GC(Garbage Collection 垃圾回收),是一种自动管理内存的机制。传统的编程语言(C/C++)中,释放无用变量内存空间是程序员手动释放,存在内存泄漏或者释放不该释放内存等问题。为了解决这个问题,后续的语言(java\python\php\golang等)都引入了语言层面的自动内存管理,语言使用者无需对内存进行手动释放,内存释放由虚拟机(virtual machine)或者运行时(runtime)来对不再使用的内存资源进行自动回收。
背景
术语解释
- GC roots: 是指向存活对象的指针的起点部分
- Go 中包含全局变量空间中的对象、调用栈中的对象、寄存器中的对象。
- Java 中包括虚拟机栈的栈帧中的本地变量表、方法区中类静态属性、方法区常量、JNI栈、虚拟机内部如基本数据类型对应的 Class 引用的对象等,还包括常驻内存的异常对象、系统类加载器等。
- 保守式GC: Conservative GC,不能识别指针和非指针的 GC
- 准确式GC: Exact GC,能正确识别指针和非指针的 GC
- Stop The World(STW): 暂停所有工作线程,即程序不执行了,等待垃圾回收完成。
- 安全点: 程序能够安全停下并支持垃圾回收的位置,在方法调用、循环跳转、异常跳转等指令处
- 安全区域: 确保在某一段代码之中,引用关系不发生变化。因此在这个区域内开始垃圾回收都是安全的。
- 读/写屏障: 可以看做读取/修改引用这个动作的 AOP 切面,可以为程序提供额外的执行动作,比如读取/修改引用前后都是屏障的覆盖范围。
- JVM: Java Virtual Machine 即 Java 虚拟机
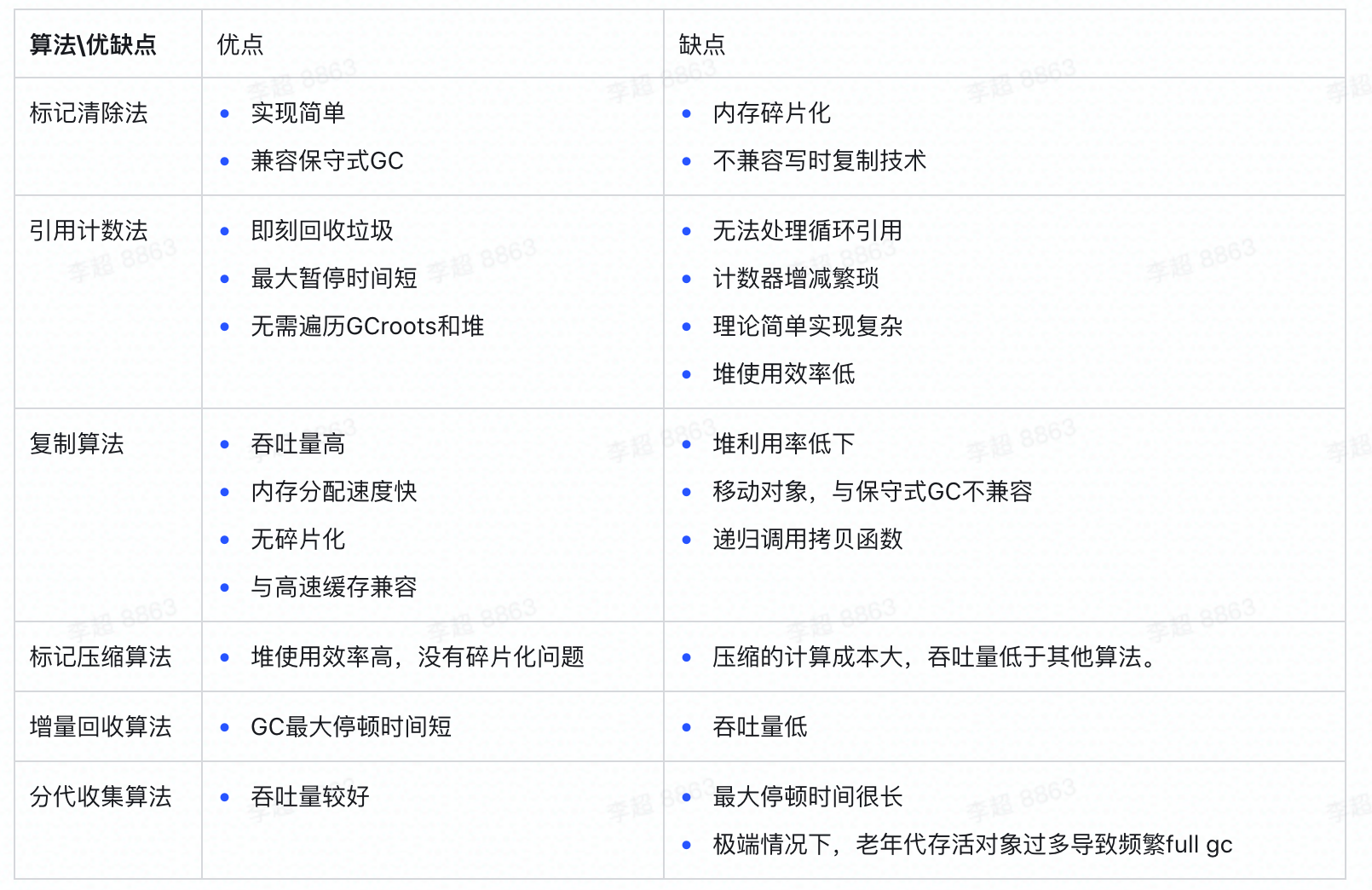
