高可用性 HA(High Availability)指的是缩短因正常运维或者非预期故障而导致的停机时间,提高系统可用性。大白话就是,无论出啥事都不能让承载的业务受影响,这就是高可用。无论是数据的高可靠,还是组件的高可用全都是一个解决方案:冗余。通过多个组件和备份导致对外提供一致性和不中断的服务。冗余是根本,但是怎么使用冗余则各有不同。
MongoDB 高可用方案分两种:
- Master-Slave 主从复制
- ReplicaSets 复制集
Master-Slave 模式
Mongodb 提供的第一种冗余策略就是 Master-Slave 策略,也是分布式系统最开始的冗余策略,这种是一种热备策略。Master-Slave 由主从角色构成:
- Master(主): 可读可写,当数据有修改的时候,会将 Oplog 同步到所有连接的 Slave 上去。
- Slave(从): 只读,所有的 Slave 从 Master 同步数据,从节点与从节点之间无感知。 Master-Slave 架构一般用于备份或者做读写分离,一般是一主一从设计和一主多从设计。
主从模式存在的问题:
- 数据不一致: Master 节点可以写,Slave 节点只能同步 Master 数据并对外提供读服务,这是异步的过程。
- 可用性差:主节点挂掉后,需要人为操作处理把 slave 节点切换成 master 节点。是一个巨大的停服窗口。
MongoDB 3.6 起已不推荐使用主从模式,自 MongoDB 3.2 起,分片群集组件已弃用主从复制。因为 Master-Slave 其中 Master 宕机后不能自动恢复,只能靠人为操作,可靠性也差,操作不当就存在丢数据的风险。
ReplicaSet 副本集模式
ReplicaSets 的结构非常类似一个集群 ,其中一个节点如果出现故障, 其它节点马上会将业务接过来而无须停机操作。
Mongodb 副本集是一种典型的高可用部署模式,副本集是一组服务器,一般是一个主节点(Primary)用来处理客户端的读写请求,多个副本节点(Secondary)节点对主节点的数据进行备份,以防止主节点宕机导致的单点故障。一旦主节点宕机后,那么整个副本集会进行一次新的选举,选举出一个新的节点成为主服务器。这种副本集部署模式,在主节点挂掉后,自动进行故障转移,保证业务的可用性。
- 在副本集中,写操作必须在主节点执行,不能对备份节点执行写操作。备份节点只能通过复制功能写入数据,不接受客户端的写入请求。
- 默认情况下,客户端不能从备份节点中读取数据。在备份节点上显式地执行
setSlaveOk之后,客户端就可以从备份节点中读取数据了。
备份节点可能会落后于主机点,可能没有最新写入的数据,所有备份节点在默认情况下会拒绝读取请求,以防应用程序意外拿到过期的数据。
操作配置
下面依次执行创建副本集、使用副本集和关闭副本集的操作。
-
使用
--nodb选项启动一个 mongo shell,这样可以启动shell但是不连接到任何的mongod。1
