数据库=数据模型+查询语言
数据模型发展历史
- 1965年:网络模型(Network Model)数据库——IDS发布;
- 1968年:层级模型(Hierarchical Mode)数据库——IMS发布;
- 1970年:Edgar Codd发表关系模型(Relational Model)论文;
- 1974年:IBM基于Codd的概念,开发原型系统System R;
- 1978年:标准化的查询语言——SQL(Structured Query Language)诞生;
- 1979年:关系型数据库——Oracle Release 1 发布;
- 1985年:对象模型(Object Model)发布;
- 1995年:开源的关系型数据库——MySQL Sybase IQ发布;
- 2007年:图数据库(Graph DataBase)——NEO4j发布;
- 2009年10月:KV模型(Key-Value) 数据库——Redis发布;
- 2009年11月:文档模型(Document Model)数据库——MongoDB发布;
- 2011年:宽列存储模型(Wide column)数据库——HBase稳定版发行;
层次模型
较早期的层次模型(IMS)将所有数据表示为嵌套在记录中的记录(树结构),可以很好地支持一对多关系,而多对多关系则有些困难;为了解决层次模型的局限性,业界提出了很多解决方案,比较著名的有关系模型(relational model)和网络模型(network model);
网络模型
网络模型(CODASYL)是在层次模型的基础上,其子节点支持多个父节点,从而形成一个网状结构;和层次模型一样,节点可以嵌套的类型 是固定的;而获取特定记录需要遍历其中一条访问路径才行(没办法直接定位到);
关系模型(SQL)
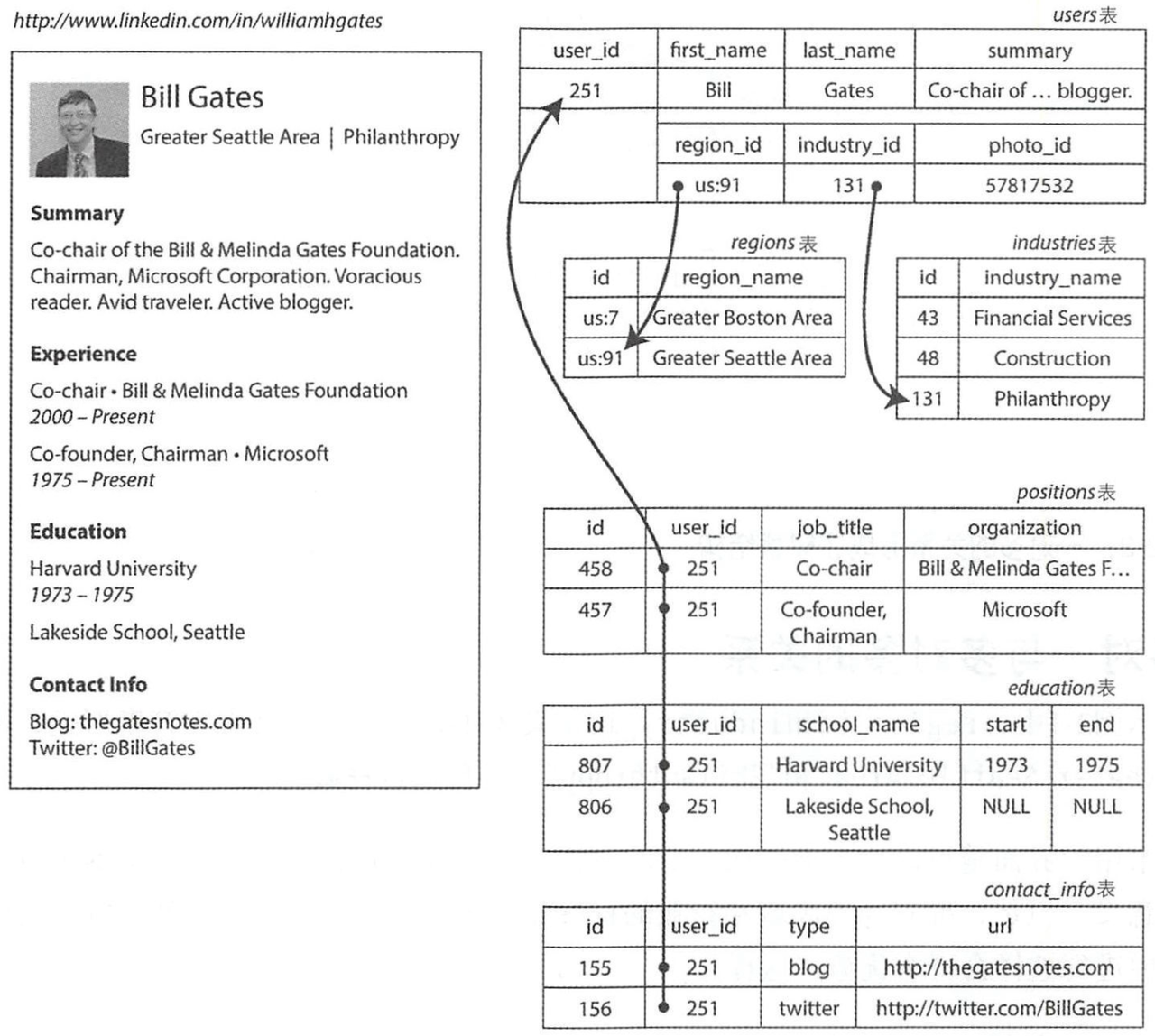
定义:关系模型是指用二维表的形式表示实体和实体间联系的数据模型。
特征:
- 关系模型有坚实的设计理论和运算基础,在近三十年内一直处于主导地位。
- 数据被组织成关系(relations),在 SQL 中关系称之为表-table、关系中的元组(tuples)被称之为行-row。
- 关系必须是规范化的关系,即每个属性是不可分割的实体,不允许表中表的存在。
