编码格式
文本格式
JSON 、XML 和 csv 都是文本格式,因此具有不错的可读性,通常作为数据交换格式(即将数据从一个组织发送到另一个组织)。
缺点
- 数字编码有很多模糊之处;在 XML和 CSV中,无法区分数字还是字符串;JSON可以区分数字,但是不区分整数和浮点数,且不指定精度,另外对大于2^53的大整数也不能精确解析(这也是为什么很多int64编码为JSON时,有时会使用字符串表示,Js 不能精确解析 int64 数值)
- 不支持二进制数据;需要通过 Base64 编码这类先进行字符转换;
- csv 没有任何模式(csv 中没存key,只存 value),因此应用程序需要定义每行和每列的含义。
这三者中JSON最为轻量,且前端的JavaScript支持良好,目前最为流行。
这些字符文本内容也是需要通过 字符编码 才能转换为 字节序列 从而传输/存储的,以JSON为例:
1
2
3
4
5
{
"UserName":"Martin",
"favoriteNumber":1337,
"interests":["daydreaming","hacking"]
}
当使用 UTF-8 编码时,一个字节一个英文,除开空格编码后,一共 81 个字节。 这里可以看到朴素 JSON 编码的一些特点:
- 通过 {}”:,[] 等作为切分符,一个占用一个字节
- 数字也会被当做普通字符进行编码,一位数就一个字节
- Key 的字符名称 被直接编码在内容数据中了
JSON 也有一些变体(如MessagePack/BSON/BJSON等) ,对以上的问题进行了一些优化。
以 MessagePack 为例,只需 66 个字节就可以了,它的优化点是:
- 通过记录各种长度进行切分,而不是通过冗余的 { “ : }
- 数字 1337 使用 uint16(两个字节)而非字符表示
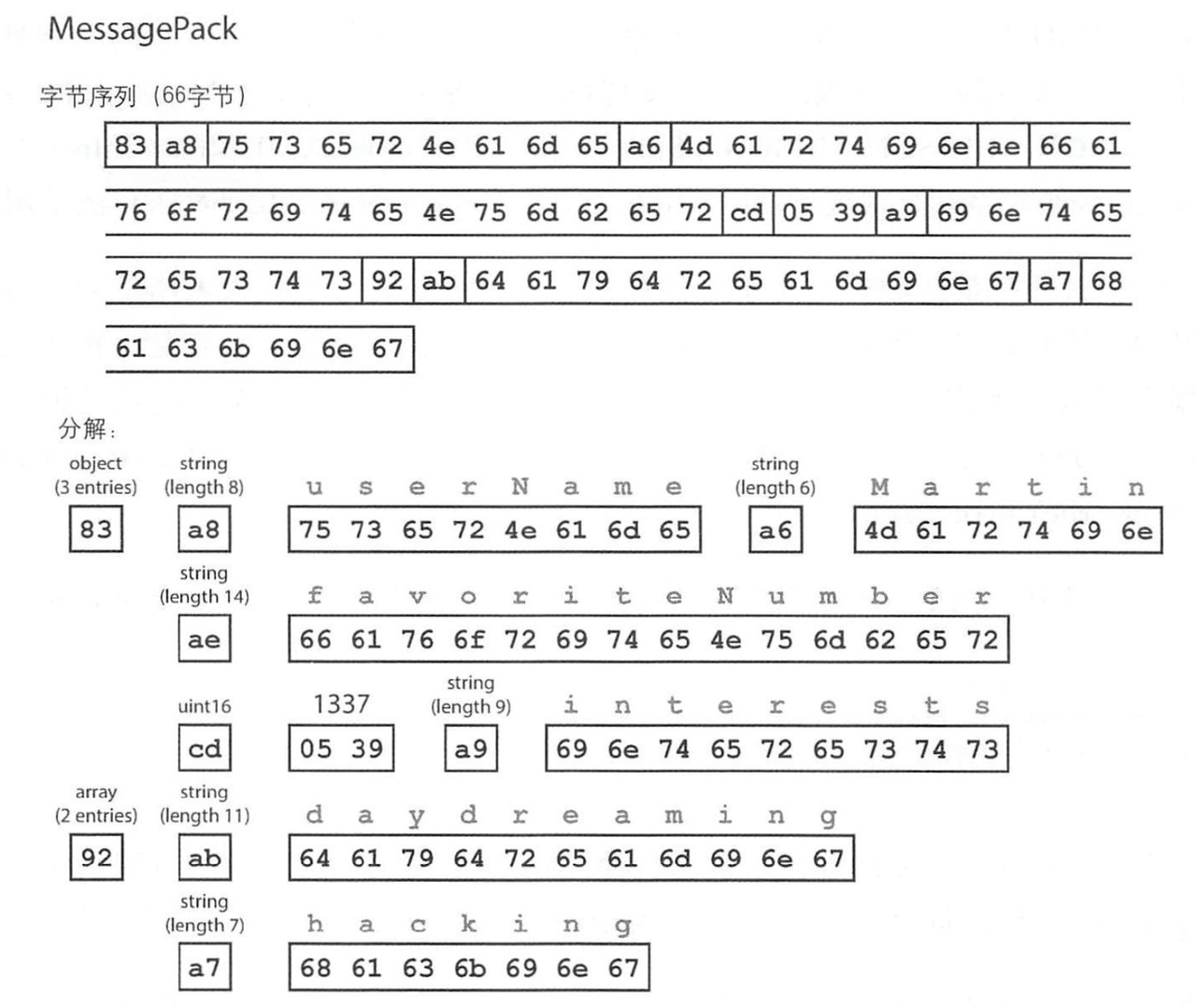
MessagePack 可以认为是 JSON 的一个二进制变体,相对而言,朴素的 JSON 是对 原文本所有字符 原汁原味的编码。
通常讲的 “文本格式编码”,通常指的是没指定什么长度类型啥的,而是 看到什么文本(Unicode) 编码后就是什么(如通过纯粹的UTF-8字符编码)
二进制格式
Apache Thrift 和 Protocol Buffers(protobuf) 是基于相同原理的两种二进制编码库。
Thrift
Thrift 通过接口定义语言(IDL:interface definition language )来描述模式(Schema),如:
1
2
3
4
5
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
Thrift 又分为 BinaryProtocol 和 CompactProtocol 两种方式;
当使用 Thrift BinaryProtocol 编码时:
- 一个字段的
Key-Value = 字段Type + 字段Tag + 字段值:- 字段Type:Thrift 定义的类型,1字节,如 string=11,i64=10,list=15
- 字段Tag:IDL 中定义的序号,2字节,如1=userName,2=favoriteNumber
- 字段值(不同类型的字段有不同的方式):