$mongo --nodb
-
创建一个副本集,其中包含三个服务器的副本集:一个主服务器和两个备份服务器。
1
> replSet = new ReplSetTest({"nodes":3})
-
启动三个 mongod 进程
1 2 3 4
// 启动 3 个 mongod 进程 > replSet.startSet() // 配置复制功能 > replSet.initiate()
-
在第二个 shell 中,连接到运行在第一个端口的 mongod,即连接到一个副本集成员。
1
$mongo --port 20000
-
执行 isMaster命令,查看副本集状态。
1 2 3 4 5 6 7 8 9
> db.isMaster() { "isMaster": true, "hosts": [ ...:20000, ...:20001, ...:20002 ] }
-
主节点上执行写入操作:
1 2
> db.blog.insert({"title":"hello, world!!"})
-
在另一个 shell 中,连接一个备份节点
1
$mongo --port 20001
-
在备份节点上执行查找操作
1 2 3
> db.blog.find() Error: error: { "ok" : 0, "errmsg" : "not master and slaveOk=false", "code" : 13435 }
-
设置允许从备份节点读取数据,即使是过期数据,注意setSlaveOk是对连接设置的,而不是对数据库设置的
1 2 3 4
> db.setSlaveOk() > db.blog.find() {"title":"hello, world!!"}
-
不能对备份节点执行写操作
1 2 3
> db.bolg.insert({"title":"hello, world"}) WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })
-
在第一个 shell 中执行副本集关闭
1 2 3
> replSet.stopSet() ReplSetTest stopSet Shut down repl set - test worked
同步
复制用于在多台服务器之间备份数据
MongoDB 复制功能是使用操作日志 oplog 实现的,操作日志包含了主节点的每一次写操作。oplog 是主节点的 local 数据库中的一个固定集合。备份节点通过查询这个集合就可以知道需要进行复制的操作。
每个备份节点都维护着自己的 oplog,记录着每一次从主节点复制数据的操作。这样,每个成员都可以作为同步源提供给其他成员使用。备份节点从当前使用的同步源中获取需要执行的操作,然后在自己的数据集上执行这些操作,最后再将这些操作写入自己的 oplog。
由于复制操作的过程是先复制数据再写入 oplog,所以,备份节点可能会在已经同步过的数据上再次执行复制操作。MongoDB 保证将 oplog 中的同一个操作执行多次,与只执行一次的效果是一样的。
