当同一份数据存在多个副本的时候,怎么管理它们就成了问题。复制状态机用于支持那些允许数据修改的场景,比如分布式系统中的元数据。典型的例子是一个目录下的那些文件,虽然文件本身可以做到一次写入永不修改,但是目录的内容总是随文件的不断写人而发生动态变化的。
复制状态机的基本思想是一个分布式的复制状态机系统由多个复制单元组成,每个复制单元均是一个状态机,它的状态保存在一组状态变量中。状态机的状态能够并且只能通过外部命令来改变。
下图是复制状态机的结构(引用自 Raft paper),它由共识模块、日志模块、状态机组成。通过共识模块保证各个节点日志的一致性,然后各个节点基于同样的日志、顺序执行指令,最终各个复制状态机的结果实现一致。每一个复制单元存储一个包含一系列指令的日志,并且严格按照顺序逐条执行日志上的指令。因为每一个日志都是按照相同的顺序包含相同的指令,所以每一个服务器都将执行相同的指令序列,并且最终到达相同的状态。
综上所述,在复制状态机模型下,一致性算法的主要工作就变成了如何保证操作日志的一致性。
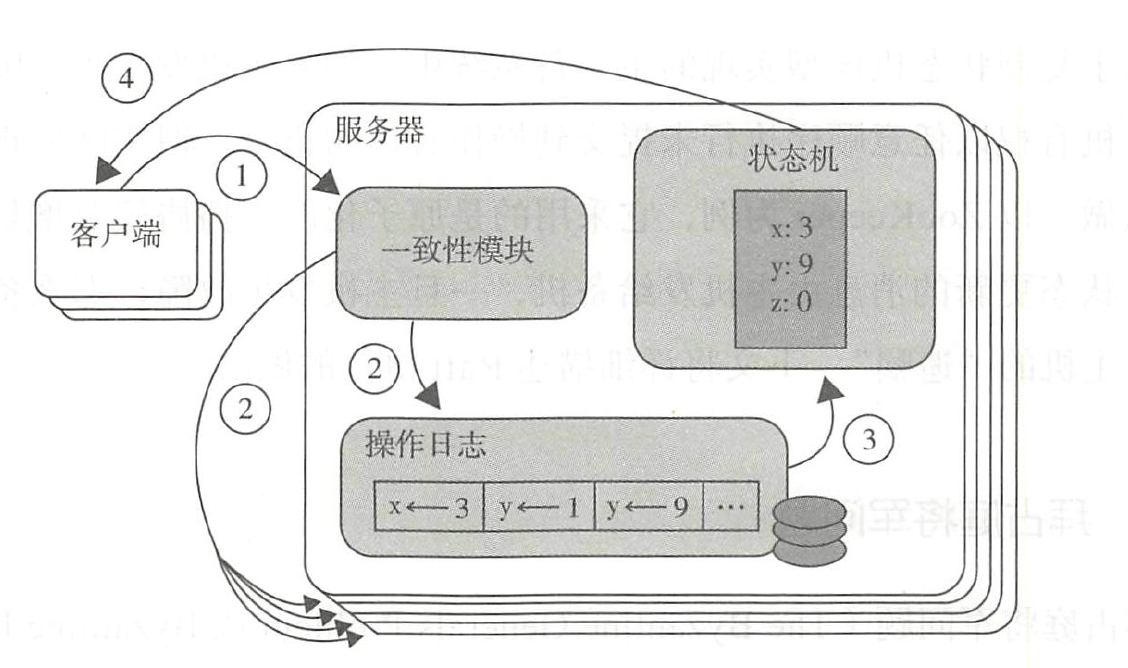
服务器上的一致性模块负责接收外部命令,然后追加到自己的操作日志中。它与其他服务器上的一致性模块进行通信以保证每一个服务器上的操作日志最终都以相同的顺序包含相同的指令。一旦指令被正确复制,那么每一个服务器的状态机都将按照操作日志的顺序来处理它们,然后将输出结果返回给客户端。
复制状态机之所以能够工作是基于下面这样的假设:如果一些状态机具有相同的初始状态,并且它们接收到的命令也相同,处理这些命令的顺序也相同,那么它们处理完这些命令后的状态也应该相同。因为所有的复制节点都具有相同的状态,它们都能独立地从自己的本地日志中读取信息作为输入命令,所以即使其中一些服务器发生故障,也不会影响整个集群的可用性。不论服务器集群包含多少个节点,从外部看起来都只像是单个高可用的状态机一样。
复制状态机在分布式系统中常被用于解决各种容错相关的问题,例如,GFS、HDFS 、Chubby 、ZooKeeper 和etcd 等分布式系统都是基于复制状态机模型实现的。
需要注意的是,指令在状态机上的执行顺序并不一定等同于指令的发出顺序或接收顺序。复制状态机只是保证所有的状态机都以相同的顺序执行这些命令。基于复制状态机模型实现的主-备系统中,如果主机发生了故障,那么理论上备机有权以任意顺序执行未提交到操作日志的指令。但实际实现中一般不会这么做。以 ZooKeeper 为例,它采用的是原子化的广播协议及增量式的状态更新。状态更新的消息由主机发给备机,一旦主机发生故障,那么备机必须依然执行主机的“遗嘱”。
状态机复制与传统复制
从状态机的概念出发,可以发现传统的复制(主从、多主)也是一种状态机,每个节点从相同的状态开始,执行一系列相同的操作以达到相同状态。这两个概念有如下区别:
- 状态机复制提供 容错机制:集群可以实现一定程度的节点失效,不会丢失已产生共识的操作
- 状态机复制提供 自动故障恢复:当主节点失效后,能自动进行选举
状态机复制就是可用性、一致性以及可靠性的平衡。在状态机复制集群中不会出现状态回滚,状态只会向前进行。