- 查询语言 SQL 已经一统江湖成为标准。
- 支持丰富的关系联结(1 对 1、1 对多、多对多)和事务处理。
优点:
- 普及度高;关系型数据库无论在 大学教学 还是工程应用覆盖率都很高;
- 概念简单,操作方便;
- SQL高度抽象,屏蔽了底层复杂的逻辑,操作数据非常简单;
- 支持一对一、一对多、多对多等复杂关系;联表查询也十分方便;
- MySQL、Oracle等对单机事务有成熟的支持;
缺点:
- 横向拓展支持不成熟;引入中间件做分片则会损失一定性能,或丢失部分功能(如事务);
- 支持多对多时,需要引入第三张表
- 严谨的Schema要求,维护表结构会有一定成本;
在面向对象编程时,对于关系表数据,需将代码中的对象与表、行和列的数据库模型之间需要一个转换层。对象关系映射(ORM)框架减少了此转换层所需的样板代码量,但是并不能完全隐藏两个模型之间的差异。
关系模型的目标就是将实现细节隐藏在更简洁的接口(SQL)后面。
图模型
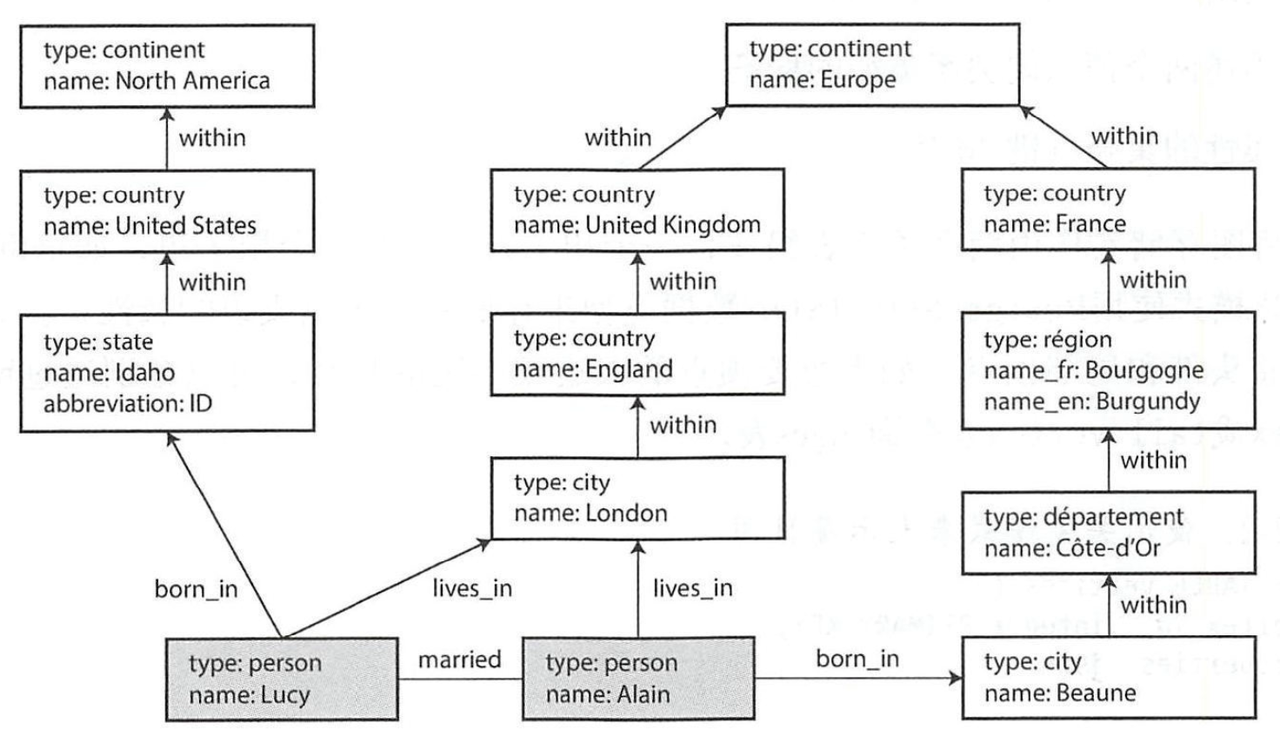
定义:用有向图表示 实体和实体之间 的联系的数据结构模型称为 图模型。
特征:
- 节点之间的关联通常没有约束,想联则联;
- 可根据唯一id定位任意节点;
- 属性图:
- 每个顶点包含:唯一标识符、出边集合、入边集合、属性的集合(键值对)
- 每条边包含:唯一标识符、边开始/结束顶点、描述两个顶点间关系类型的标签、属性的集合(键值对)
优点:
- 可以更加方便自然 地表示复杂的多对多数据模型;
- 遍历高效:给定某个顶点,可以高效地得到它的所有入边和出边,从而遍历图。
- 节点较为独立,可以随意删除和增加,而无需像层次模型那样级联动作;
- 通过对不同类型的关系使用不同的标签,可以在单个图中存储多种不同类型的信息,同时仍然保持整洁的数据模型。
- 支持图相关概念的查询,如简单路径、最短路径等;
缺点:
- 图模型是一种导航式的数据模型,操作路径和记录目标数据较为复杂;
- 图查询语言较多,尚未有很好的统一;
- 成熟的开源实现较少,多为公司自研。
图模型(Neo4j/ByteGraph)和网络模型有着相似的特点,但是更加灵活。任何节点之间均可以建立连接(边);只需要有唯一ID即可确定起始节点;现已称为主流的数据模型,以更加自然快速地应对复杂的多对多关系。
