背景
连接独占线程模式和C10K问题
早期的网络程序链接数目和QPS比较低,一个进程或者线程会处理一个网络请求。 随着技术的发展,互联网不再是单纯的浏览万维网网页,逐渐开始与用户进行交互。而且应用程序的逻辑也变得更复杂:从简单的表单提交到即时通信和在线实时互动。每一个用户都必须与服务器保持TCP连接才能进行实时的数据交互。当进程或者线程由于IO阻塞的时候,操作系统就会进行线程或者进程的切换。
线程或者进程切换会带来大量的系统开销和上下文切换成本,导致严重的系统开销。
- 切换进程系统开销:
- 切换虚拟地址空间;
- 切换内核栈;
- 切换硬件上下文;
- 进程或者线程切换后,会导致一段时间程序运行速度大幅度变慢:
- 丢失寄存器中的内容
- CPU cache失效:现代cpu速度提升很大一部原因是因为Cache的引入。
- TLB 快表失效(所有的内存操作时间翻番直到TLB加载完成)
| 存储类型 | 耗时 |
|---|---|
| L1 cache | 0.5ns |
| L2 cache | 7ns |
| 内存 | 100ns |
C10K 问题 一个服务器多线程方式处理10K个连接后,线程切换成本会变得十分巨大,性能会急剧下降。 从经验上看,不考虑互斥逻辑情况下,多线程每次切换需要3-5微秒的上线文切换代价和1微秒的cache同步代价。简单的echo程序,处理一个请求需要200~300ns,在单核的 docker 上可以处理 300-500 万请求;在 24 核的如果考虑切换,单线程的处理能力会降至10万,整体性能会降低到240万。
非阻塞IO和IO多路复用 为了减少频繁切换线程或者进程造成的开销,互联网程序逐渐采用IO多路复用的方式。 IO多路复用(又称事件驱动驱动):一个进程可以同时处理多个IO事件,同时监听多个套接字。进程可以在一个套接字上注册事件,当套接字可读或者可写的时候触发事件的执行。 不同的操作系统提供了不同的系统调用以实现IO多路复用:linux上的Epoll、unix上的kqueue、Windows的iocp。Java 的NIO也基于IO多路复用。 典型的IO多路复用编程模式为状态机模式:
- 专门的线程(或者进程)采用IO多路复用的模式负责批量的处理网络IO,实现吞吐量最大化;
- 专门的线程(或者进程)负责处理请求;
- IO线程通过消息队列或者其他的方式将请求发送给业务线程; 状态机模式最早的实现采用了异步编程的模式,每次请求可以当做一个状态机,状态机收到请求后,执行对应的操作同时切换状态。
优点:Reactor模式可以极大的提升程序的处理效率。 缺点:异步编程模式,编程效率会大幅度降低。
协程
协程并不是新的概念,早在1958年,协程的概念就被提出。协程就是一个子任务,协程的特点是非抢占式的调度,协程需要自己判断运行状况,当满足一定的条件,协程会自己主动的让出 CPU 给其他的协程(go1.14之后变为抢占式),而进程或者线程的切换需要进入内核态交给内核处理。以 Linux 为例,Linux中采用轻量级进程作为线程,进程和线程唯一区别是线程之间拥有同样的内存空间。