算法优劣评价标准
- 吞吐量:CPU 运行用户代码的时间/(CPU 运行用户代码的时间+CPU 运行垃圾回收的时间)
- 最大暂停时间:GC回收过程中,STW的最大时间
- 堆使用效率:能有效使用的堆占堆总大小的比例
- 访问的局部性:具有引用关系的对象之间通常存在连续访问的情况,考虑到这一点,把引用关系的对象安排在堆中较近的位置,能提高高速缓存中读取到想要利用的数据的概率。
内存分配
因为垃圾回收和内存分配二者是相辅相成的,共同构成了自动内存管理的技术体系,在垃圾回收之前,先来简单看看内存分配。
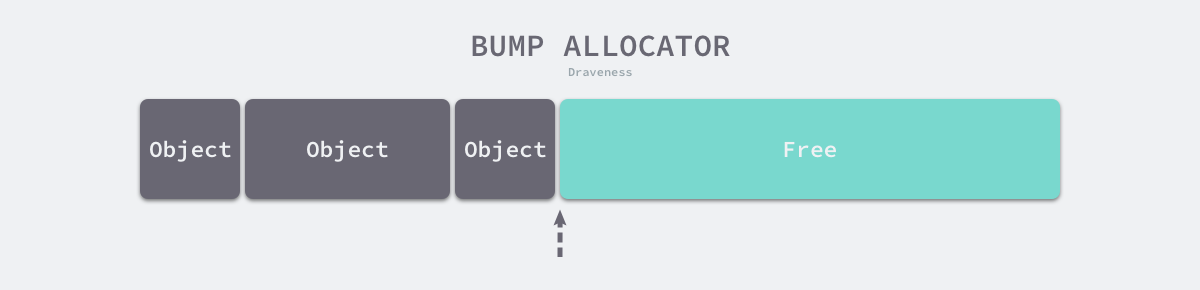
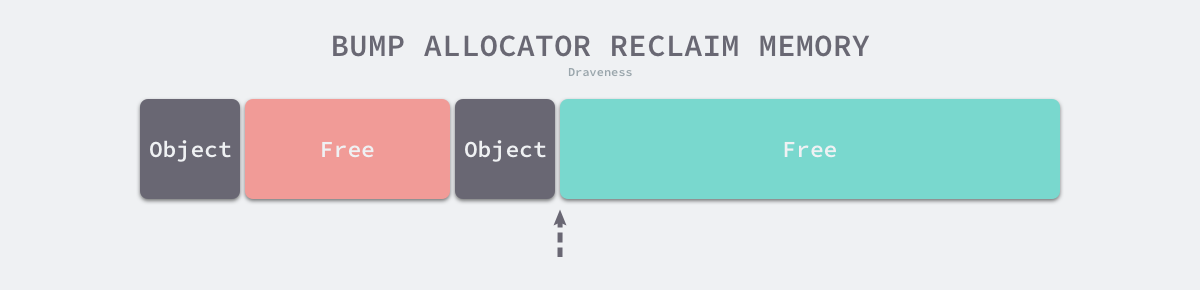
- 顺序分配,维护一个指向特定位置的指针(指向空闲内存起始地址),内存分配的时候分配器只需检查空闲内存,返回内存分配的区域地址并修改指针位置。特点很高效,实现简单。但是局限性较大,垃圾回收的时候要产生大量内存碎片无法继续使用,要解决这个问题,需要垃圾回收时候配合相应的整理内存碎片的算法(标记整理,复制算法,分代收集),则需要移动内存,基本上可以直接操作指针的语言就没法搞了(C,C++)。
- 空闲链表分配,将内存块以链表方式链接,可以很方便的重新利用被回收的内存块。但是内存分配的时候需要遍历链表,时间复杂度为O(n)。空闲链表分配器可以选择不同的策略在链表中的内存块中进行选择,最常见的就是以下四种方式:
- 首次适应(First-Fit)— 从链表头开始遍历,选择第一个大小大于申请内存的内存块;
- 循环首次适应(Next-Fit)— 从上次遍历的结束位置开始遍历,选择第一个大小大于申请内存的内存块;
