与MySQL类似,MongoDB底层也使用了『可插拔』的存储引擎以满足用户的不同需要。从 MongoDB 3.2 开始,WiredTiger 存储引擎开始作为默认的存储引擎。WiredTiger 使用文档级并发控制进行写操作,使用 MultiVersion 并发控制(MVCC)方式。
In-Memory In-Memory 存储引擎将数据存储在内存中,除了少量的元数据和诊断(Diagnostic)日志,In-Memory存储引擎不会维护任何存储在硬盘上的数据(On-Disk Data),避免Disk的IO操作,减少数据查询的延迟。
MMAPv1: 从MongoDB 4.2开始,MongoDB移除了MMAPv1存储引擎。并发级别上,MMAPv1支持到collection级别,所以对于同一个collection同时只能有一个write操作执行,这一点相对于wiredTiger而言,在write并发性上就稍弱一些。
WiredTiger 特性

- Row Storage & Column Storage:基于BTree的行存/列存;
- cache 模块:内存数据缓存,主要由内存中的 btree page(数据页,索引页,溢出页)构成;
- block management 模块:磁盘文件、空间管理,负责磁盘 IO 的读写,cache、evict、checkpoint 模块均通过该模块访问磁盘;
- Transaction & Snapshots:事务;
- Schema & Cursors:Connection,Session, Cursor等;
数据模型

- MongoDB 的1个
collection/index,对应WiredTiger的一个b+tree; collection/index中的每个 document,对应WiredTiger b+tree leaf page的一个KV;Key(collection的键值)构成internal page,即b+tree索引。- WiredTiger在内存Cache和磁盘上,都用
