从编程的角度而言,生产者就是负责向Kafka 发送消息的应用程序。本文主要介绍 从 Kafka 0.9.x 版本开始推出的使用 Java 语言编写的客户端。
生产者架构
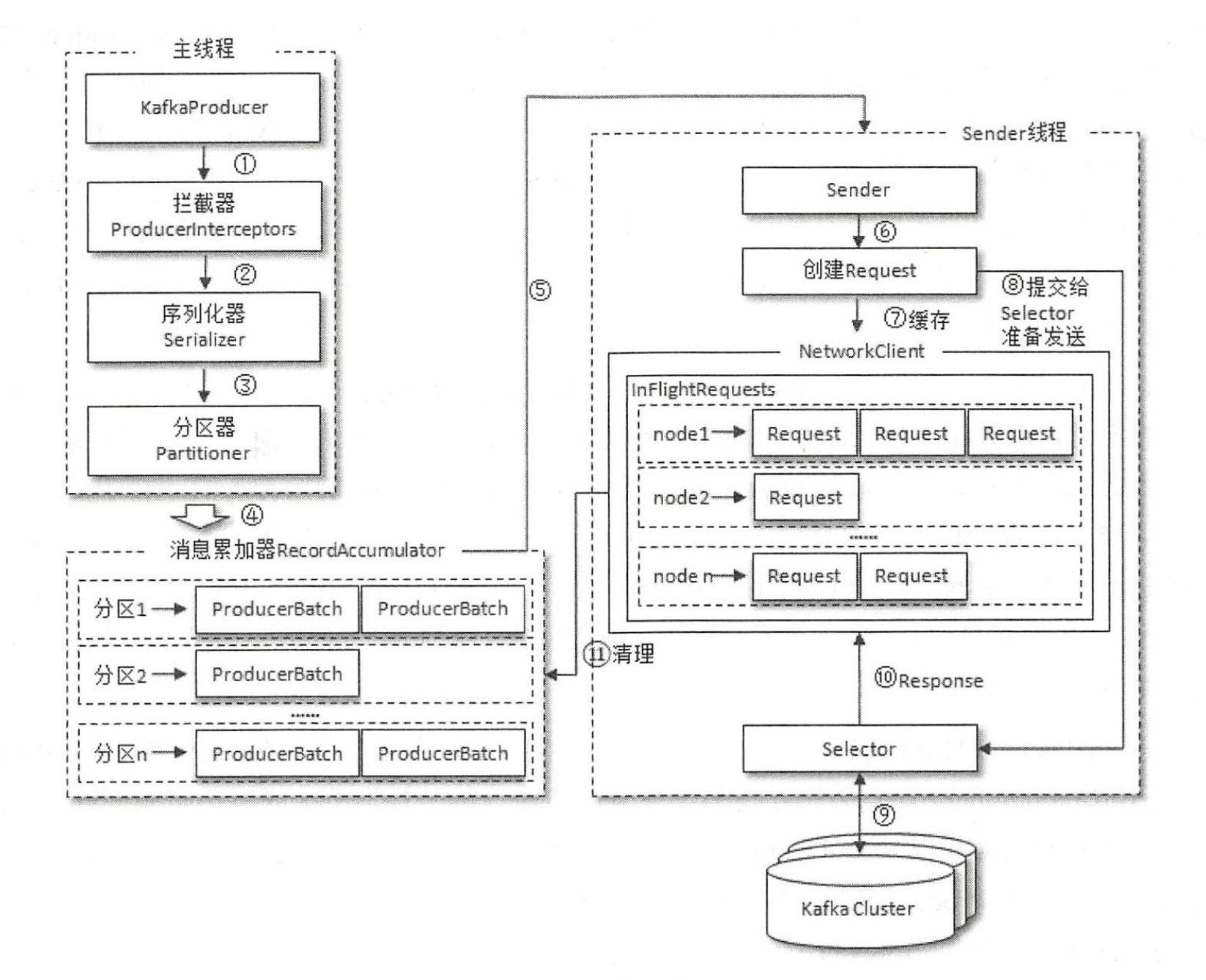
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender 线程(发送线程)。在主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator ,也称为消息收集器〉中。Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。RecordAccumulator 缓存的大小可以通过生产者客户端参数 buffer.memory 配置,默认值为 33554432B ,即32MB。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候 KafkaProducer 的 send() 方法调用要么被阻塞,要么抛出异常,这个取决于参数 max.block.ms 的配置,此参数的默认值为 60000, 即 60 秒。
主线程中发送过来的消息都会被迫加到 RecordAccumulator 的某个双端队列(Deque)中,在 RecordAccumulator 的内部为每个分区都维护了一个双端队列,队列中的内容就是 ProducerBatch ,即 Deque< ProducerBatch>。消息写入缓存时,追加到双端队列的尾部: Sender 读取消息时,从双端队列的头部读取。注意ProducerBatch 不是ProducerRecord, ProducerBatch中可以包含一至多个ProducerRecord 。通俗地说, ProducerRecord 是生产者中创建的消息,而 ProducerBatch 是指一个消息批次, ProducerRecord 会被包含在ProducerBatch 中,这样可以使字节的使用更加紧凑。与此同时,将较小的 ProducerRecord 拼凑成一个较大的ProducerBatch ,也可以减少网络请求的次数以提升整体的吞吐量。如果生产者客户端需要向很多分区发送消息, 则可以将 buffer.memory 参数适当调大以增加整体的吞吐量。
Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本<分区,Deque< ProducerBatch>>的保存形式转变成<Node, List< ProducerBatch>的形式,其中 Node 表示 Kafka 集群的 broker 节点。对于网络连接来说,生产者客户端是与具体的 broker 节点建立的连接,也就是向具体的 broker 节点发送消息,而并不关心消息属于哪一个分区;而对于 KafkaProducer 的应用逻辑而言,我们只关注向哪个分区中发送哪些消息,所以在这里需要做一个应用逻辑层面到网络 I/O 层面的转换。
在转换成<Node, List< ProducerBatch>>的形式之后, Sender 还会进一步封装成<Node, Request>的形式,这样就可以将 Request 请求发往各个 Node 了, 这里的 Request 是指Kafka 的各种协议请求,对于消息发送而言就是指具体的 ProduceRequest。
请求在从 Sender 线程发往 Kafka 之前还会保存到 InFlightRequests 中, InFlightRequests 保存对象的具体形式为Map< NodeId, Deque< Request>>,它的主要作用是缓存了已经发出去但还没有收到响应的请求( NodeId 是一个String 类型,表示节点的id 编号)。
InFlightRequests 还可以获得leastLoadedNode ,即所有 Node 中负载最小的那一个。这里的负载最小是通过每个 Node 在 InFlightRequests 中还未确认的请求决定的,未确 认的请求越多则认为负载越大。leastLoadedNode 的概念可以用于多个应用场合,比如元数据请求、消费者组播协议的交互。
生产者组件
消息结构
1
2
3
4
5
6
7