oplog 大小是固定的,只能保存特定数量的操作日志,oplog 操作的维度是文档,即如果单个操作影响多个文档,那么每个受影响的文档都会对应 oplog 中的一条日志。如果执行大量的批量操作 oplog 很快就会被填满。
选择
由于 oplog 大小是固定的,当从库加入到副本集的时候,就会检查自身状态,确定是否可以从某个成员那里进行增量同步。如果不行就需要从某个成员那里进行完整的数据复制,即 Initial Syc(全量同步)。
- 如果 local 数据库中的 oplog.rs 集合是空的,则做全量同步。
- 如果 minValid 集合里面存储的是 _initialSyncFlag(表示正在做全量同步,但全量同步失败),则做全量同步。
- 如果 initialSyncRequested 是 true,则做全量同步(用于 resync 命令,resync 命令只用于 master/slave 架构,副本集无法使用)
以上三个条件有一个条件满足就需要做全量同步。
全量同步
MongoDB 默认是采取级联复制的架构,就是默认不一定选择主库作为自己的同步源,如果不想让其进行级联复制,可以通过 chainingAllowed 参数来进行控制。在级联复制的情况下,也可以通过 replSetSyncFrom 命令来指定想复制的同步源。所以这里说的同步源其实相对于从库来说就是它的主库。
- 从库会在副本集其他节点通过以下条件筛选符合自己的同步源。通过下述筛选最后过滤出来的节点作为新的同步源。
- 如果设置了 chainingAllowed 为 false,那么只能选取主库为同步源
- 找到与自己 ping 时间最小的并且数据比自己新的节点(在副本集初始化的时候,或者新节点加入副本集的时候,新节点对副本集的其他节点至少 ping 两次)
- 该同步源与主库最新 optime 做对比,如果延迟主库超过 30s,则不选择该同步源。
- 在第一次的过滤中,首先会淘汰比自己数据还旧的节点。如果第一次没有,那么第二次需要算上这些节点,防止最后没有节点可以做为同步源了。
- 最后确认该节点是否被禁止参与选举,如果是则跳过该节点。
- 删除 MongoDB 中除 local 以外的所有数据库
- 拉取主库存量数据,即将同步源的所有记录全部复制到本地
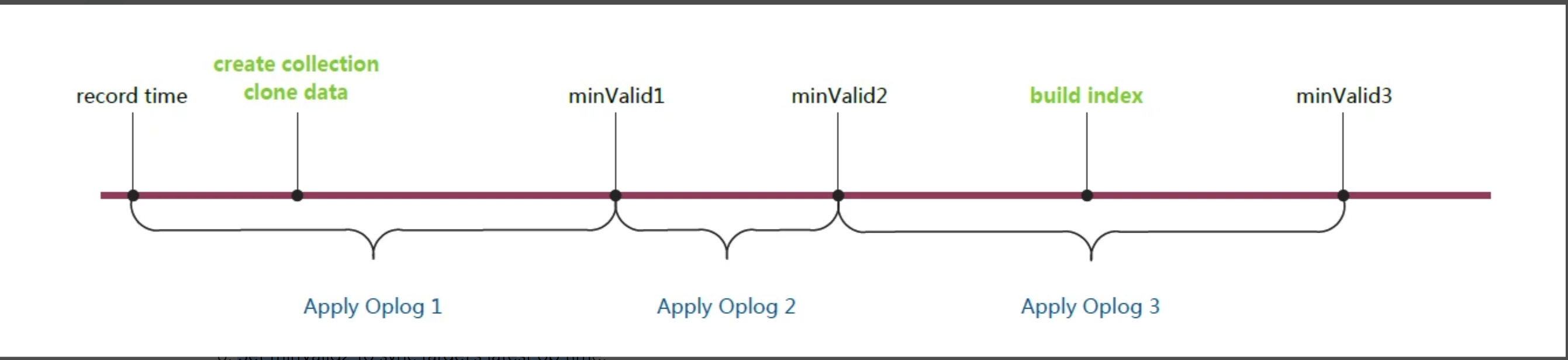
- Add _initialSyncFlag to minValid collection to tell us to restart initial sync if we crash in the middle of this procedure
- Record start time.(记录当前主库最近一次 oplog time)
- Clone.
- Set minValid1 to sync target’s latest op time.
