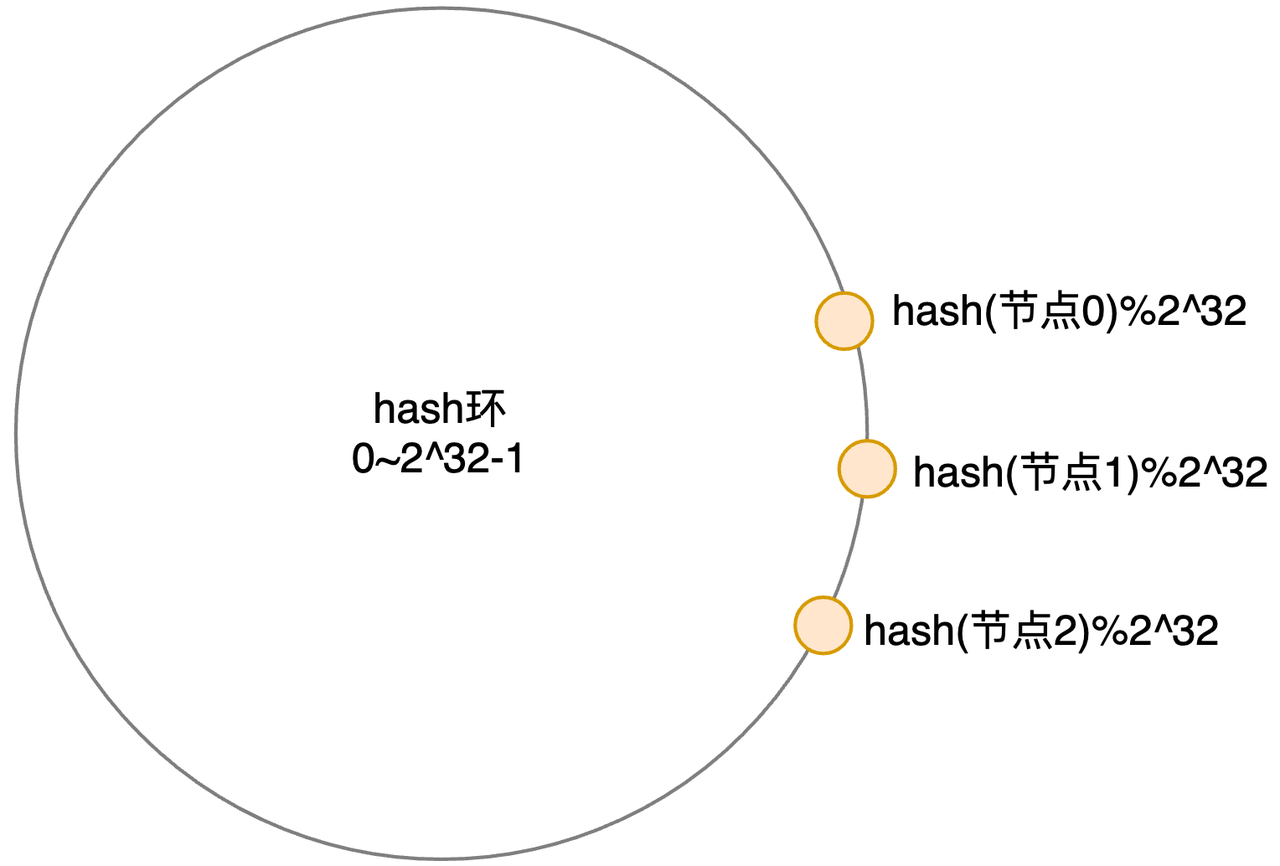
假设运气不太好,节点0/1/2挤在了一起,这个环从一开始就已经不平衡了(Hash倾斜):
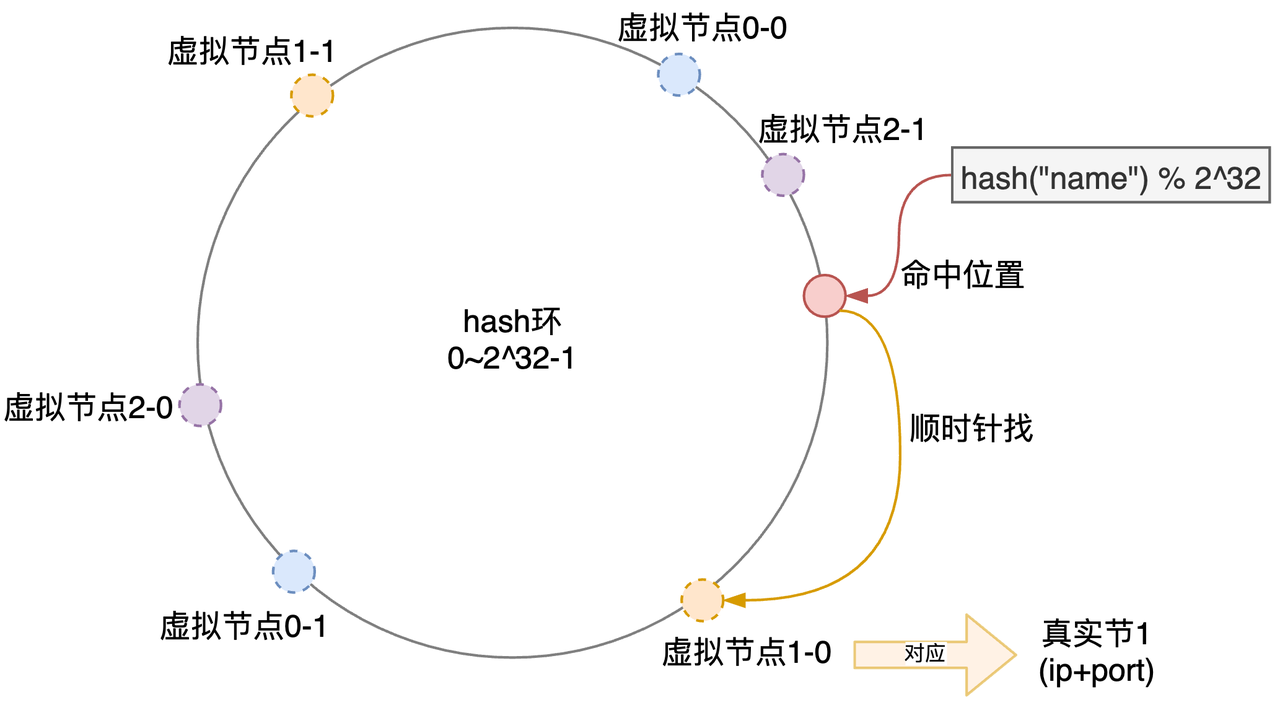
解决这个问题的方式是引入虚拟节点:
- 比如真实节点0负责两个虚拟节点:0-0和0-1;节点1/2也类似;
- 计算虚拟节点hash可以简单地:hash(ip+端口+序号) ,然后落到环上;
- 客户端请求时,先顺时针找到虚拟节点,然后就能找到真实节点了;
 尽管两个虚拟节点仍然有大概率出现倾斜,当有100个、200个,那出现倾斜的概率就大大降低了。
尽管两个虚拟节点仍然有大概率出现倾斜,当有100个、200个,那出现倾斜的概率就大大降低了。
因为虚拟节点近似的随机插入(环),扩缩容前后很大概率都是均衡的;理想情况下,当3个节点扩容到4个节点时,每个节点的负载是从1/3 变到 1/4的,即只有 1/4的数据丢失。