一个协程中的信息:运行栈+寄存器数值。
协程运行栈在进程堆区上分配。运行栈和寄存器信息保留了协程的运行信息。寄存器的值和协程栈决定了程序当前在代码中的执行位置。
- PC: 指向了下一条执行的代码位置,可以使用 jmp 命令修改。
- BP: 当前函数栈帧的起始位置,用于定位函数参数以及函数内定义变量的位置。
- SP: 当前函数栈帧的结束位置,下一个函数栈帧的起始位置。 PC 决定了当前代码的位置,BP、SP 决定了当前函数之前的函数调用情况和函数内定义的局部变量的具体数据。 与线程或者进程相比,协程切换开销很小,几乎可以忽略不计。
为什么协程早期没有流行起来: 计算机上不同的任务是不一样的,有的是 io 密集,有的需要及时响应,有的需要高吞吐,不同类型的任务做到彼此配合 很困难。开发一个任务,需要对其它任务了解。早期线程和进程数目实际不会太多,实际线程切换数目不会太多,用协程的收益不太明显。 而对于互联网服务来说,主要是微服务+高并发模式,相比于传统的应用,更加有收益。
goroutines
go 在语言层次实现了协程,特点:
- 语言层面上 hook 了阻塞的操作,阻塞操作中实现了协程切换;
- runtime 实现了 work-stealing 算法,实现协程在不同的线程上切换,M 个协程可以运行在 N 个线程上;
- 实现了协程的抢占式调度(go1.14之后);
goroutine状态
一个 goroutine 在生命周期中有以下几种状态:
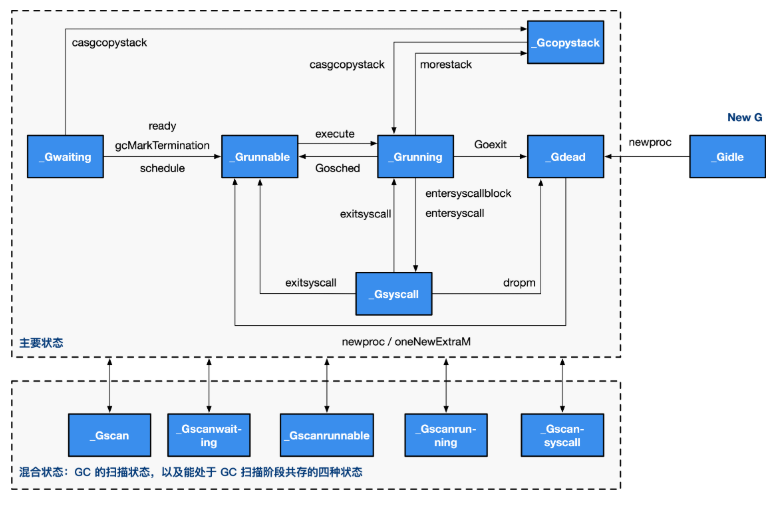
_Grunning、_Grunnable:
- _Grunning:程序正在被运行。
- _Grunnable:程序可以被执行。 Go 采用了一种被称为 GMP 的模型调度、运行协程。
- 当协程状态由其他状态变为 _Grunning 的时候,runtime 将协程交给 GMP 来管理;
- 当 GMP 执行某个协程,协程状态变为 _Grunning;
- 如果执行中的协程的时间片到了或者调用了
runtime.Goshed,协程会变为 _Grunnable 等待重新调度;
_Gsyscall: 部分系统调用会导致线程阻塞。进入阻塞的系统调用的时候,go 的 runtime 会将协程状态设置为 _Gsyscall,移除GMP调度模型。线程从阻塞的系统调用返回的时候,runtime重新将协程加入GMP调度模型中。为了保证程序的并发数目,当一个线程进入阻塞的时候,runtime会新建一个协程绑定P。
_Gowaiting: 当正在执行的协程由于网络IO、chan、time、sync阻塞的时候,runtime将协程移除GMP模型的同时会将协程的状态设置为_Gowaiting。当条件满足后,runtime会将协程状态改为_Grunable,继续有GMP管理。