文档模型
定义:文档模型是用树状结构来组织数据的数据模型。
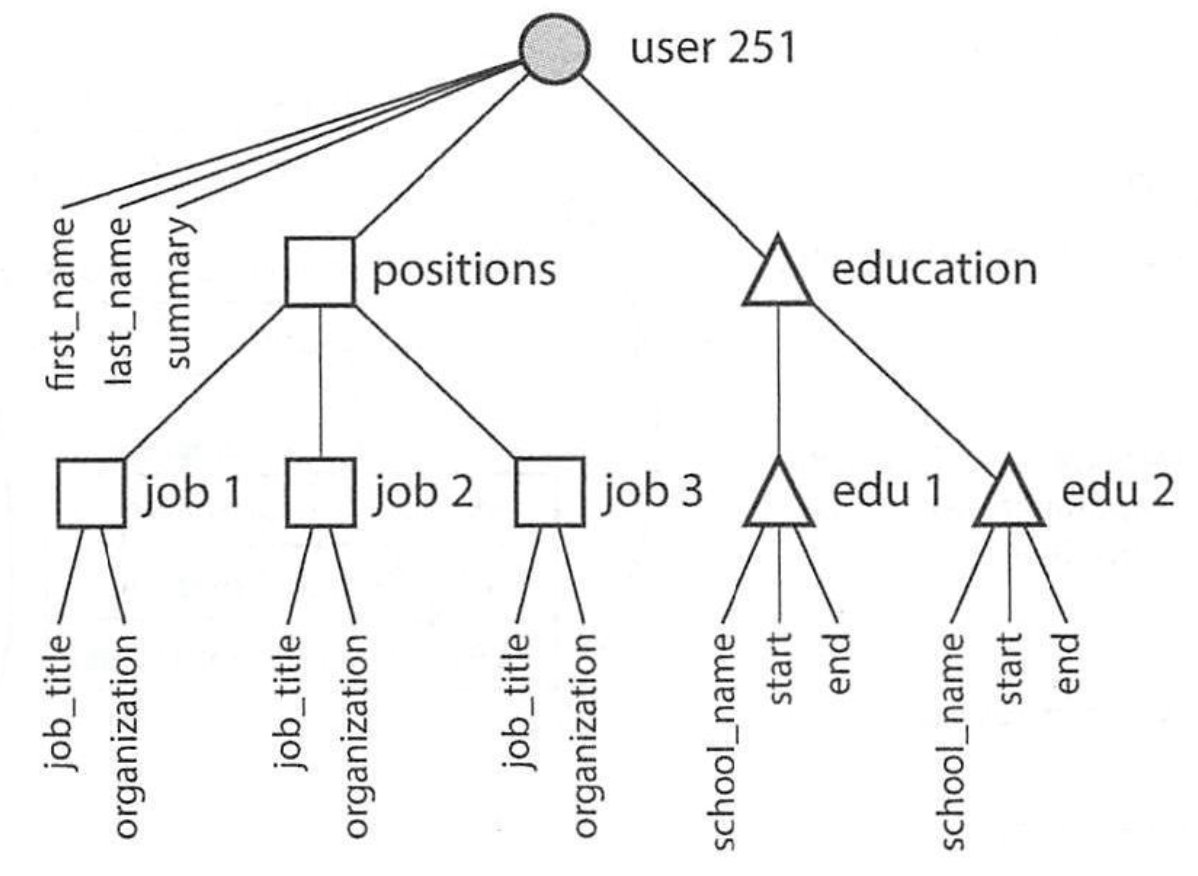
特征:树的性质决定了树状数据模型的特征
- 一棵树(如单个文档记录)中,除了根节点其他节点都要有一个父节点;
- 子节点不能脱离父节点而单独存在;删除父节点时,子节点也要同时删除;
- 每个记录类型有且仅有一条从父节点通向自身的路径;
- 可以使用XML/JSON等格式表示树结构并进行存储。
优点:
- 结构简单清晰,很容易看到各个实体之间的联系;
- 数据完整性高,父节点删除,子节点也删。
- 查询效率较高,单次查询可以拉取整棵树的数据,无需额外的联结动作;
- 操作数据库语句简单,学习成本低;
- 增减字段无需修改Schema(以MongoDB为例),降低运维成本。
- 支持超大数据集或超高写入吞吐量。
缺点:
- 数据结构较为呆板(一颗树状结构),灵活性不够
- 更适合1:N的数据模型,对于M:N的复杂关系表示并不方便;
- 查询节点的时候必须知道其双亲节点的,因此限制了对数据库存取路径的控制。
伴随着各个数据库的发展,关系型数据库(如MySQL 5.7、PostgreSQL 9.3)等已经开始支持JSON类型的字段;而文档型数据库(如MongoDB)则逐渐开始支持联结(联表查询)、事务等;关系型数据库和文档型数据库变得越来越接近,选型时也可以将这些新特性纳入考虑范围。
KV模型
KV模型(Redis/Memcached)Key-Value是最简单的数据模型,虽然无法和关系型/图等数据库一样支持复杂的关系,但是正因为简单的模型,Key-Value数据库往往有着更加优秀的性能。
Search engine
Search engine(Elasticsearch)搜索引擎数据库,专注于全文搜索(如日志搜索);
Wide column
Wide column(Cassandra/HBase)宽列存储,专注于OLAP(On-Line Analytical Processing)
Time Series
Time Series(InfluxDB)专注于时间序列的记录存储和分析(如打点记录)
数据查询语言
查询语言主要分两种类型:(1)命令式(2)声明式
命令式查询语言