- 最优适应(Best-Fit)— 从链表头遍历整个链表,选择最合适的内存块;
- 隔离适应(Segregated-Fit)— 将内存分割成多个链表,每个链表中的内存块大小相同,申请内存时先找到满足条件的链表,再从链表中选择合适的内存块;隔离适应减少内存块的数量,提高了内存分配的效率。
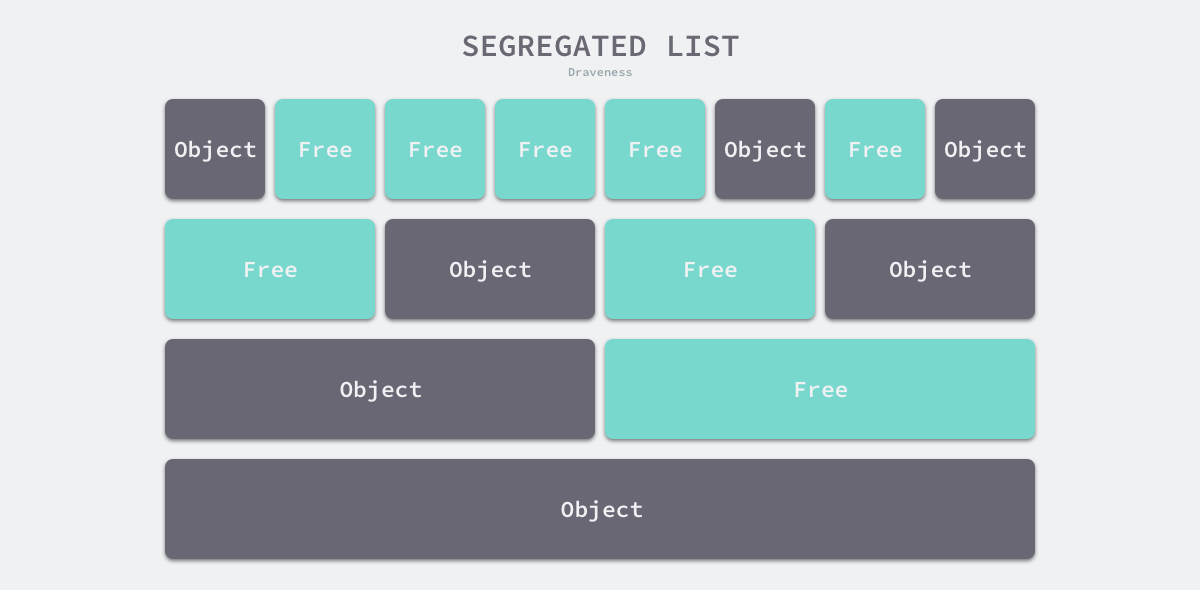
Go 的内存分配策略,类似隔离适应,借鉴了线程缓存分配(Thread-Caching Malloc, TCMalloc)的内存分配机制(比malloc函数快很多),它的核心理念是使用多级缓存将对象根据大小分类,并按照类别实施不同的分配策略。
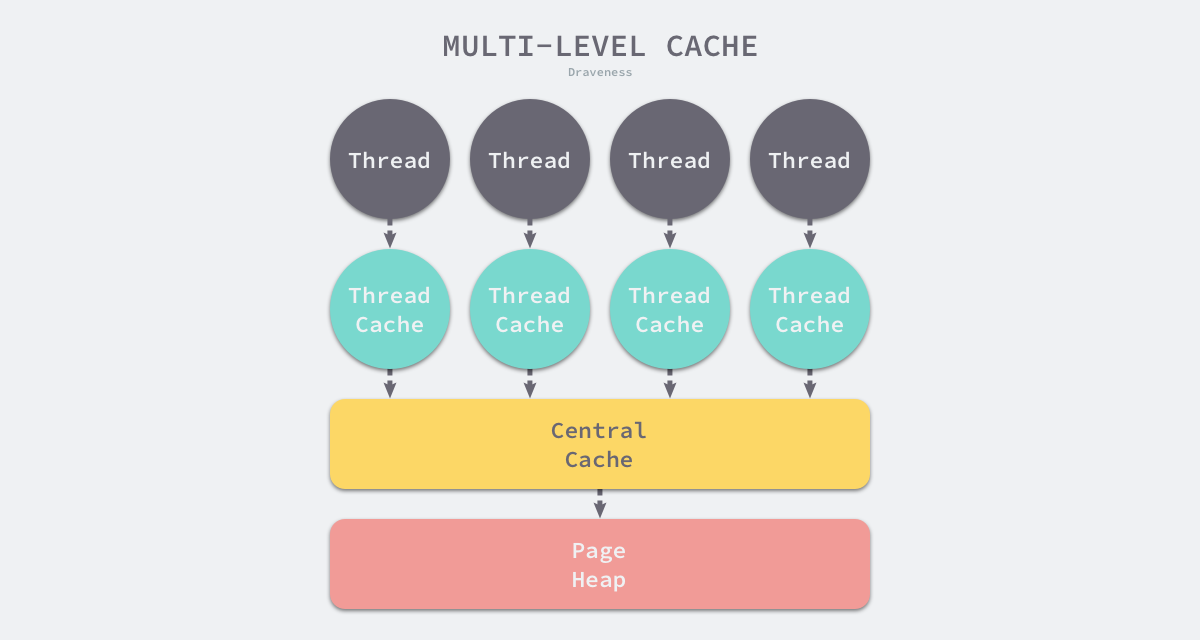
Java 的内存分配策略,对象应该都是在堆上分配(而实际上也可能是经过 JIT 即时编译,后被拆散为标量类型并间接的在栈上分配)。在经典的分代的设计下,新生对象通常分配在新生代中,少数情况下如对象超过一定阈值也可能直接分配在老年代上。分配规则不是固定的,而是取决于当前虚拟机使用哪种垃圾收集器以及虚拟机参数。一般来说有如下分配规则:
- 对象优先分配在新生代(Young Generation)的 Eden 区域分配
- 大对象直接进入老年代(Tenured Generation)分配
- 通过动态对象年龄判定,长期存活的对象进入老年代
- 空间分配担保,即把新生代中因为存活过多对象,导致存活对象需要被复制到的 Survivor 区域无法容纳这么多对象,这些对象会被送入老年代
算法
引用计数法
根据对象自身的引用计数来回收,当引用计数归零时进行回收,但是计数频繁更新会带来更多开销,且无法解决循环引用的问题。