- Apply ops from start to minValid1, fetching missing docs as needed.(Apply Oplog 1)
- Set minValid2 to sync target’s latest op time.
- Apply ops from minValid1 to minValid2.(Apply Oplog 2)
- Build indexes.
- Set minValid3 to sync target’s latest op time.
- Apply ops from minValid2 to minValid3.(Apply Oplog 3)
- Cleanup minValid collection: remove _initialSyncFlag field, set ts to minValid3 OpTime
Mongo 3.4 Initial Sync 在创建的集合的时候同时创建了索引(与主库一样),在 MongoDB 3.4 版本之前只创建 _id 索引,其他索引等待数据 copy 完成之后进行创建。
增量同步
在完成 Initial Sync 后,就是已经把同步源的存量数据拿过来了,主库后续写入的数据通过增量同步的方式进行同步。
 注:这里不一定是 Primary,同步源也可能是 Secondary。
注:这里不一定是 Primary,同步源也可能是 Secondary。
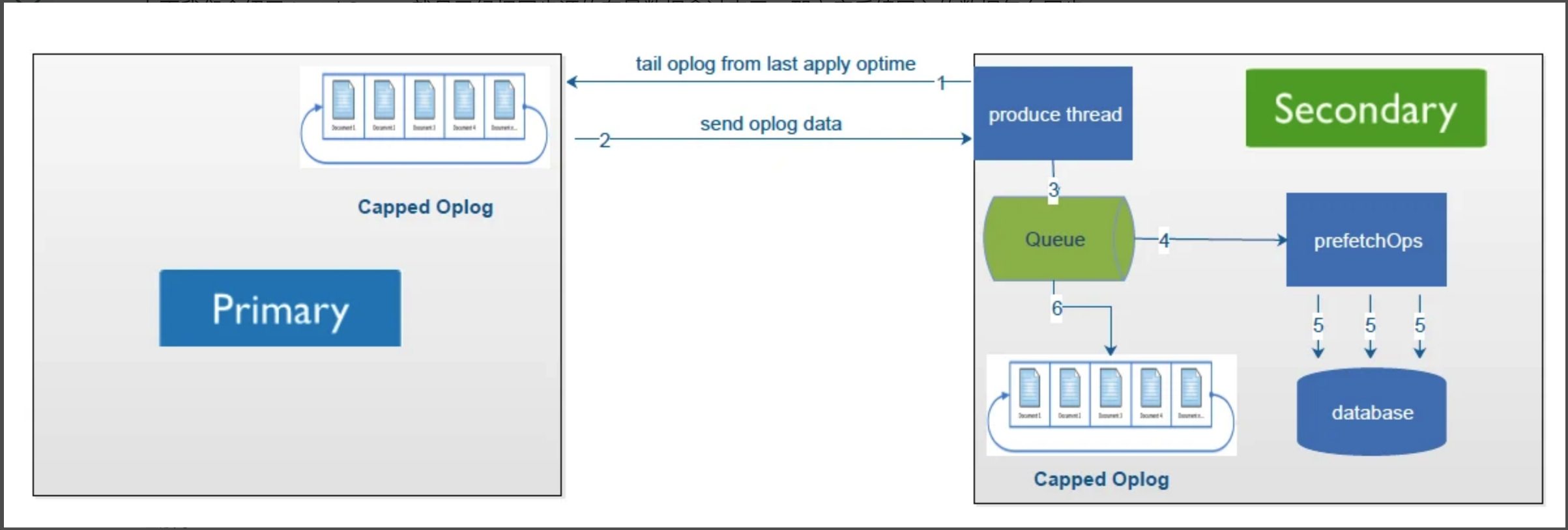
可以看到上述有 6 个步骤,那每个步骤具体做的事情如下:
- Sencondary 初始化同步完成之后,开始增量复制,通过 produce 线程在 Primary oplog.rs 集合上建立 cursor,并且实时请求获取数据。
- Primary 返回 oplog 数据给 Secondary。
- Sencondary 读取到 Primary 发送过来的 oplog,将其写入到队列中。
- Sencondary 的同步线程会通过
tryPopAndWaitForMore方法一直消费队列,当每次达到一定的条件之后,就会将数据给 prefetchOps 方法处理,prefetchOps 方法主要将数据以 database 级别切分,便于后面多线程写入到数据库中。如果采用的 WiredTiger 引擎,那这里是以 Docment ID 进行切分。满足以下条件之一即可:- 总数据大于 100MB
- 已经取到部分数据但没到 100MB,但是目前队列没数据了,这个时候会阻塞等待一秒,如果还没有数据则本次取数据完成。
- 最终将划分好的数据以多线程的方式批量写入到数据库中(在从库批量写入数据的时候 MongoDB 会阻塞所有的读)。
- 然后再将 Queue 中的 Oplog 数据写入到 Sencondary 中的 oplog.rs 集合中。
心跳