==虚拟槽分区 巧妙地使用了 哈希空间,使用 分散度良好 的 哈希函数 把所有数据 映射 到一个 固定范围 的 整数集合 中,整数定义为 槽(slot)。这个范围一般 远远大于 节点数,比如 Redis Cluster 槽范围是 0 ~ 16383。槽 是集群内 数据管理 和 迁移 的 基本单位。采用 大范围槽 的主要目的是为了方便 数据拆分 和 集群扩展。每个节点会负责 一定数量的槽。==
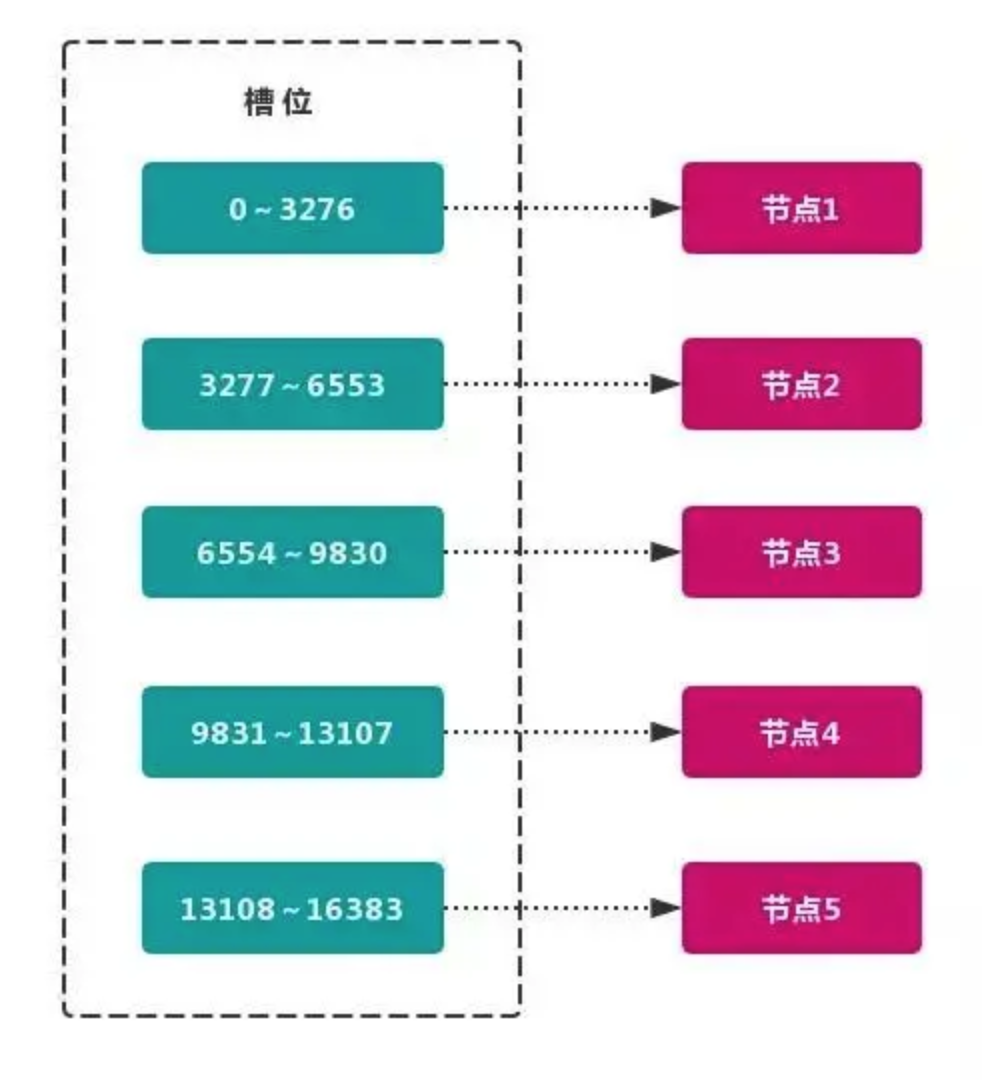
工程实现上:
- 早期基于哨兵的Redis,分片的一种实现方式就是一致性Hash,Redis服务端节点对分片是无感知的,请求都是来之不拒;Redis Cluster通过引入16384个槽(分片),初始时需要指定分片对应的节点。如果节点收到不是自己负责的分片数据的话(hash(key)%16384 = 第几个槽)。
- 一致性Hash是一种常见的负载均衡算法。
优点:
一致性哈希 可以很好的解决 稳定性问题,可以将所有的 存储节点 排列在 首尾 相接 的 Hash 环上,每个 key 在计算 Hash 后会 顺时针找到 临接 的 存储节点 存放。而当有节点 加入 或 退出 时,仅影响该节点在 Hash 环上 顺时针相邻 的 后续节点。
缺点:
引入虚拟节点之前,加减节点会造成哈希环中部分数据无法命中。当使用少量节点时,节点变化将大范围影响哈希环中数据映射,不适合少量数据节点的分布式方案。普通的一致性哈希分区在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的均衡。
因为 一致性哈希分区 的这些缺点,一些分布式系统采用 虚拟槽 对 一致性哈希 进行改进。
Range分片
Hash分片的一个问题是当进行范围查找时(比如 age < 18),需要遍历所有的分区。
Range分片,则是基于范围的分片,比如可以指定 age在[0, 20) 则落到 分片1、[20,40)则落到分片2、[40, +∞) 落到分片3。范围查找时,只需要在分片1中找即可。类似的还有:
- 基于时间进行Range分片,比如 每年/每月/每天 一个分片;
- 基于字符串首个字母分片,a-z共26个分片。 Range分片变化也会存在迁移的动作,这里不再赘述。
Range分片的问题是:
- 分区均衡有时候往往难以把握;比如上面的年龄/字符串/时间等,怎样分才能比较均衡?