- 优点:简单直接(无需遍历GC roots或者堆),回收速度快
- 缺点:需要额外的空间存放计数,无法处理循环引用的情况;
标记清除算法
首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
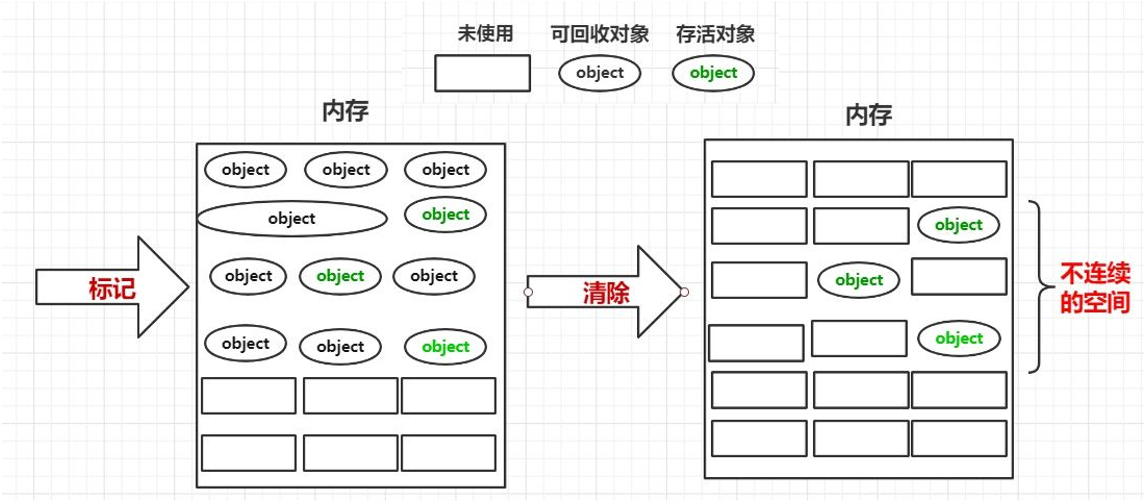
分为标记阶段和清除阶段,标记阶段从 root 开始遍历,并将能遍历到的对象标记为存活。清除阶段收集器则会遍历整个堆,回收没有被标记为存活的的对象。遍历整个堆则表明垃圾回收时间与堆大小成正比,堆越大则清除阶段所花费的时间越长。
- 优点:
- 简单直接
- 速度快
- 与保守式GC兼容(不移动对象)
- 适合可回收对象不多的场景
- 缺点:
- 效率问题:标记和清除两个过程的效率都不高。标记尤甚。
- 空间问题:标记清除之后会产生大量不连续的内存碎片,空间碎片太多会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
- 回收垃圾时间与存活对象成正比:主要原因在于垃圾回收时间主要消耗在了标记阶段。
- 与写时复制技术不兼容(fork进程,不会复制内存空间,只有在修改的时候才复制一份出来到进程的私有空间进行修改,在标记过程中,会频繁发生修改活动对象标志位的,就会发生频繁复制)
后续的收集算法都是基于这种思路并对其不足进行改进而得到的。
标记复制算法
标记复制算法将内存分为两块大小相同的两块区域。一块叫做 From 空间,另外一块是 To 空间,当 From 空间被完全占满的时候,GC 将 From 中存活的对象全部复制到 To 空间,并清空 From 空间,最后交换 From 和 To 空间,完成 GC。