一旦一个副本集创建成功,那么每一个节点之间都保持着通信,每 2s 会向整个副本集的其他节点发一次心跳通知,也就是一个 ping 包。在任意一个节点的数据库内部,维护着整个副本集节点的状态信息,一旦某一个节点超过 10s 不能收到回应,就认为这个节点不能访问。另外,对于主节点而言,除了维护这个状态信息外,还要判断是否和大多数节点可以正常通信,如果不能,则要主动降级。
成员状态
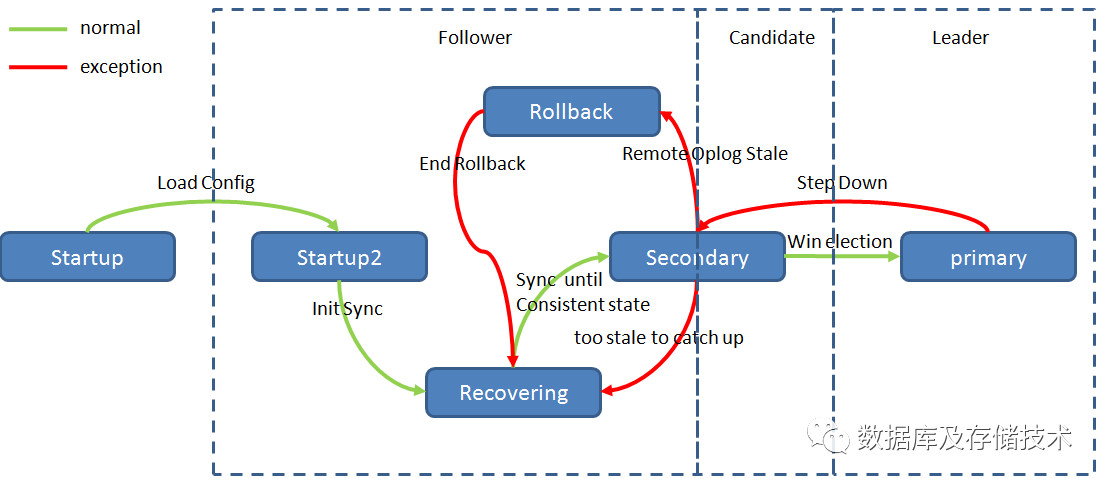
各个成员会通过心跳将自己的当前状态告诉其他成员。常见状态:
- startup: 成员刚启动时处于这个状态。在这个状态下,MongoDB 会尝试加载成员的副本集配置,配置加载成功之后,就进入 startup2 状态。
- startup2: 整个初始化同步过程都会处于整个状态。
- recovering: 这个状态表明成员运转正常,但还不能处理读请求。如果成员处于这个状态,可能会造成轻微的系统过载。
- 启动时,成员需要做一些检查以确保自己处于有效状态,之后才可以处理读取请求。
- 启动时,成为备份节点之前。
- 在处理非常耗时的操作时,成员也可能进入recovering状态。
- 当一个成员与其他成员脱节时(too stale to catch up)。
- arbiter: 不存数据,不会被选为主,只进行选主投票。使用 Arbiter 可以减轻在减少数据的冗余备份,又能提供高可用的能力。在正常操作下,仲裁者应该始终处于 arbiter 状态。
- primary: 主节点
- Sencondary: 备份节点
MongoDB 复制集成员状态机:
选举
MongoDB 3.2 版本之前选举协议是基于 Bully 算法,从 3.2 版本开始 MongoDB 的副本集协议是一种 raft-like 协议(内部叫pv1),即基于 raft 协议的理论思想实现,并且对之进行了一些扩展。
预选举(pre-vote)
先来看没有预选举阶段的 raft 协议在下面这种场景下有什么问题。
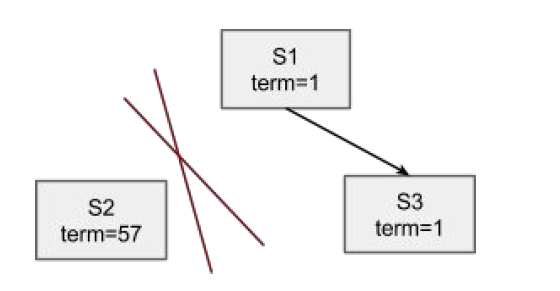
如图所示是一个有 3 个节点的集群,其中 S2 暂时与 S1 和 S3 不互通。
- 在 raft 协议中,对于 S2 这一节点而言,每次达到选举超时的时候它都会发起一次选举并自增 term。由于并不能连接到 S1 和 S3,选举会失败,如此反复,term 会增加到一个相对比较大的值(图中为57)。
- 由于 S1 和 S3 满足大多数条件,不妨假设选择 S1 成为集群新的主节点,term 变为 2。
- 当网络连接恢复,S2 又可以重新连接到 S1 和 S3 之后,其 term 会通过心跳传递给 S1 和 S3,而这会导致 S1 step down 成为从节点。
- 选举超时时间过后,集群会重新触发一次选举,无论是 S1 还是 S3 成为新的主(S2 由于落后所以不可能),其 term 值会变成 58;
上面描述的场景有什么问题呢?