其他
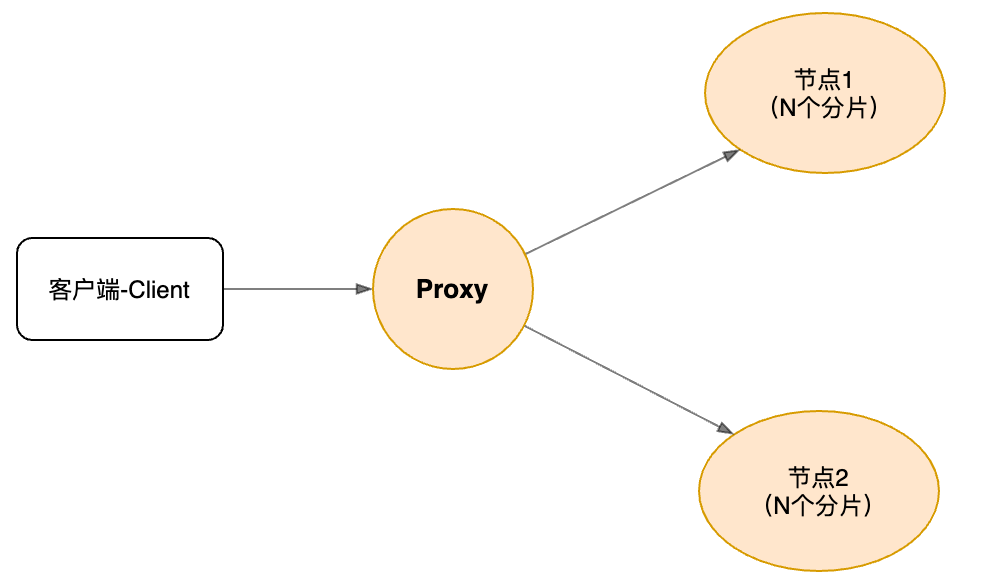
代理中间件(Proxy)
当分片数量、节点数量、节点主从切换、IP地址更新,客户端都需要感知并进行及时地更新;另外对于跨分片的范围查找、排序、分组、读写分离等操作,客户端也要自己做相关的聚合操作等,这些都是比较重的活。再考虑Go、Python、Java等多种编程语言,如果将这些逻辑以lib包的形式直接放到业务层代码的话,开发和维护成本都会比较高,一种合理的方式是 在业务层 和 存储层之间加入一层中间件:即代理(Proxy)中间件。
加入Proxy后,从业务层的角度看,存储层就是一个整体了(看起来好像只有一个库),这对于业务层开发是很友好的,尽管加入了一层转发损耗:
 再考虑上包含主从节点下的读写分离,我们可以将Proxy分为两种类型:
再考虑上包含主从节点下的读写分离,我们可以将Proxy分为两种类型:
- 写Proxy:对于写请求,分片后,转发到主节点。
- 读Proxy:对于读请求,分片后,转发到从节点。
以下是一个较为完整的架构了:
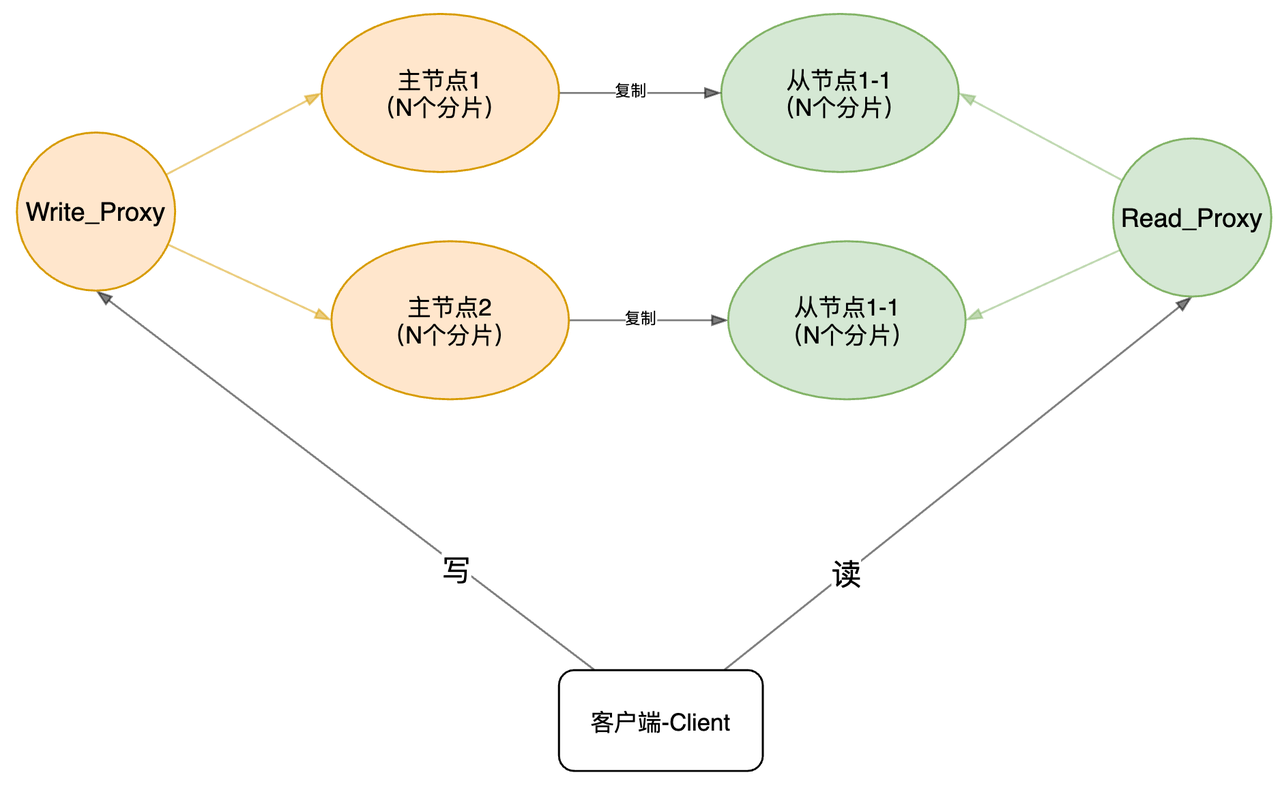
读/写Proxy本身是无状态的,可以部署多个,且随意扩展;客户端只需要感知这些Proxy的地址,进行简单地轮询/随机等访问即可,这块逻辑通常以lib的方式嵌入业务层(如MySQL_Driver),lib的逻辑相对会比较轻。
读写分离后,读延迟是个值得关注的问题。