b+tree来组织 KV。每个b+tree节点为一个 page,root page是b+tree的根节点,internal page 是b+tree的中间索引节点,leaf page是真正存储数据的叶子节点。Cache中b+tree的数据以 page 为单位按需从磁盘加载或写入磁盘。 - WiredTiger在磁盘上的数据组织方式和内存中是不同的,在磁盘上的数据一般是经过压缩以节省空间和读取时的IO开销。当从磁盘向内存中读取数据时,一般会经过解压缩、将数据重新构建为内存中的数据组织方式等步骤。
- 持久化时,修改操作不会在原来的leaf page上进行,而是写入新分配的page,每次checkpoint都会产生一个新的root page。 这样的好处是对不修改原有page,就能更好的并发。
Cache
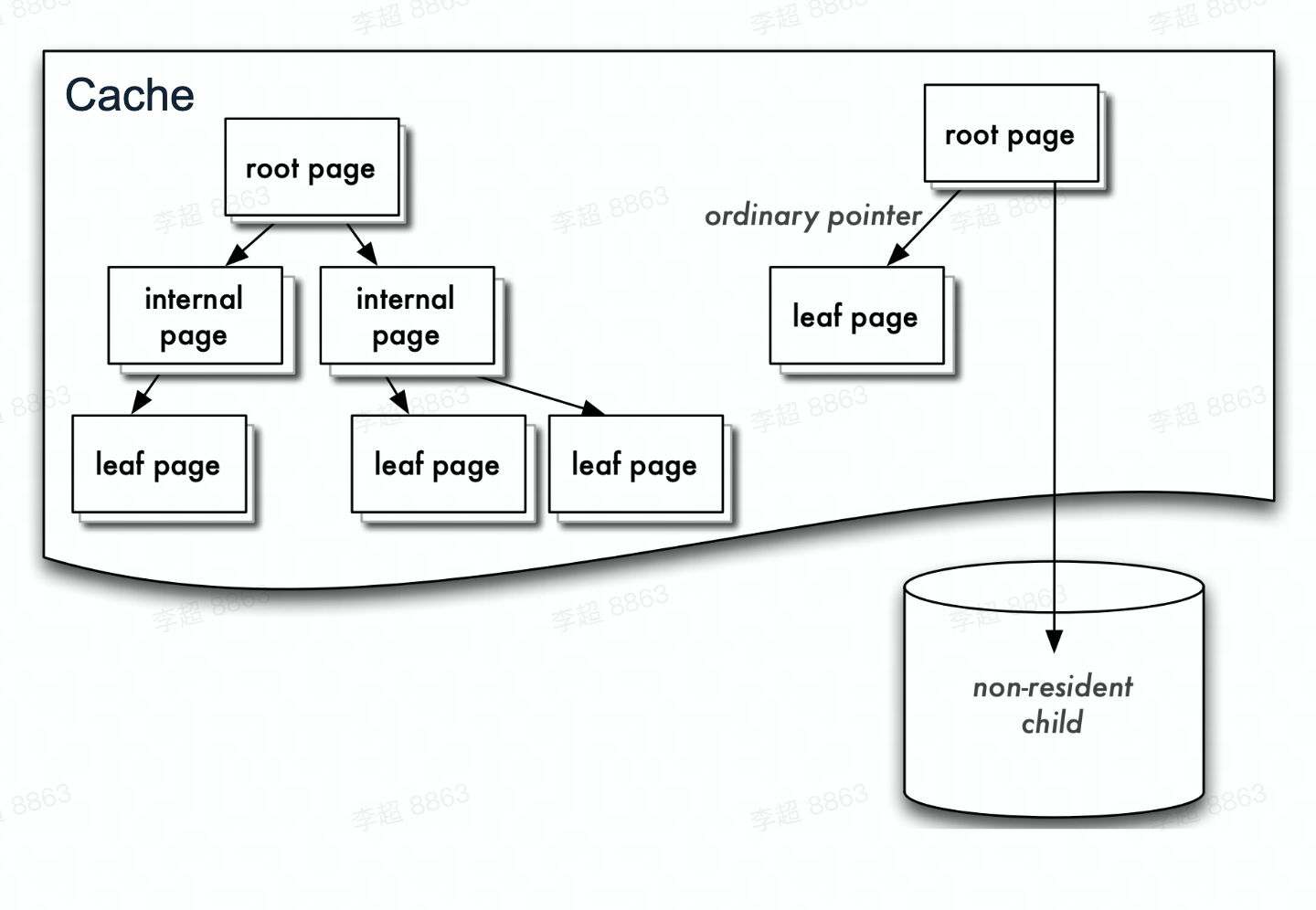
- Cache中的BTree包含全部或部分磁盘的数据page
- 存在In-Memory Page与On-Disk Page的换入换出
- 如果需要读取的page不在Cache中,从磁盘文件加载到Cache,成为clean page;
- 如果Cache占用内存过高时,clean page会被直接淘汰出cache;
- 如果clean page被修改写入,变成dirty page,dirty page会被evict/checkpoint刷到data file
上图是 page 在内存中的数据结构,是一个典型的 b+tree,每个叶节点的 page 上有 3 个重要的 list:WT_ROW、WT_UPDATE、WT_INSERT:
- 内存中的
b+tree树:是一个checkpoint。初次加载时并不会将整个b+tree树加载到内存,一般只会加载根节点和第一层的数据页,后续如果需要读取数据页再从磁盘加载 - 叶节点Page的 WT_ROW:是从磁盘加载进来的数据数组
- 叶节点Page的 WT_UPDATE:是记录数据加载之后到下个checkpoint之间,该叶节点中被修改的数据
- 叶节点Page的 WT_INSERT:是记录数据加载之后到下个checkpoint之间,该叶节点中新增的数据