- term 跳变
- 网络恢复后多了一次无意义的选举。而从 step down 到新一轮选举完成的过程中集群是无主的(不可写状态)
预选举就是为了解决上述问题的。在尝试自增 term 并发起选举之前,S2 会看看自己有没有可能获得来自 S1 和 S3 的选票。如若不满足条件则不会发起真正的选举。
选举条件: 参与选举的节点必须大于等于
N/2 + 1个节点,如果正常节点数已经小于一半,则整个副本集的节点都只能为只读状态,整个副本集将不能支持写入。也不能够进行选举。
追赶阶段(catchup)
新选出来的 primary 为何要进入这个阶段?同样的,可以分析一下没有这个阶段的话在下面这个场景有什么问题。
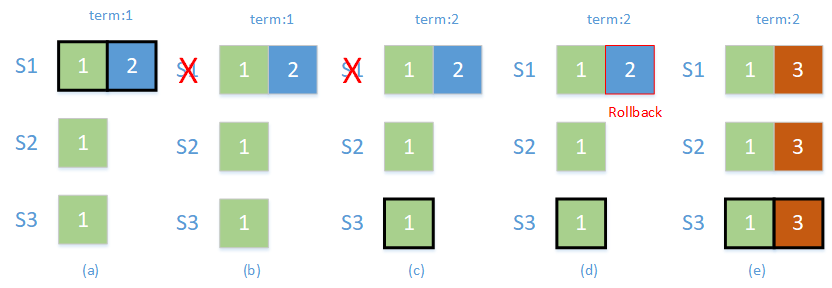
如图所示,是一个有 3 个节点的集群,分别为 S1, S2, S3
- (a) 时刻,S1 为 primary,序号为 2 的日志还没来得及复制到 S2 和 S3 上
- (b) 时刻,S1 挂掉,触发集群重新选举
- (c) 时刻,S3 成为新的 primary,term 变为 2
- (d) 时刻,S1 恢复,但是发现自己比 primary 节点有更新的日志,触发回滚(rollback)操作
- (e) 时刻,集群恢复正常,新的写入成功
上面的场景有什么问题?准确来说没什么问题,符合 raft 协议的强一致性原则,但是存在一次回滚过程。catchup 就是为了尽量避免回滚的出现而诞生的。
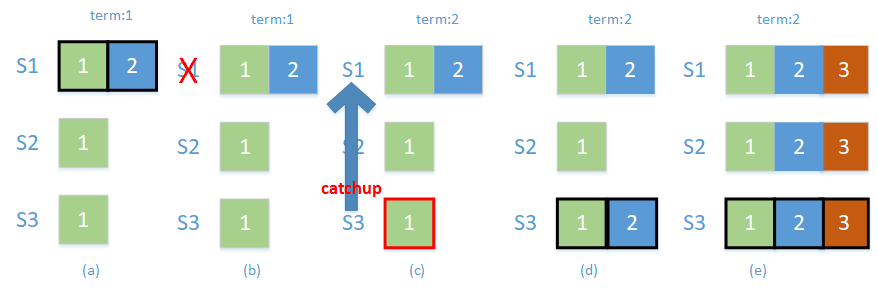
如图所示,如果 S1 在 (c) 时刻就恢复,这里的时刻应该再细化一下,是在 S3 获得了 S2 的投票成为 primary 状态之后,而不是在获得投票结果之前(否则的话 S1 不会投票给S3,本轮选举失败,等待下一轮选举,S1 会重新成为主)。S3 进入 catchup 状态,看看有没有哪个从节点存在比自己更新的日志,发现 S1 有,然后就同步到自己这边并提交,再“真正”成为主节点,支持外部的写入;然后整个副本集一切恢复正常。
注意到这一过程中是没有回滚操作的。集群通过副本集协议保留了序号为 2 的写入日志并且自愈。