- string:字符串长度(4字节)+ 字符编码后的字符串序列;
- i64:64bit的整数值(8字节)
- list:item类型 + item个数 + item值(多个)
- 字节序列的结尾 会有一个 0x00 进行标记结束;
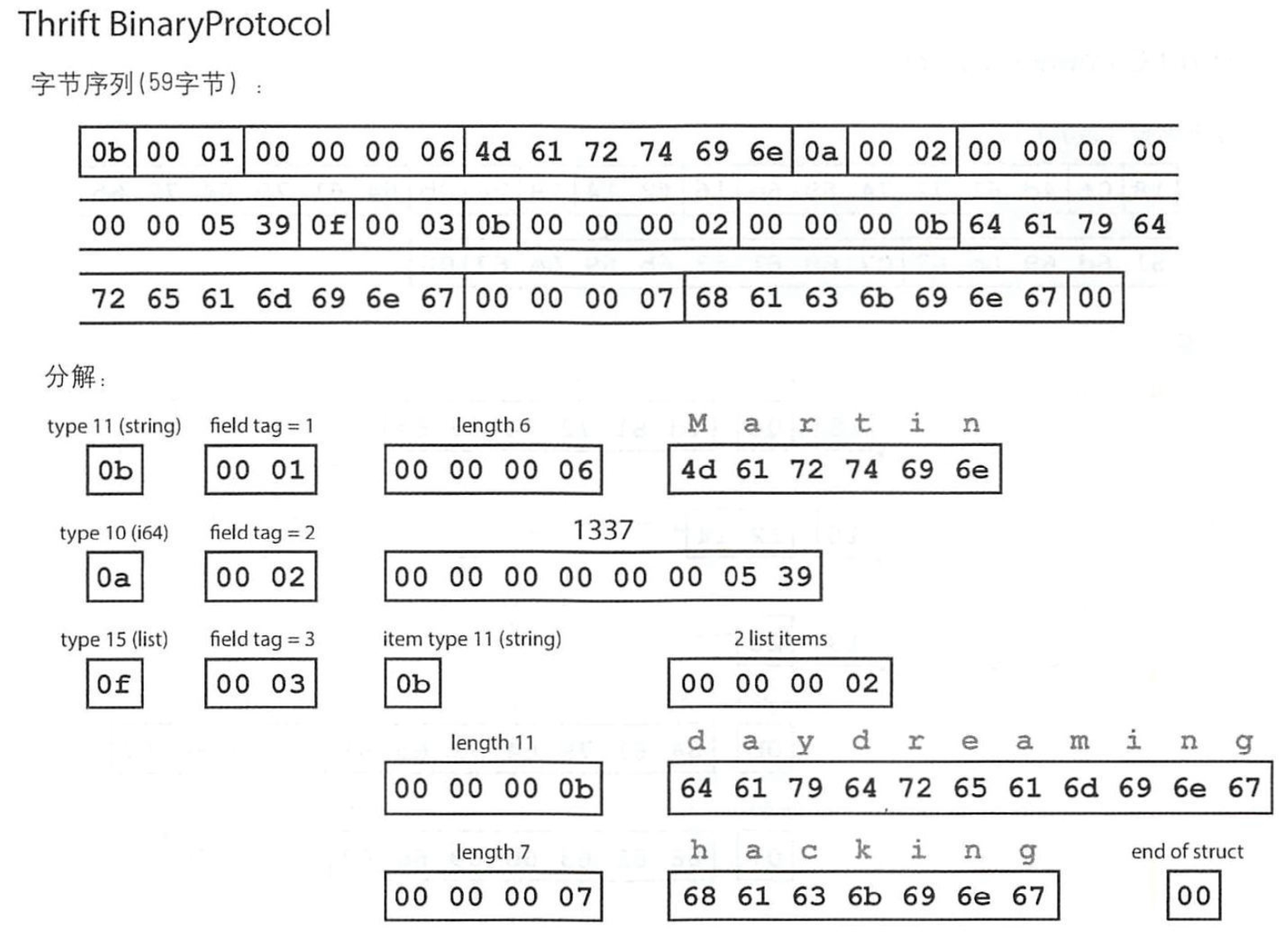
和JSON的一个明显不同是:字段的Key 通过 IDL中的Tag 标识,从而节省了空间(Key:N字节 -> 固定2字节);同样的数据:JSON为81字节,Thrift BinaryProtocol为59字节。
___;
Thrift CompactProtocol 原理 和 BinaryProtocol类似,只是通过一些手段压缩了一下。
由下图可以看出:
- 字段Tag和Type合并为一个字节:
- 字段Tag 使用 4bit记录,标识的方式为:第一个字段Tag为1 ([0001]),第二个字段Tag则是在上一个的基础上再加1([0001]),即1+1=2;第三个字段Tag再加1([0001]),即2+1=3;
- 字段Type 使用 4bit记录,最大支持2^4=16种类型,目前是已经覆盖了Thrift定义的类型;
- 数字支持可变长度:通过每个字节的首位bit 标识接下来是否还有更多字节(共同组成一个数字):
- 以 1337为例,之前i64需要8个字节,而现在只要 2个字节:
- 1337 的二进制为:[0010100 111001],另外还有个符号位(sign)为0(负数则为1)
- 从右到左:
- 先捞7位:111001 0(sign) ,因为前面还有非0的数,首位bit标识为1,组成首个字节;