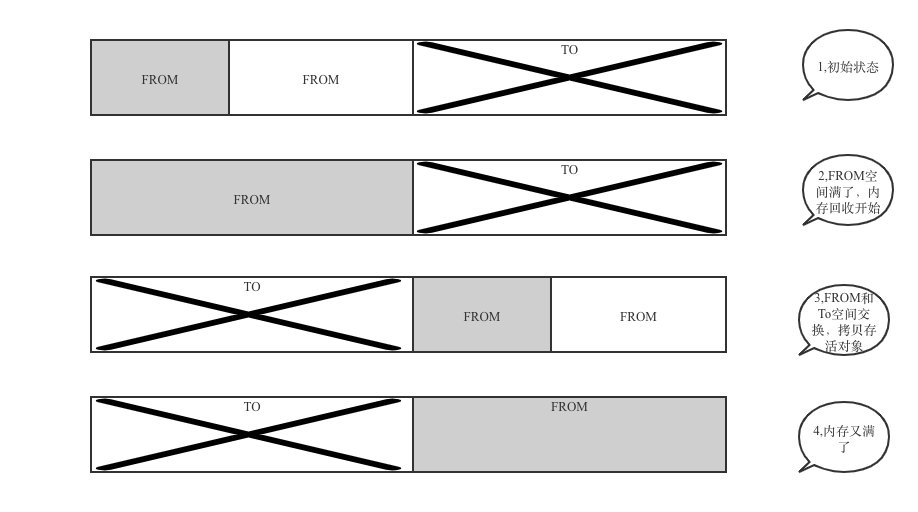
- 优点:
- 解决了内存碎片的问题,内存分配速度快(因为是顺序分配)
- 优秀的吞吐量(只遍历和移动存活对象,不会遍历堆)
- 与高速缓存兼容(复制后的引用对象在物理上靠得很近)
- 缺点:
- 堆利用率低下,只能利用一半的堆内存
- 需要移动对象,与保守式 GC 不兼容
- 递归调用拷贝函数拷贝对象,如果对象引用很深,有栈溢出的风险(这里可以使用广度优先搜索,但是拷贝后引用对象物理上靠的近这一优势就失去了,即失去 与高速缓存兼容 的优点)
标记整理算法
标记过程同标记清除法,结束后将存活对象压缩至一端,然后清除边界外的内容。
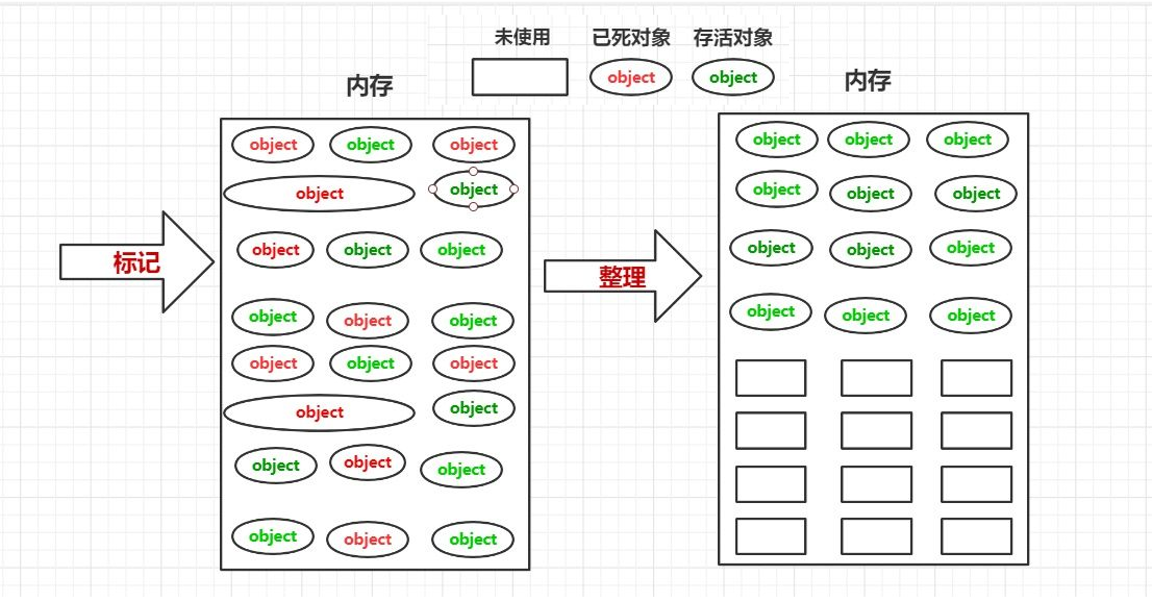
- 优点:
- 堆使用效率高,没有碎片化问题;
- 缺点:压缩的计算成本大,吞吐量低于其他算法。压缩会遍历三次堆,第一次遍历,为存活的对象设定forwarding指针,即复制后的对象的位置。第二次遍历,将引用对象的指针指向引用对象的forwarding指针。第三次遍历,将活动对象移动到forwarding指针的位置处。
适用于老年代中,存在大量的存活对象需要复制。
分代收集算法
分代算法基于这样一个假说(Generational Hypothesis):绝大多数对象都是朝生夕灭的,该假说已经在各种不同类型的编程范式或者编程语言中得到证实了。分代算法把对象分类成几代,针对不同的代使用不同的 GC 算法:刚生成的对象称为新生代对象,对新对象执行的 GC 称为新生代 GC(minor GC),到达一定年龄的对象则称为老年代对象,面向老年代对象的 GC 称为老年代 GC(major GC),新生代对象转为为老年代对象的情况称为晋升(promotion)。