_GocopyStack: Golang 的协程的调用栈初始化为 2KB,与 C++ 不同,golang 在编译的时候会进行逃逸分析,当一个变量可能被取指针的时候,那么这个变量会在堆上分配,这样做的原因是golang中的堆栈会发生拷贝,这就会导致golang栈上地址运行时发生变化。
当运行时runtime发现协程的栈不够时,就会重新分配栈,此时协程的状态为_GocopyStack,分配完后,重新放入Global Queue。
GMP调度器
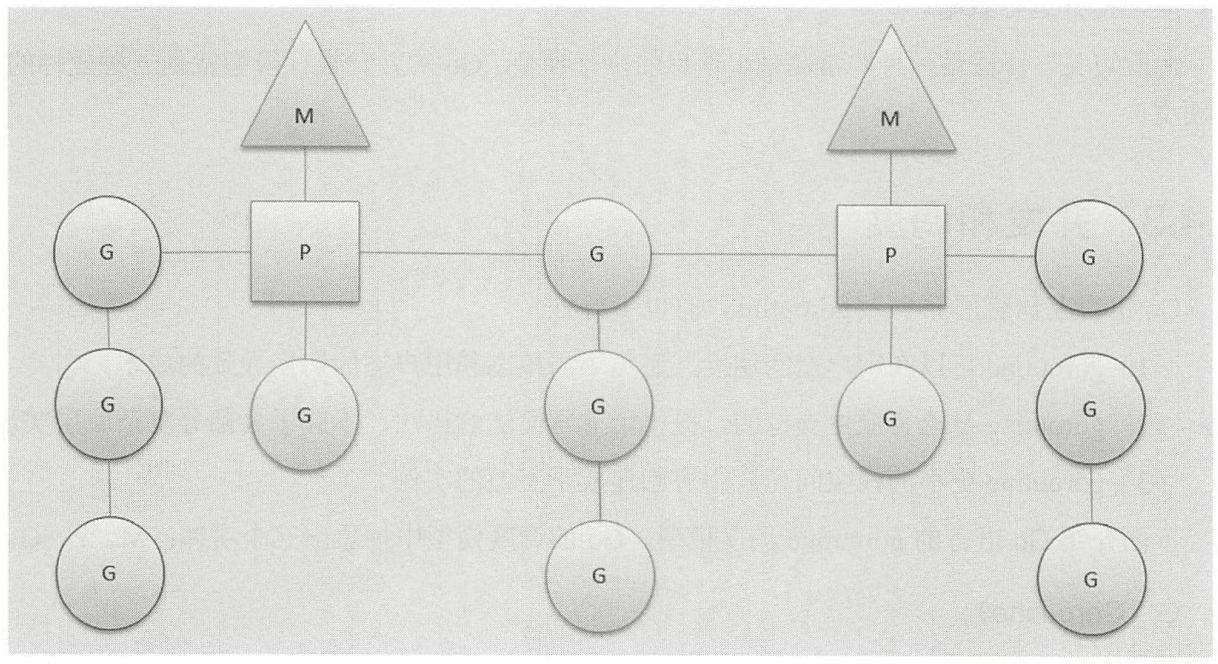
- G: goroutines 表示一个协程
- M: machine 表示一个线程
- P: Processor go 中管理协程的数据结构
Processor和线程: Go 语言的一个 target 就是可以充分的利用 CPU 的性能,同时减少调度开销。 N 个 CPU 理想情况下应该有 N 个线程,早期的 Go 语言就是这么做的,然而,操作系统存在阻塞的系统调用,比如读写文件,进入阻塞的系统调用后线程阻塞,CPU 利用率降低。
后期的调度中引入 P(Processor)的概念,N 核心的 CPU 会有 N 个 Processor,P 代表了一个处于运行状态的线程,用于控制可同时并发执行的任务数,数量默认为CPU核数相同:
- 一个正在执行的协程 G 一定会绑定一个 P;
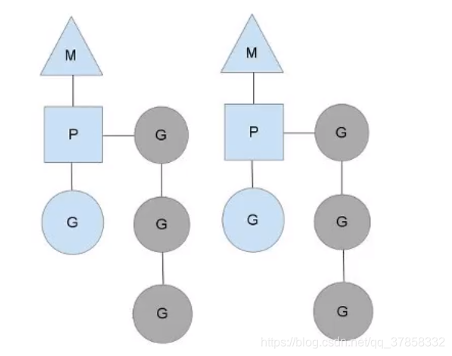
- Processor 绑定一个正在运行的线程 M,当一个 P 上的线程被系统调用阻塞后,runtime 会新生成一个线程重新绑定 P
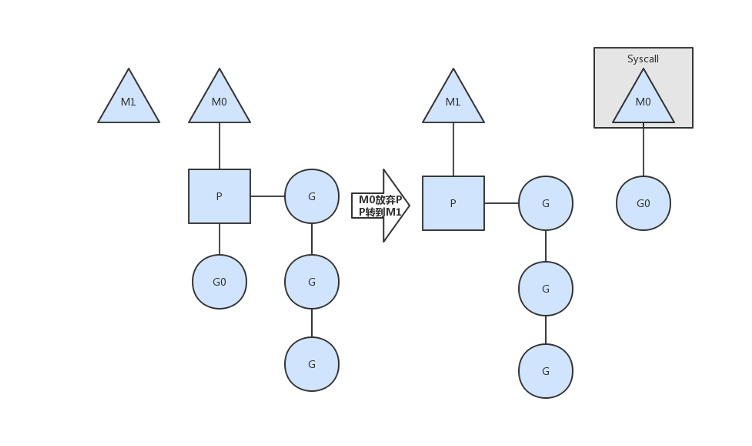
- P 实现了调度的局部性,一个 Processor 可以持有 257 个等待运行的协程(一个容量为 256 的队列和一个 runnext 变量,runnext 会首先被执行);P 执行完协程后,会从继续运行自己持有的协程;
- 当协程执行结束后,它绑定的 P 会执行 findrunner,优先从自己持有的协程中挑选一个新的G继续执行;
- 当协程执行结束后,它绑定的 P 会执行 findrunner,优先从自己持有的协程中挑选一个新的G继续执行;
管理数据结构:Local Queue和Global Queue
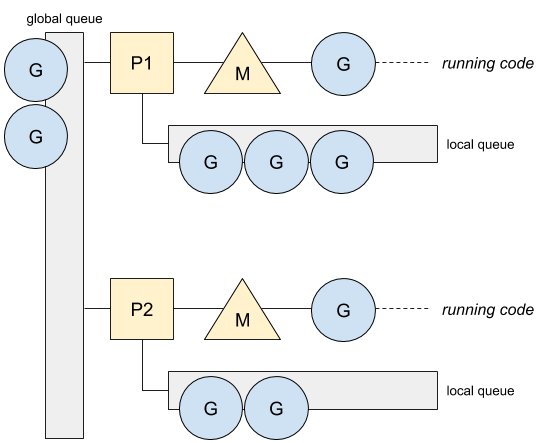 Go 的进程有一个全局唯一的队列,管理协程:
Go 的进程有一个全局唯一的队列,管理协程:
- Processor 中含有一个数组实现的 Queue,最多可以容纳 256 个协程;Processor 也含有一个 runnext 成员变量,表示当前P绑定的协程最新生成的协程。
- runtime 中也有一个全局的run queue,GRQ。GRQ采用链表实现,容量没有限制。
p的结构体片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
runnext guintptr
新的协程处理以及runqput