- 再捞7位:0010100 ,因为前面都是0了,首位bit标识为0,组成第二个字节,完事。
- 可以看到:以前一个字节8bit都存数字值,现在只有7bit了,这也意味着编码大数时,可能体积会比原来的大;不过更常见的是小数的编码。
- 以 1337为例,之前i64需要8个字节,而现在只要 2个字节:
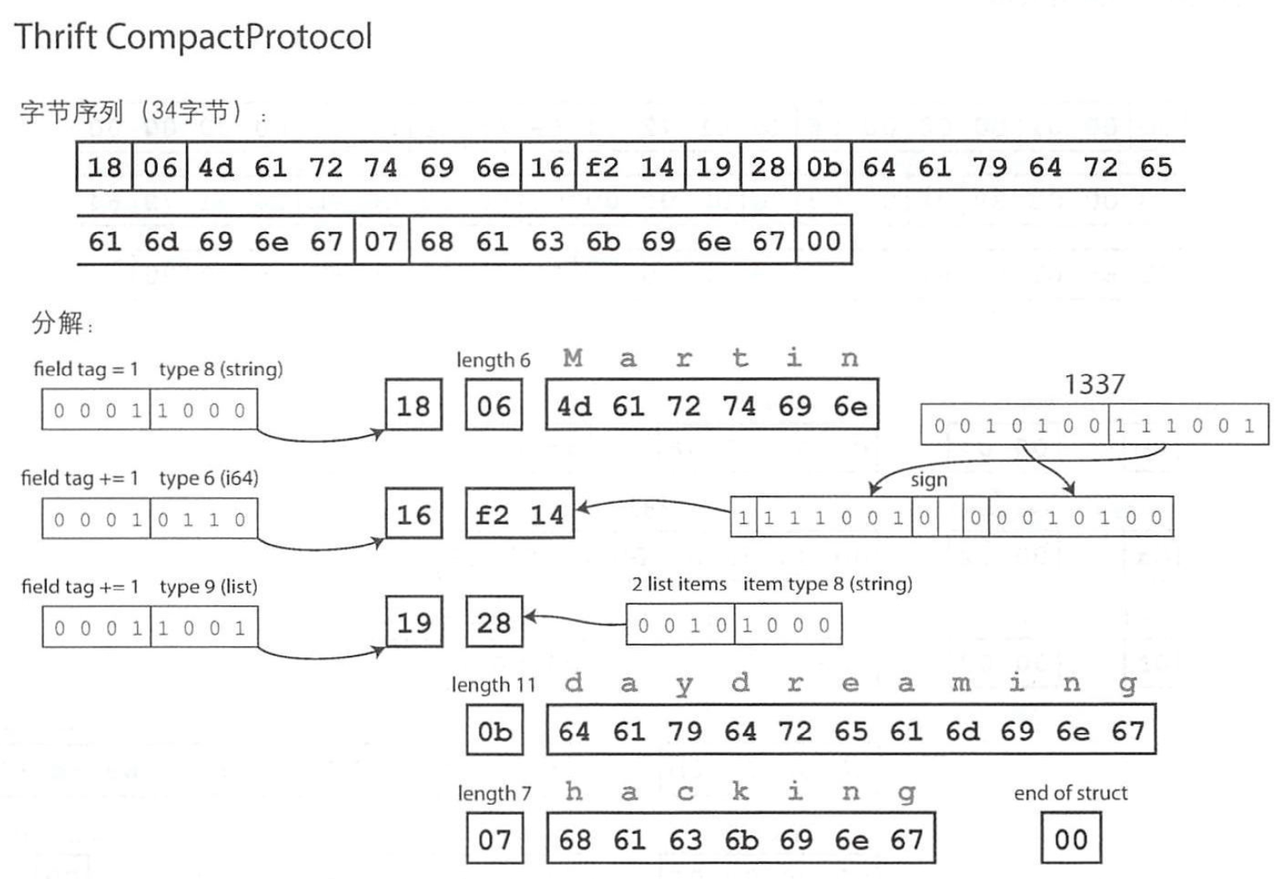
显然,Thrift CompactProtocol 有着更小的体积,不过因为要解析tag/可变长度数字等,消耗的计算资源会更多一些(相对于 BinaryProtocol),是比较典型的时间换空间。
Protocol Buffers
1
2
3
4
5
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
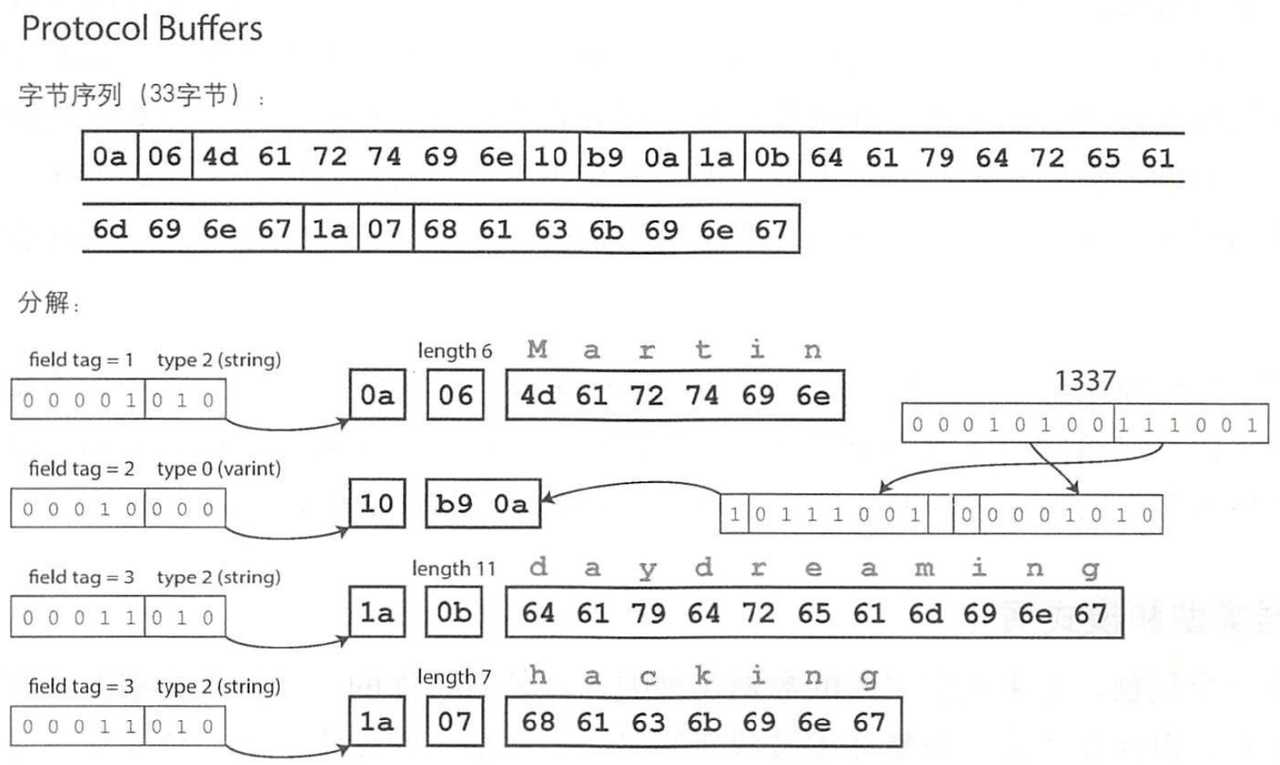
Protocol Buffers 和 Thrift的 CompactProtocol 非常相似,区别主要在:
- 去除了一个字节的结束标识符(end of struct) 0x00;
- 数字的符号位(sign)通过最后一个字节保存;
- 字段type定义不一样,tag和type组合的字节略有区别;
在前面所示的模式中 ,每个字段被标为required 或optional (可选) , 但这对字段如何编码没有任何影响(二进制数据中不会指示某字段是否必须,如果为null会直接不放进数据中)。区别在于,如果字段设置了 required,但字段未填充,则运行时检查将出现失败, 这对于捕获错误非常有用。
模式演变与兼容