catchup 是利用节点间的心跳和 oplog 来实现的。这一时间段的长短取决于旧 primary 挂之前超前的数据量。对于新的 primary 而言,“追赶”可以说是很形象了。总而言之,catchup 阶段可以避免部分场景下回滚的出现。 当然,官方贴心地提供了两个可调整的设置参数(在MnogoDB3.6以上的版本生效)用来控制 catchup 阶段,分别是:
- settings.catchUpTimeoutMillis(单位为ms)
- 默认为 -1,表示无限的追赶等待时间。即新选举出的 primary 节点,尝试去副本集内其他节点获取(追赶catchup)更新的写入并同步到自身,直到完全同步为止。
- 设置为 0 表示关闭 catchup 功能。
- settings.catchUpTakeoverDelayMillis(单位为ms)
- 默认为 30000,即 30s。表示允许新选出来的 primary 在被接管(takeover)前处于追赶(catchup)阶段的时间。
- 设置为 -1 表示关闭追赶抢占 (catchup takeover) 功能。 当追赶时间为无限,且关闭了追赶抢占功能时,也可通过 replSetAbortPrimaryCatchUp 命令来手动强制终止 catchup 阶段,完成向 primary 的过渡。
在 catchup 阶段发起写入操作,会发生什么?客户端会收到 MongoDB 返回的错误(NotMaster) not master,该错误一般出现在尝试对 seconday 节点进行写操作时。
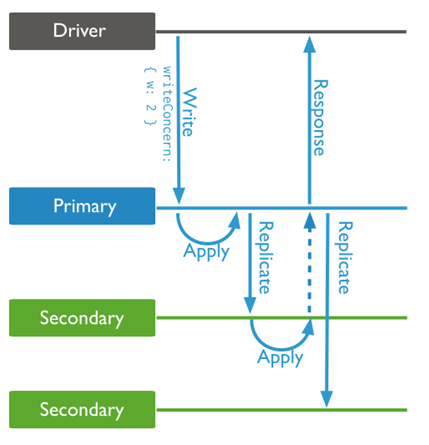
对于 MongoDB 而言,还有其他手段可以用来尽量避免回滚操作的出现,比如设置 writeConcern 为 majority(对于3节点集群而言,也可直接设置为2)来避免图中(a)情况的出现。确保新选出来的 primary 包含旧 primary 挂掉前的最新数据。
总结
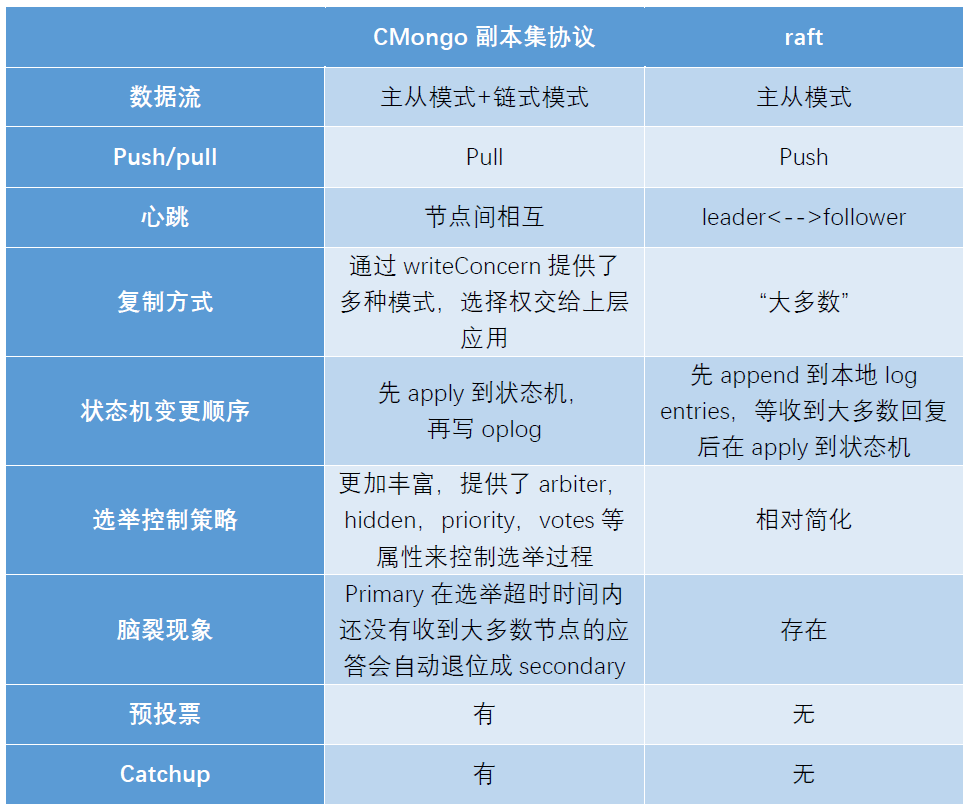
MongoDB 副本集协议与 raft 协议是有区别的:
参考文献
【3】Consensus: Bridging Theory and Practice
【4】4-modifications-for-Raft-consensus