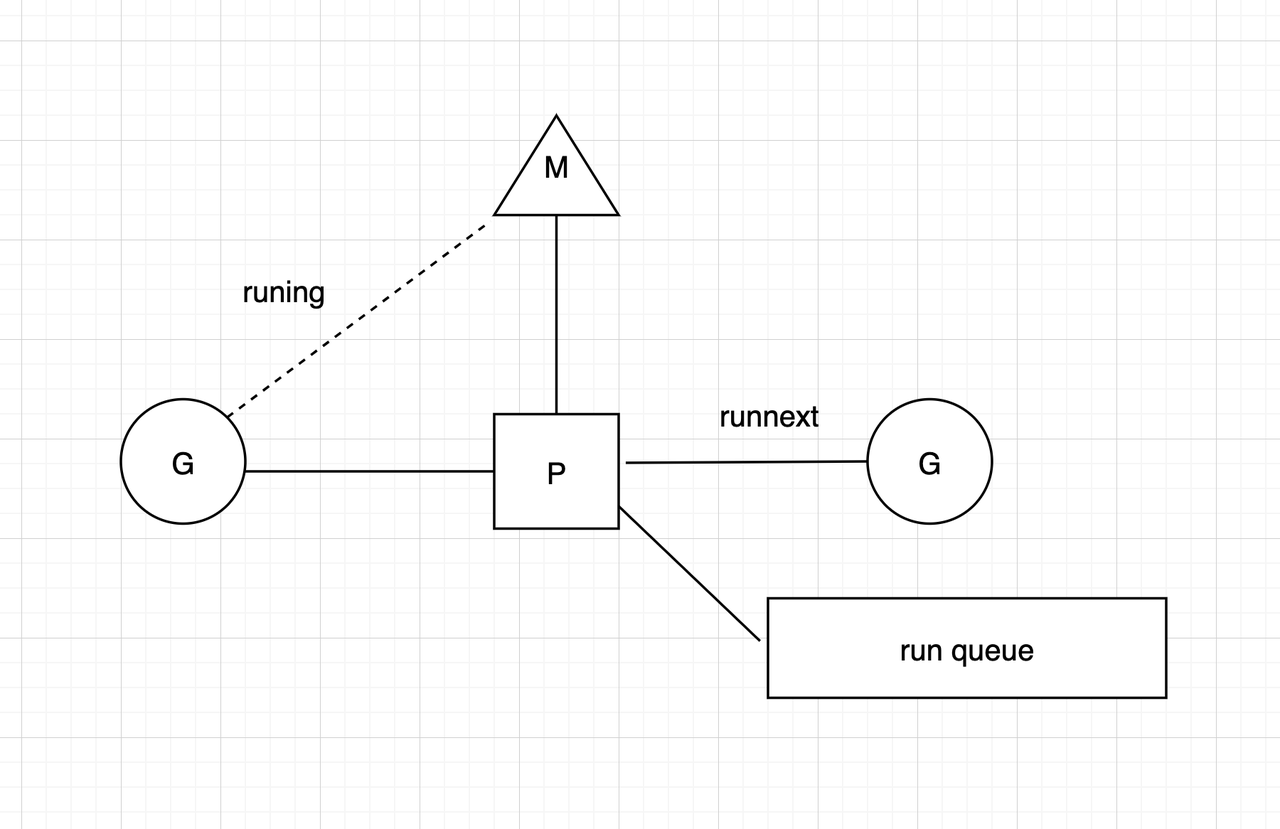 P、M、G 的关系如图所示,G0 新建的一个协程 G1,runtime 会调用 runqput 将协程交给 G0 绑定的 P 处理。
P、M、G 的关系如图所示,G0 新建的一个协程 G1,runtime 会调用 runqput 将协程交给 G0 绑定的 P 处理。
1
2
3
4
5
func runqput(_p_ *p, gp *g, next bool) {
//golang中的默认配置randomizeScheduler为false,next为true。
if randomizeScheduler && next && fastrand()%2 == 0 {
next = false
}
新建的协程首先设置成 P 的 runnext;runnext 指向的原来的执行的协程会尝试进入 P 的 LRQ。
1
2
3
4
5
6
7
8
9
10
11
12
if next {
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr()
}
gb 表示 runnext 原来的指向协程。首先会判断 P 的 LRQ(runq),是否满了,未满直接放入队列;如果满了执行后续操作。
1
2
3
4
5
6
7
8
retry:
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
如果 runq 已经满了,runtime 会将 gp 放入 GRQ 尾部,同时从 LRQ pop 出来 128 个协程放入 GRQ 尾部。
1
2
3
4
5
6
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
Processor确定下一个执行的协程:
当协程需要切换的时候,runtime 执行 findrunnable,为P选择下一个协程继续执行。
-
每调度61次(61是一个不大不小的素数),从GRQ尝试获取队头的G,执行;
1 2 3 4 5 6 7 8 9 10
if gp == nil { // Check the global runnable queue once in a while to ensure fairness. // Otherwise two goroutines can completely occupy the local runqueue // by constantly respawning each other. if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 { lock(&sched.lock) gp = globrunqget(_g_.m.p.ptr(), 1) unlock(&sched.lock) } }
-
检查 runnext,如果存在且上一个协程运行不超过 10ms,则执行 runnext 对应的协程;