- 读从库时,无论是异步、半同步、过半成功等,短时间的延迟也是会存在的(一般是毫秒级);
- 如果有强一致的需求,可以选择读主库.
分区再平衡
数据和对应读写请求 从一个节点的迁移到另外一个节点的迁移过程,被称之为分区再平衡(或动态平衡),如上面提到的 分片时的迁移 。
触发再平衡的原因通常有:
- 查询压力增加,因此需要更多的 CPU来处理负载;
- 数据规模增加,因此需要更多的磁盘和内存来存储数据 ;
- 节点故障,因此需要其他机器来接管失效的节点;
无论什么分区方案,分区再平衡通常需要满足:
- 平衡之后,负载、数据存储、读写请求等应该在集群范围 更均匀地分布。
- 再平衡执行过程中,存储组件 应该可以继续正常提供读写服务;
- 避免不必要的负载迁移,以加快动态再平衡,并尽量减少网络和磁盘I/O影响。
分区与二级索引
我们可以基于分片键进行分区,而 某个分区内部,仍然可以进行二级索引构建。
比如我们现在有个销售汽车的网站,其汽车基于文档ID进行分区,而内部有个颜色(Color)的二级索引;当基于颜色读取时,则需要访问所有的分区,然后进行聚合。
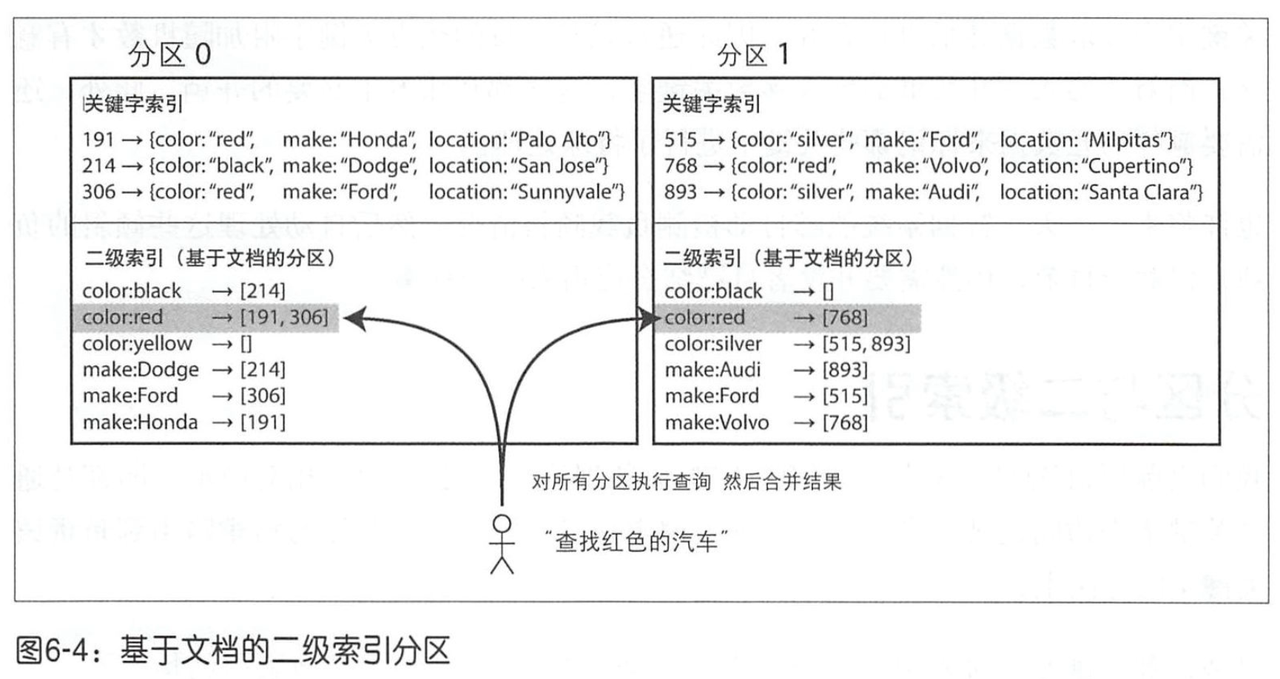 以上这种查询分区数据的方法有时也称为 分散/聚集(scatter/gather)。
以上这种查询分区数据的方法有时也称为 分散/聚集(scatter/gather)。