public class ProducerRecord<K, V> {
private final String topic; // 主题
private final Integer partition ; //分区号
private final Headers headers; // 消息头部
private final K key; // 键
private final V value ; // 值
private final Long timestamp ; // 消息的时间戳
- headers 字段是消息的头部,
Kafka 0.11.x版本才引入这个属性,它大多用来设定一些与应用相关的信息,如无需要也可以不用设置。 - key 是用来指定消息的键,它不仅是消息的附加信息,还可以用来计算分区号进而可以让消息发往特定的分区。前面提及消息以主题为单位进行归类,而这个 key 可以让消息再进行二次归类,同一个 key 的消息会被划分到同一个分区中。有 key 的消息还可以支持日志压缩的功能。
- value 是指消息体,一般不为空,
如果为空则表示特定的消息一一墓碑消息。 - time stamp 是指消息的时间戳,它有 CreateTime 和 LogAppendTime 两种类型,前者表示消息创建的时间,后者表示消息追加到日志文件的时间。
配置参数
在 Kafka 生产者客户端 KatkaProducer 中有 3 个参数是必填的:
bootstrap.servers: 该参数用来指定生产者客户端连接 Kafka 集群所需的 broker 地址清单,具体的内容格式为host1:port1,host2:port2,可以设置一个或多个地址,中间以逗号隔开,此参数的默认值为“” 。注意这里并非需要所有的broker 地址,因为生产者会从给定的broker 里查找到其他broker 的信息。不过建议至少要设置两个以上的broker 地址信息,当其中任意一个岩机时,生产者仍然可以连接到Kafka集群上。key.serializer 和 value.serializer: broker 端接收的消息必须以字节数组(byte[])的形式存在,在发往 broker 之前需要将消息中对应的 key 和 value 做相应的序列化操作来转换成字节数组。key.serializer和value.serializer这两个参数分别用来指定 key 和 value 序列化操作的序列化器。clien t.id,这个参数用来设定 KafkaProducer 对应的客户端id , 默认值为“” 。如果客户端不设置, 则 KafkaProducer 会自动生成一个非空字符串,内容形式如“producer-1 ”“producer-2 ” ,即字符串“ producer-“ 与数字的拼接。
发送消息
发送消息主要有三种模式:发后即忘(fire-and-forget)、同步(sync)及异步(async)。
- 发后即忘:在某些时候(比如发生不可重试异常时)会造成消息的丢失。这种发送方式的性能最高,可靠性也最差。
- 同步发送:这种方式可靠性高,要么消息被发送成功,要么发生异常。
- 异步发送:指定一个 Callback 的回调函数,Kafka 在返回响应时调用该函数来实现异步的发送确认。
KafkaProducer 中一般会发生两种类型的异常: 可重试的异常和不可重试的异常。对于可重试的异常,如果配置了 retries 参数,那么只要在规定的重试次数内自行恢复了,就不会抛出异常。
有些发送异常属于可重试异常,比如 NetworkException,这个可能是由瞬时的网络故障而导致的,一般通过重试就可以解决。对于这类异常,如果直接抛给客户端的使用方也未免过于兴师动众,客户端内部本身提供了重试机制来应对这种类型的异常,通过 retries 参数即可配置。默认情况下, retries 参数设置为 0 ,即不进行重试,对于高可靠性要求的场景, 需要将这个值设置为大于 0 的值,与 retries 参数相关的还有一个 retry.backoff.ms 参数,它用来设定两次重试之间的时间间隔,以此避免无效的频繁重试。在配置 retries 和 retry.backoff.ms 之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间大于这个异常恢复时间,以此来避免生产者过早地放弃重试。如果不知道 retries 参数应该配置为多少, 则可以参考 KafkaAdminClient ,在 KafkaAdminClient 中 retries 参数的默认值为 5。