1 2 3 4 5 6 7 8 9
for { next := _p_.runnext if next == 0 { break } if _p_.runnext.cas(next, 0) { return next.ptr(), true } }
-
尝试从P的队列中按照G的加入顺序获取,获取成功则切换;
1 2 3 4 5 6 7 8 9 10 11
for { h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers t := _p_.runqtail if t == h { return nil, false } gp := _p_.runq[h%uint32(len(_p_.runq))].ptr() if atomic.CasRel(&_p_.runqhead, h, h+1) { // cas-release, commits consume return gp, false } }
-
从 GRQ 中获取,从队头开始获取G作为下一个执行的队列,同时从GRQ中获取协程继续执行,最多获取128;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
if sched.runqsize == 0 { return nil } n := sched.runqsize/gomaxprocs + 1 if n > sched.runqsize { n = sched.runqsize } if max > 0 && n > max { n = max } if n > int32(len(_p_.runq))/2 { n = int32(len(_p_.runq)) / 2 } sched.runqsize -= n gp := sched.runq.pop() n-- for ; n > 0; n-- { gp1 := sched.runq.pop() runqput(_p_, gp1, false) } return gp
- 检查网络阻塞的 netpoller,获取摆脱网络阻塞状态的协程列表(相当于调用epoll_wait 获取就绪状态的套接字),获取第一个协程继续执行,将其余摆脱网络阻塞状态的协程放回GRQ的队尾;
- 从其余的P上获取协程执行(stealing);
由上一节的分析知,协程 G 执行结束后,不会重新在 P 的 LRQ上。因此对于正常的服务端程序,LRQ 会空掉,会继续从 GRQ 中获取。
调整Processor的数目:
Go启动时候首先会尝试读取GOMAXPROCS环境变量,确定初始化的P的数目,如果没有设置这个环境变量会以CPU的核数为准。头条的TCE会在初始化容器的时候设置环境变量。
Go程序中也提供了方法修改 P 的数目。
1
func GOMAXPROCS(n int) int
当 P 的数目缩减的时候,runtime 会选择需要销毁的P,将 P 中的协程放入 GRQ 的队列首部。