_id主键
MongoDB会为每一个插入的文档都默认添加一个_id字段,相当于这条记录的主键,用于保证每条记录的唯一性。由于MongoDB是适用于分布式场景的,因此这个全局唯一的_id需要使用一种分布式唯一ID的生成算法。
MongoDB采用的是类似Snowflake的分布式ID生成算法:
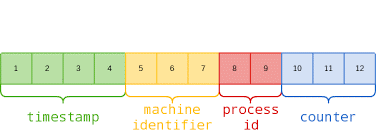
其中包括:
- 4-byte Unix 时间戳
- 3-byte 机器 ID
- 2-byte 进程 ID
- 3-byte 计数器(初始化随机)
索引
Wired Tiger存储引擎使用了B+树实现索引。
在v5.3版本之后,MongoDB可以支持聚簇索引。
读写逻辑
写入原理
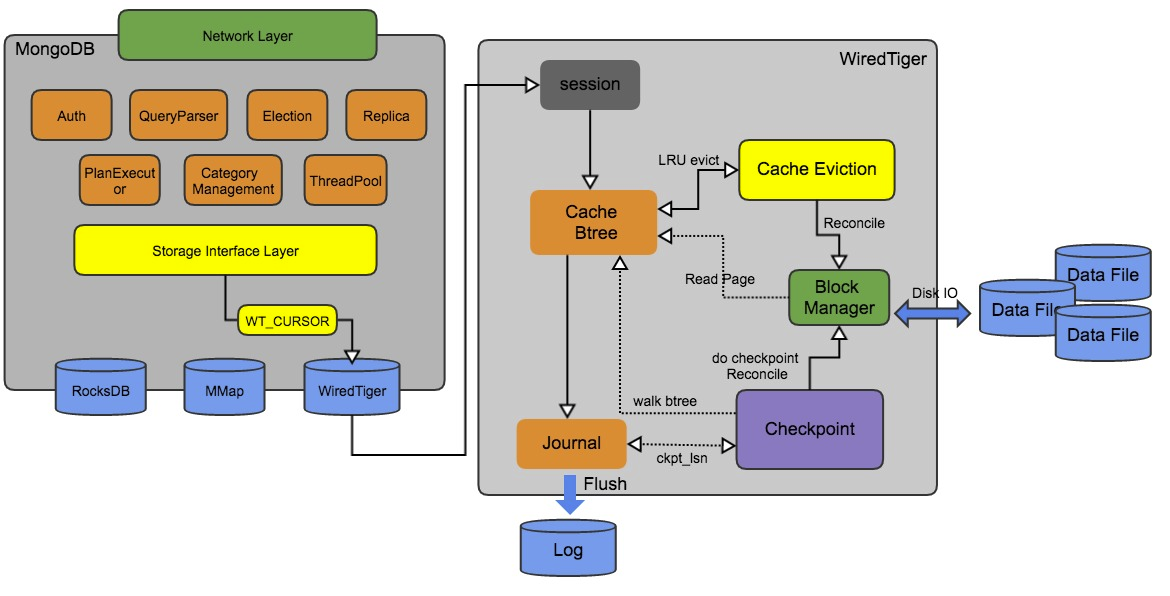 对于数据页的修改(update、insert、delete)都是在内存中的,因此需要有一定的机制来保证修改的持久化。在Wired Tiger中,达到一定的条件之后,就会触发生成一次Checkpoint,类似于MySQL中的Checkpoint概念。在生成新的Checkpoint的过程中,会将在内存中做过修改的脏页刷到磁盘。当系统崩溃时,下次重启恢复就从最新的Checkpoint开始恢复。从3.6版本开始,默认配置是60s做一次checkpoint。
对于数据页的修改(update、insert、delete)都是在内存中的,因此需要有一定的机制来保证修改的持久化。在Wired Tiger中,达到一定的条件之后,就会触发生成一次Checkpoint,类似于MySQL中的Checkpoint概念。在生成新的Checkpoint的过程中,会将在内存中做过修改的脏页刷到磁盘。当系统崩溃时,下次重启恢复就从最新的Checkpoint开始恢复。从3.6版本开始,默认配置是60s做一次checkpoint。
除了Checkpoint机制,Wired Tiger也使用了Write Ahead Log(预写式日志)来保证持久化,叫做Journal,类似于MySQL中的redo log。默认使用了压缩算法节省空间。