另外一种实现二级索引的方式是 针对所有数据 构建 全局索引(而不是 每个分区各管各的),如果上面的color:red 对应的所有 文档id,都集中在某个节点上:即 color:red -> [191,306,768];
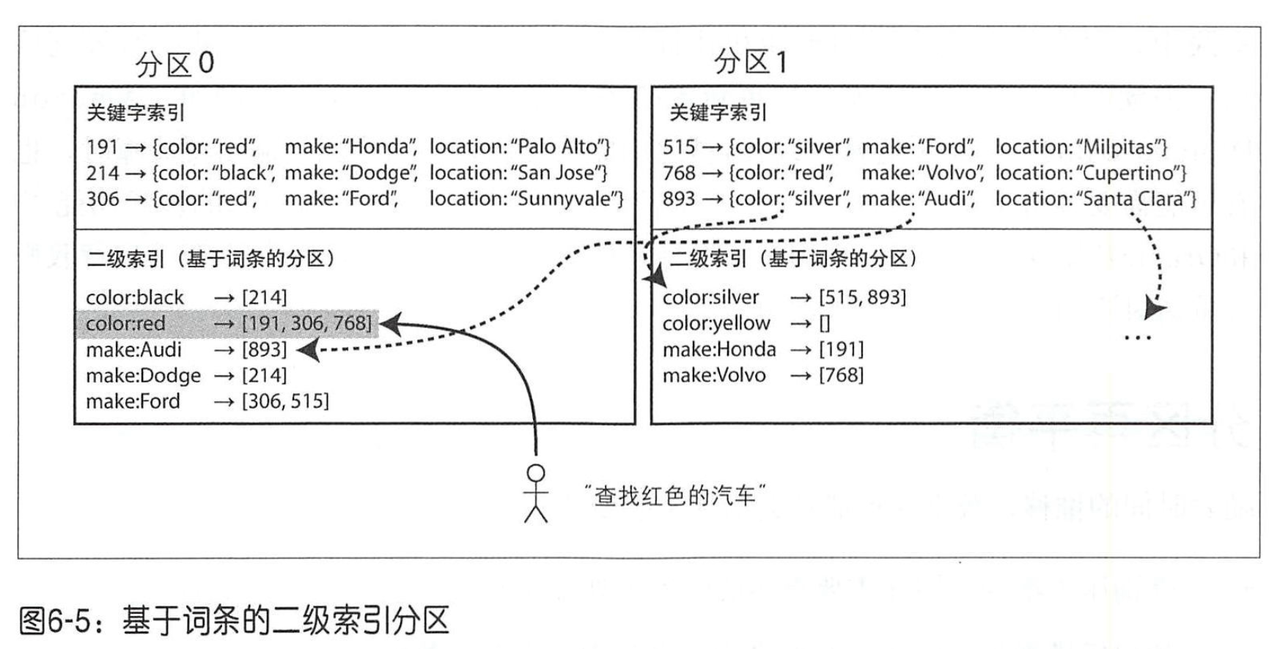 至于哪种颜色的索引数据放在哪个分区上,同样参考上面的分片策略:如从 a到r开始的颜色 放在分区0中,从s至z的颜色放在分区1中。
同样地,客户端可以根据这个规则进行路由,读取时,直接访问颜色对应分区,找到所有文档ID,然后读取ID对应的分区即可,而不需要访问所有的分区。
尽管读取时比较高效,但是写入逻辑将会变得复杂(效率可能也会受到影响);比如更新索引时,可能需要操作多个索引分区(比如 red -> yellow),且可能会因为失败导致数据不一致,需要补偿等。
至于哪种颜色的索引数据放在哪个分区上,同样参考上面的分片策略:如从 a到r开始的颜色 放在分区0中,从s至z的颜色放在分区1中。
同样地,客户端可以根据这个规则进行路由,读取时,直接访问颜色对应分区,找到所有文档ID,然后读取ID对应的分区即可,而不需要访问所有的分区。
尽管读取时比较高效,但是写入逻辑将会变得复杂(效率可能也会受到影响);比如更新索引时,可能需要操作多个索引分区(比如 red -> yellow),且可能会因为失败导致数据不一致,需要补偿等。
负载倾斜与热点
尽管基于Hash分片等方法可以减轻热点,但是仍然无法完全避免。一个极端的情况下,绝大多数的读写都针对某一个关键字,最终仍然会路由到同一个分片,这时候做横向拓展仍然是无法解决问题的。