举例-Case 1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import (
"fmt"
"runtime"
"sync"
)
func main() {
runtime.GOMAXPROCS(1)
var x = 1
var wg sync.WaitGroup ;
for {
wg.Add(1)
go func(i int) {
fmt.Println(i)
wg.Add(-1)
}(x)
x++
if (x > 300) {
break
}
}
wg.Wait()
}
这个程序可以让我们更好的理解 GMP 模型,程序一共 1 个 Processor。程序共产生了 1-300 号的协程。当产生完成 257 个线程后,Local Queue 和 Global Queue 的状态为:
- runnext_ : 257 号协程
- Local Queue: 1-256 号协程
- Global Queue: 为空
当产生第 258 号协程的时候,Local Queue 的容量已经满了,runtime 会从 Local Queue 获取 128 协程放入 Global Queue,并将 257 号协程插入Global Queue。
- runnext_ : 258 号协程
- Local Queue:129-256号协程
- Global Queue:1-128 257 插入 300 的时候:
- runnext_ : 300号协程
- Local Queue:129-256 258-299号协程
- Global Queue:1-128 257
调用
wg.Wait(),开始执行 Queue 中的协程。
- 首先执行 300 号协程,
- Local Queue 129-188号协程
- Global Queue 1号协程 (调度了61次)
- Local Queue 189-248
- Global Queue 2号协程 调度(调度了61次)
- 249-256 258-299
- 从Global Queue获取128个,Local Queue 3-128 257
- 3-128 257
协程切换
Go1.14前,如果一个 G 会一直在执行计算任务没有遇到阻塞,那么这个 P 上的其余协程都不会被执行。GO 不适合执行复杂的计算逻辑。 Go1.14中,每 10ms,runtime会发送os信号给线程,信号处理函数中执行切换。
协程切换时机:
协程会在四种情况下切换,执行 findrunnable 选择下一个协程:
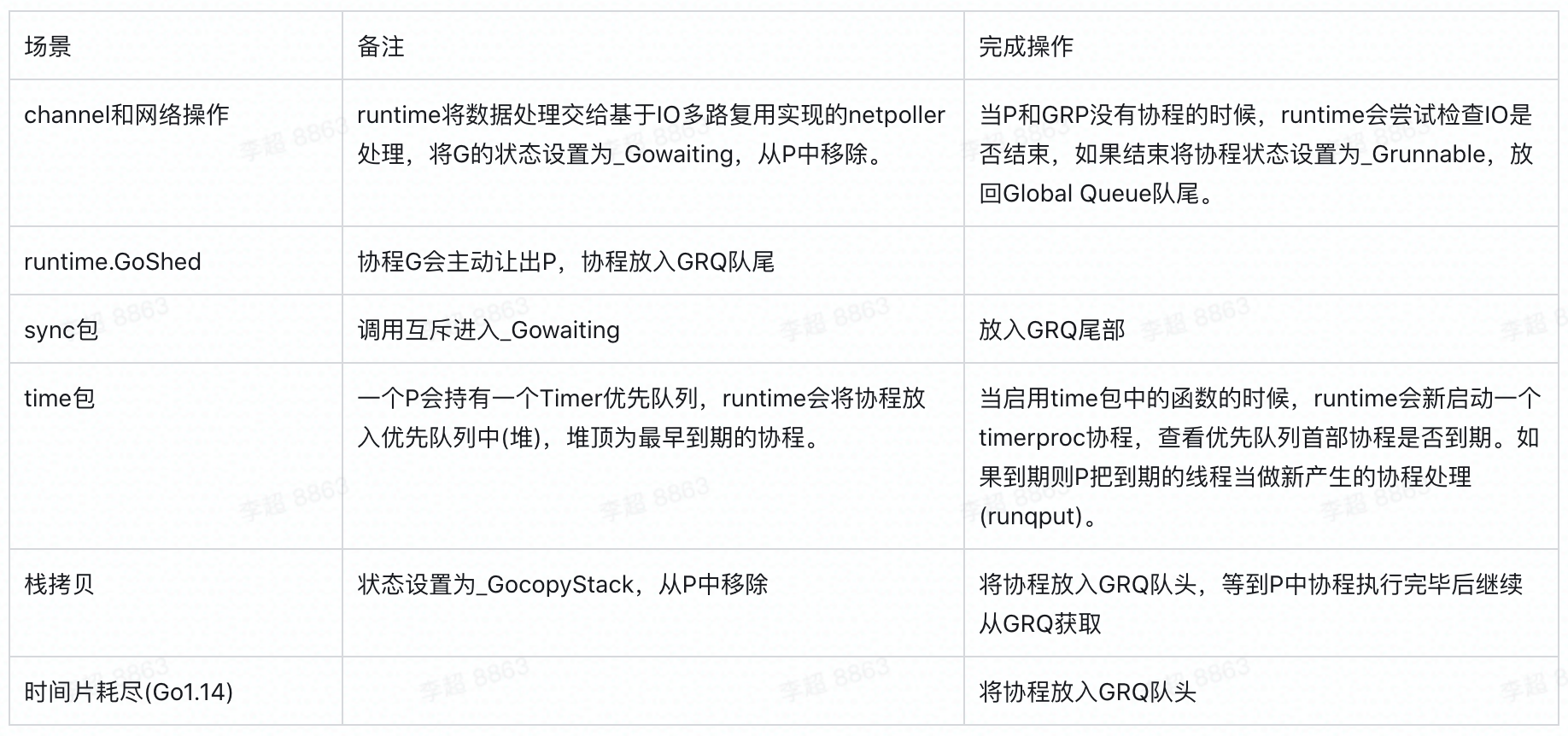
协程的场景
当遇到协程切换的场景的时候,runtime 会调用mcall函数完成协程栈的切换。
chan切换
chan 的实际定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
type hchan struct {