Journal日志默认100ms/约100MB/其他情况(如客户端提供了强制刷盘的参数)刷一次盘。Wired Tiger会自动删除老的日志,只保留从上次checkpoint开始恢复需要的日志。
Checkpoint
生成Checkpoint的流程主要可以分为两步,第一步是遍历内存中的数据页,将所有脏页刷到磁盘中;第二步是会将一些metadata刷到磁盘中。在系统启动时,就会根据checkpoint的metadata来构建内存中的B+树结构。Checkpoint元数据包含的信息(略)如图所示:
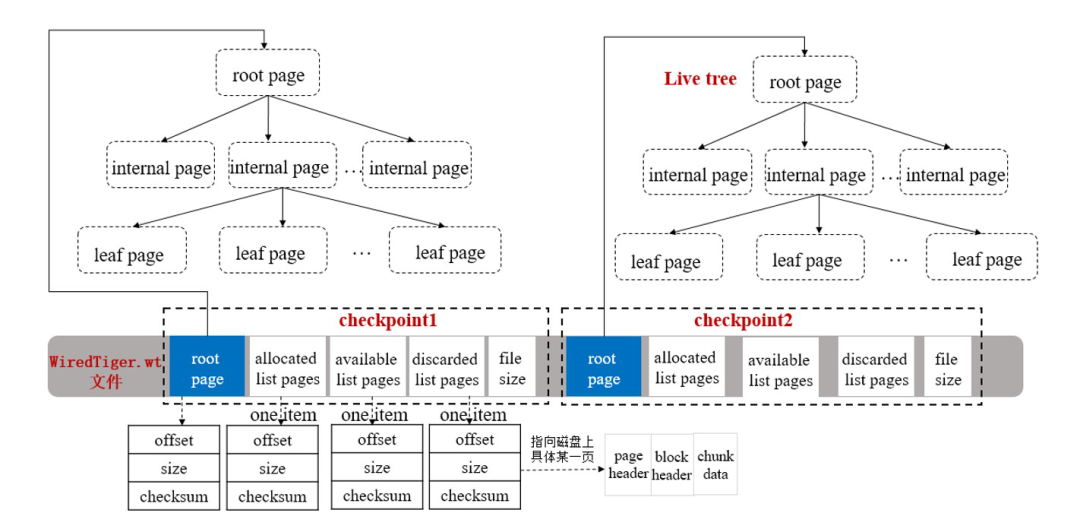
更多细节可以参考:
Cache Eviction(内存逐出)
Wired Tiger中的读写都是基于内存的,这样大大利用了内存的高速读写性能,但是内存终究是有限的,当内存使用率达到一定的阈值时,Wired Tiger将会按照LRU算法清理内存中的数据页,可能是未做过修改的数据页或者做过修改的脏页,从而释放一定的内存空间。这个过程就叫做Cache Eviction(内存逐出)。
Eviction的触发时机包括:
- WT的Cache空间的使用率达到一定阈值(80%)
- Cache中的脏页占用空间的百分比达到一定阈值
- Cache中有单个数据页的大小超过一定的阈值时
Cache Eviction流程包含Evict Pass(选取)和Evict Page(淘汰)两个步骤。
选取阶段是一个阶段性扫描的过程,一次扫描可能并不会扫描内存中全部的B+树,每次扫描结束时会记录当前扫描到的位置,下次扫描时直接从上次结束的位置开始。 扫描过程中,如果 page 满足淘汰条件,则会将 page 添加到一个 evict queue(逐出队列)中,如果evict queue 填充满了或者本次扫描遍历了所有 B+树,则结束本次扫描。 之后会对 evict queue 中的page进行评分,用于执行LRU算法,评分的依据包括每个page当前的访问次数、page类型等。