这里讨论的模式演变,主要是看 Schema修改后,编解码的 向前向后兼容情况;
用上面Thrift的IDL模式定义举例:
1
2
3
4
5
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
Case1:字段名修改,如 userName 修改为 userId: 编码后的二进制数据,其实是不包含字段名称的;无论是旧代码还是新代码,都是基于Tag编解码的,所以修改字段名称非常轻松,不用担心兼容的问题(向前/向后兼容)
Case2:tag修改,如 1: …userName -> 4: …userName: 显然,因为 编解码都是基于Tag来进行了,此时向前向后兼容均丢失:
- 向后兼容丢失:旧代码编码后:1 zhangsan ,新代码解码时,基于tag=4去解码,是无法解析到相同字段(userName)的;
- 向前兼容丢失:新代码编码后:4 zhangsan,旧代码基于tag=1解码同样解析不到。
Case3:整数类型修改,如:i64 -> i32: 从编程语言中的代码角度看(我们最终会解析到对象/结构体/数组中),这个就比较明显了:
- 向后兼容丢失:旧代码编码为一个 i64数字,但是新代码解码时,最终只能填充到一个i32的数字,此时会发生截断;
- 支持向前兼容:新代码编码为一个i32数字,旧代码解析器 解码后,高32位只需填充0就能转为一个64bit的数字了;
___;
Case4:增加可选字段,如:增加 4:optional i64 id:
- 支持向后兼容:新代码解码老数据时,没有这个字段值,因为是可选的,所以没问题;
- 支持向前兼容:老代码解码新数据时,因为基于旧模式,解析时直接忽略新字段,所以没问题;