qcount uint // 队列中的元素数目
dataqsiz uint // 队列中最大的元素树
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // 单个元素的大小
sendx uint // 下一个发送元素写入位置
recvx uint // 下一个元素读出位置
recvq waitq // 表示阻塞在此chan上的读队列
sendq waitq // 表示阻塞在此chan上的写队列
lock mutex
}
chan 含有两个阻塞协程队列,recvq 和 sendq,当读一个 chan 遇到 chan 为空时,此时协程需要被阻塞;runtime 会将当前协程变为 _Gowaiting 状态,放入 recvq 中;当向 chan 写数据的时候,首先会检查是 recvq 否有阻塞的协程,如果 recvq 不为空,则取第一个将数据返回给这个协程,同时调用 runqput,将协程加入 GMP 模型中。
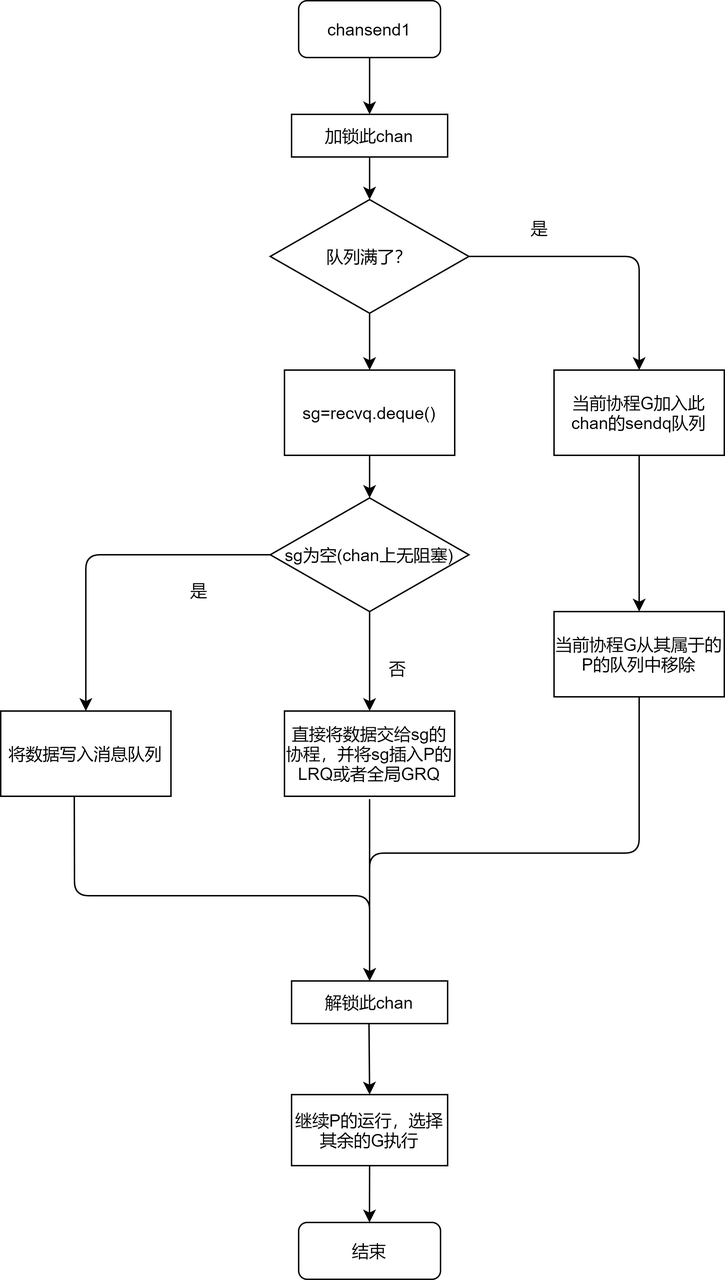 对于sendq的操作类似。
对于sendq的操作类似。
对chan调用select
对于以下语法,go会进行特化处理:
1
2
3
4
5
6
7
select{
case x<-chan1:
XXXX
case y<-chan2:
XXXX
·····
}
Go不会将对chan的select处理成其他语言中switch形式判断语句,相反go的编译器会处理为selectgo函数。
1
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool)
在 selectgo 函数中,会对目标的 chan 按照随机顺序进行轮询,当发现一个chan满足条件后返回,否则让出协程等待下载调度再次轮询。
对于chan的select不是基于事件触发而是基于轮询,
网络IO
Go的runtime会为每个套接字创建一个 pollDesc,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
type pollDesc struct {
link *pollDesc // in pollcache, protected by pollcache.lock
// The lock protects pollOpen, pollSetDeadline, pollUnblock and deadlineimpl operations.
// This fully covers seq, rt and wt variables. fd is constant throughout the PollDesc lifetime.
// pollReset, pollWait, pollWaitCanceled and runtime·netpollready (IO readiness notification)