比如微博中某个明星出现绯闻,大家都跑过去评论,导致大量的写操作(评论可能是明星的用户id、或者评论事件的ID等),因为都是同一个ID,Hash后的结果仍然是一样的。 大多数的系统仍然无法自动消除这种高度倾斜的负载,而是通过应用层(或Proxy层)来减轻倾斜程度,一个可能的方案为:
- 写时:针对热点Key,在Key后面增加 一个随机数(0-99),从而通过Hash路由到下游的100个分片;
- 读时:读取该Key的所有100个分片,然后进行合并后再返回结果;这意味着读取时效率将受到影响,且逻辑也会非常复杂。
除了写热点,还有读热点,如Redis中某个Key出现极高的读频率,这时同样会打到某个分片上;解决的方案可以为:
- 加后缀,见上面的写热点解决方案;
- 读写分离时,可以临时增大某个分片(1 Master-N Slave)的从节点数量,增大读负载;
- Local Cache,访问路径可能为 应用层 -> Proxy层 -> 分布式缓存(如Redis) -> DB;每一块都可以进行缓存(尤其是无状态的应用层/Proxy层,弹性伸缩容易);当然前提是要 考虑好 数据一致性的问题(读到过期的数据对用户的影响)。
这里顺带一提,有些热点的爆发是无法预料的,瞬时的高流量是来不及自动扩容的;所以一些服务的过载保护就显得尤为重要:即哪怕我直接拒绝部分流量,也不能让服务被冲垮,导致完全不可用。