注:代数并不是划分的越多越好,虽然按照分代假说,如果分代数越多,最后抵达老年代的对象就越少,在老年代对象上消耗的垃圾回收的时间就越少,但分代数增多会带来其他的开销,综合来看,代数划分为 2 代或者 3 代是最好的。在经过新生代 GC 而晋升的对象把老年代空间填满之前,老年代 GC 都不会被执行。因此,老年代 GC 的执行频率要比新生代 GC 低。通过使用分代垃圾回收,可以改善 GC 所花费的时间(吞吐量)。
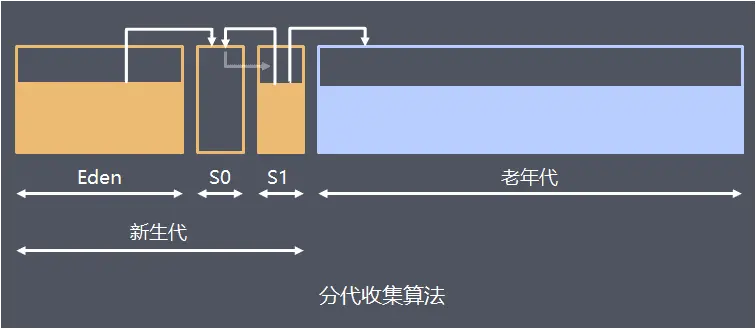
新生代(Young Generation): 又叫年轻代,大多数对象在新生代中被创建,很多对象的生命周期很短。每次新生代的垃圾回收(又称Young GC、Minor GC、YGC)后只有少量对象存活,所以使用标记复制算法,只需少量的复制操作成本就可以完成回收。新生代内又分三个区:一个 Eden 区,两个 Survivor 区(S0、S1,又称 From Survivor、To Survivor),大部分对象在 Eden 区中生成。当 Eden 区满时,还存活的对象将被复制到两个 Survivor 区(中的一个)。当这个 Survivor 区满时,此区的存活且不满足晋升到老年代条件的对象将被复制到另外一个 Survivor 区。对象每经历一次复制,年龄加 1,达到晋升年龄阈值后,转移到老年代。
老年代(Old Generation): 在新生代中经历了 N 次垃圾回收后仍然存活的对象,就会被放到老年代,该区域中对象存活率高。老年代的垃圾回收通常使用“标记-整理”算法
一般新生代采用复制算法,老年代采用标记清除/标记整理算法