// proceed w/o taking the lock. So closing, everr, rg, rd, wg and wd are manipulated
// in a lock-free way by all operations.
// NOTE(dvyukov): the following code uses uintptr to store *g (rg/wg),
// that will blow up when GC starts moving objects.
lock mutex // protects the following fields
fd uintptr
closing bool
everr bool // marks event scanning error happened
user uint32 // user settable cookie
rseq uintptr // protects from stale read timers
rg uintptr // pdReady, pdWait, G waiting for read or nil
rt timer // read deadline timer (set if rt.f != nil)
rd int64 // read deadline
wseq uintptr // protects from stale write timers
wg uintptr // pdReady, pdWait, G waiting for write or nil
wt timer // write deadline timer
wd int64 // write deadline
self *pollDesc // storage for indirect interface. See (*pollDesc).makeArg.
}
当一个协程发生网络IO的时候,调用非阻塞IO,如果网络IO未准备好(即内核缓冲区没有足够的数据提供给进程读写),runtime会将该协程状态变为_Gowaiting,移除GMP模型,同时在epoll/kqueue/iocp注册该协程监听的套接字。 当一个P上的没有可执行的协程,并且GRQ为空的时候,runtime会调用netpoll(底层封装了epoll/kqueue/iocp)获得准备好的套接字以及对应阻塞的协程状态转化为_Grunning,重新加入GRQ中,runtime会为P重新获取协程。
Time处理
第一次调用 time 相关的函数,time协程持有一个四叉堆(优先队列,四叉堆可以充分发挥1级cache的性能),用于处于等待状态的Goroutine排序,当调time.Sleep等函数,runtime会将当前的协程放入对应的协程的四叉堆中;runtme切换到time协程时,time协程会检查优先队列的头部判断是否存在time到期的协程,如果存在会将协程放回GRQ或者LRQ中,遍历完毕后会再次让出P。