注意如果配置的 retries 参数值大于0 ,则可能引起一些负面的影响。由于默认的 max.in.flight.requests.per.connection 参数值为 5 ,这样可能会影响消息的顺序性,对此要么放弃客户端内部的重试功能,要么将
max.in.flight.requests.per.connection 参数设置为 1 ,这样也就放弃了吞吐。其次,有些应用对于时延的要求很高,很多时候都是需要快速失败的,设置 retries> 0 会增加客户端对于异常的反馈时延,如此可能会对应用造成不良的影响。
分区
所谓分区策略是决定生产者将消息发送到哪个分区的算法,Kafka 默认分区策略实际上同时实现了两种策略:如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。
Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务 ID 等;也可以用来表征消息元数据。一旦消息被定义了 Key,那么就可以保证同一个Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略。
基于地理位置的分区策略: 当然这种策略一般只针对那些大规模的 Kafka 集群,特别是跨城市、跨国家甚至是跨大洲的集群。
DefaultPartitioner 实现(Java)
在默认分区器 DefaultPartitioner 的实现中,如果 key 不为 null ,那么默认的分区器会对 key 进行哈希(采用 MurmurHash2 算法,具备高运算性能及低碰撞率),最终根据得到的哈希值来计算分区号, 拥有相同 key 的消息会被写入同一个分区。如果 key 为 null ,那么消息将会以轮询的方式发往主题内的各个可用分区。
如果 key 不为 null ,那么计算得到的分区号会是所有分区中的任意一个。如果 key 为 null,那么计算得到的分区号仅为可用分区中的任意一个,注意两者之间的差别。
在不改变主题分区数量的情况下, key 与分区之间的映射可以保持不变。不过, 一旦主题中增加了分区,那么就难以保证 key 与分区之间的映射关系了。
拦截器
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等, 也可以用来在发送回调逻辑前做一些定制化的需求,比如统计 类工作。
实现(Java)
生产者拦截器的使用也很方便,主要是自定义实现 org.apache.kafka.clients.producer.Producerlnterceptor 接口。ProducerInterceptor 接口中包含3 个方法:
1
2
3
public ProducerRecord<K, V> onSend (ProducerRecord<K, V> record);
public void onAcknowledgement(RecordMetadata metadata, Excepti on exception );
public void close() ;
KafkaProducer 在将消息序列化和计算分区之前会调用生产者拦截器的 onSend() 方法来对消息进行相应的定制化操作。
KafkaProducer 会在消息被应答( Acknowledgement )之前或消息发送失败时调用生产者拦截器的 onAcknowledgement()方法,优先于用户设定的 Callback 之前执行。这个方法运行在 Producer 的I/O 线程中,所以这个方法中实现的代码逻辑越简单越好,否则会影响消息的发送速度。
close() 方法主要用于在关闭拦截器时执行一些资源的清理工作。在这 3 个方法中抛出的异常都会被捕获并记录到日志中,但并不会再向上传递。
如果拦截链中的某个拦截器的执行需要依赖于前一个拦截器的输出,那么就有可能产生“副作用”。设想一下,如果前一个拦截器由于异常而执行失败,那么这个拦截器也就跟着无法继续执行。在拦截链中,如果某个拦截器执行失败,那么下一个拦截器会接着从上-个执行成功的拦截器继续执行。