Hotspot 虚拟机默认的 eden 和 servivor 的大小比例是 8:1,也就是每次新生代中可用内存空间为整个新生代容量的 90%。当 servitor 空间不够用时,需要依赖其他内存(老年代)进行担保。
优点:
- 吞吐量较好 缺点:
- 最大停顿时间依然很长
- 极端情况下,老年代存活对象过多导致频繁full gc
增量回收(Incremental GC)
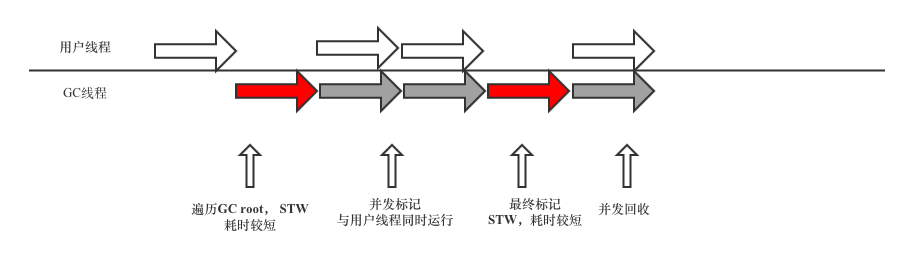
通过 GC 和应用程序交替执行的方式,来控制应用程序的最大暂停时间。通过并发标记的方式,降低STW的时间,从而达到低停顿的目的。
优点:
- GC最大停顿时间短 缺点:
- 吞吐量低
保守式和准确式GC(Conservative GC And Exact GC)
保守式GC
不能识别指针和非指针的GC,什么意思呢?前面讲过我们通过GC roots来遍历活动对象,GC roots中存储的值,貌似是指针也可能是非指针,保守式GC就是不管你是不是指针,只要这个值满足是正确对齐的值(根据CPU的位数,如32位CPU指针是4的倍数)、指向堆内、指向对象开头,就将其标记为活动对象,遵循了不回收活动对象的原则,即“把可疑的值看做指针,稳妥处理”,所以叫保守式GC。
优点:
- 不依赖于语言实现 缺点:
- 错误识别会压迫堆,应该回收的内存得不到回收
- 能够配合的GC算法有限 改进思路:
- 增加句柄引用对象与需要移动对象的GC算法配合。但是会拉低对象访问速度。
- MostlyCopyingGC(Joel F.Bartlett 1989年研究的一个保守式GC的复制算法)
准确式GC
能正确识别指针和非指针的GC,但是需要编程语言的支持。 优点:
- 可以准确GC,不会存在遗漏的死亡对象 缺点:
- 需要程序语言支持
GC算法比较