IMS(层次模型)和 CODASYL(网状模型)都是命令式查询语言。 命令式语言告诉计算机以特定顺序执行某些操作。你完全可以推理整个过程,逐行遍历代码、评估相关条件、更新对应的变量,甚至决定是否再循环一遍。
例子:如果有一个动物物种的列表,可能会写这样的代码来查询列表中的 鲨鱼(Shark): function getSharks() { var sharks = []; for (var i ; i < animals.length; i++) { if (animals[i].family ===”Sharks”){ sharks.push(animals[i]); } } return sharks; }
命令式语言是比较接近底层的语言,可能需要考虑的问题:
- 如果数据库想要在后台回收未使用的磁盘空间,则可能需要移动记录,从而改变动物列表的顺序。这种情况下,数据库能否在 不中断查询的情况下 安全地 执行此类操作?
- 数据库 无法确定 命令式语言写出的 代码是否 需要依赖于排序,对这些代码优化的空间较小;
- 如何合理地支持并发执行?
声明式查询语言
SQL 是典型的声明式语言,它不需要知道底层的具体操作,只需要声明要取的数据即可。 声明式语言 较于命令式的 优势:
- 比命令式 API更加简洁和容易使用;
- 高度抽象,屏蔽了许多底层东西:
- 可以在不改变目标的前提下,进行各种优化(查询优化器)
- 引擎底层可以对并发有更好的支持;
混合风格-MapReduce
MapReduce 是一种编程模型,用于在许多机器上批量处理海量数据。MapReduce 既不是声明式查询语言,也不是一个完全命令式的查询语言,而是介于两者之间:查询的逻辑用代码片段来表示, 这些代码片段可以被处理框架重复地调用。它主要基于许多函数式编程语言中的 map( 也称为collect)和 reduce(也称为 fold 或 inject)函数。
Map 和 Reduce 函数对于可执行的操作有所限制。它们必须是纯函数,这意味着只能使用传递进去的数据作为输入,而不能执行额外的数据库查询,也不能有任何副作用。这些限制使得数据库能够在任何位置、以任意顺序来运行函数,并在失败时重新运行这些函数。不管怎样,该功能非常强大,可以通过它来解析字符串、调用库函数、执行计算等。
例子:
- 添加记录:你是一名海洋生物学家,每当你看到海洋中的动物时, 就会在数据库中添加观察记录;
- 生成报告:看下每个月看到了多少鲨鱼。
使用SQL:
1
2
3
4
SELECT date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations WHERE family= 'Sharks' -- 过滤
GROUP BY observation_month; -- 根据月份分类
使用 MongoDB中 的 MapReduce:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
db.observations.mapReduce(
function map() {
var year = this.observationStimestamp.getFullYear();
var month = this.observationStimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals);
},
function reduce(key, values) {
return Array.sum(values);
},
{
query: { family : "Sharks" }, // 过滤
out: "monthlySharkReport"
}
);
MongoDB 2.2+ 支持了增加了称为 聚合管道(aggregate) 的 声明式查询语言的支持:
1
2
3
4
5
6
7
8
9
10
db.observations.aggregate ([
{ $match: { family: 'sharks'}},
{ $group: {
_id: {
year: { $year: "observationTimestamp"},
month: { $month: "observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
}}
]);
聚合管道在表达能力上相当于SQL的子集 ,但是它使用了基于JSON的语法,而不是SQL的英语句式语法。或许这种差异仅仅是个品味问题。然而这个故事的寓意是,NoSQL系统可能会发现自 己意外地重新发 明了 SQL,尽管是伪装的。