接下来进行 evict page(淘汰)阶段,这个阶段其实就是对 evict queue 中的page进行回收(可能需要刷盘)。其中刷盘的步骤在WT里称为 Reconcile,指的就是将内存中的page格式转化为磁盘的格式然后写入到磁盘的过程。
MVCC
Wired Tiger 使用 MVCC 机制实现了不同的隔离级别。在事务开始读取时,会生成一个快照(snapshot),类似于 MySQL 中 ReadView 的概念,快照保存了当前系统中所有活跃的事务id。
对于每一条数据,都会维护一个版本链,最新的修改总是会直接append到链表头上,版本链上的每个版本都记录了做出修改的事务id。 因此,当对一条记录进行读取的时候,是从链表头根据版本对应的事务id和本次读事务的 snapshot 来判断是否可读,如果不可读,向链表尾方向移动,直到找到读事务能读取的数据版本。
基于snapshot,Wired Tiger实现了三种隔离级别:
- Read-Uncommited(未提交读):其实就是脏读,不需要使用snapshot,总是读取版本链上最新的数据
- Read-Commited(已提交读):可以读到已提交的数据,可能会产生幻读。实现方式就是在每次读取之前都生成一次snapshot
- Snapshot-Isolation(快照隔离):相当于MySQL中的可重复读,只在事务开始的时候做一次snapshot,之后的读取都基于这个snapshot
BSON数据格式
MongoDB中的文档是以bson的格式进行存储的,BSON(Binary JSON)是一种类似json的数据格式,但是其支持了更多的数据类型:
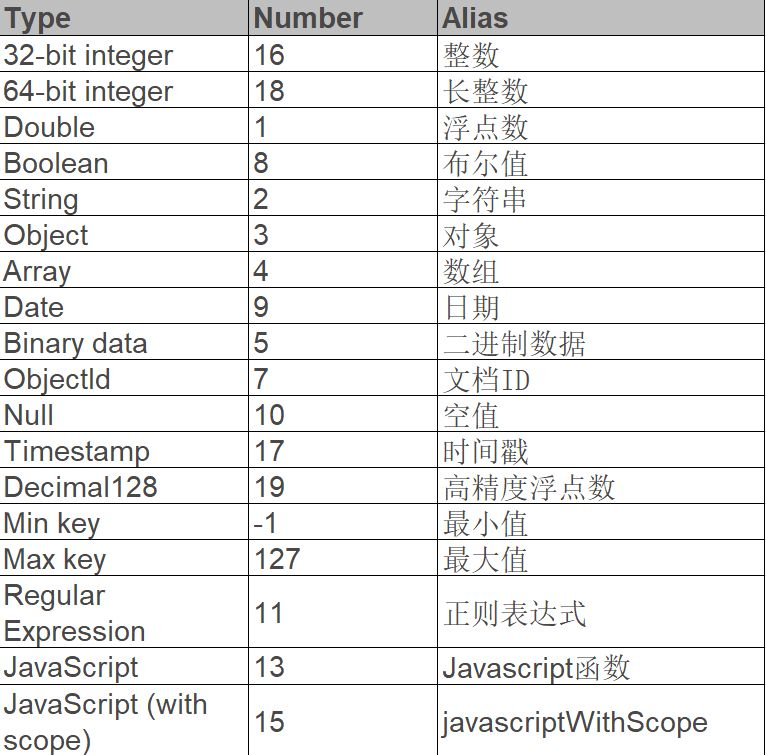
除此之外,BSON相比JSON还具有更快的遍历速度:在JSON中,要跳过一个文档进行数据读取,需要对此文档进行扫描才行,需要进行麻烦的数据结构匹配,比如括号的匹配,而BSON对JSON的一大改进就是,它会将JSON的每一个元素的长度存在元素的头部,这样只需要读取到元素长度就能直接seek到指定的点上进行读取了。