___;
Case5:数组类型变更:
- Protobuf 没有列表或数组数据类型,而是有字段的重复标记(repeated,这是必需和可选之外的第三个选项)。对于重复字段,表示同一个宇段标签只是简单地多次出现在记录中。可以将可选(单值)字段更改为重复(多值)字段。读取旧数据的新代码会看到一个包含零个或一个元素的列表(取决于该字段是否存在)。读取新数据的旧代码只能看到列表的最后一个元素。
- Thrift 有专用的列表数据类型,它使用列表元素的数据类型进行参数化。它不支持 Protobuf 那样从单值到多值的改变,但是它具有支持嵌套列表的优点。
总结:
- 可以更改模式中字段的名称,因为编码永远不直接引用字段名称。
- 不能随便更改字段的标签,它会导致现有编码数据无效。
- 可添加新的字段到模式,只要给每个字段一个新的标记号码。但新的字段无法成为必需字段。如果要添加字段并将其设置为required,当新代码读取旧代码写入的数据,则该检查将失败,因为旧代码不会写入添加的新字段。因此,为了保持向后兼容性,在模式的初始部署之后添加的每个字段都必须是可选的或具有默认值。
- 只能删除可选的字段(必填字段永远不能被删除),而且不能再次使用相同的标签号码(可能仍然有写入的数据包含旧的标签号码,而该字段必须被新代码忽略)。
优点
Protocol Buffers、Thrift都使用了模式来描述二进制编码格式:
- 它们可以比各种“二进制JSON”变体更紧凑,可以省略编码数据中的字段名称。
- 它们的模式语言比XML模式或JSON模式简单得多,它支持更详细的验证规则。
性能与体积对比
性能测试参考:
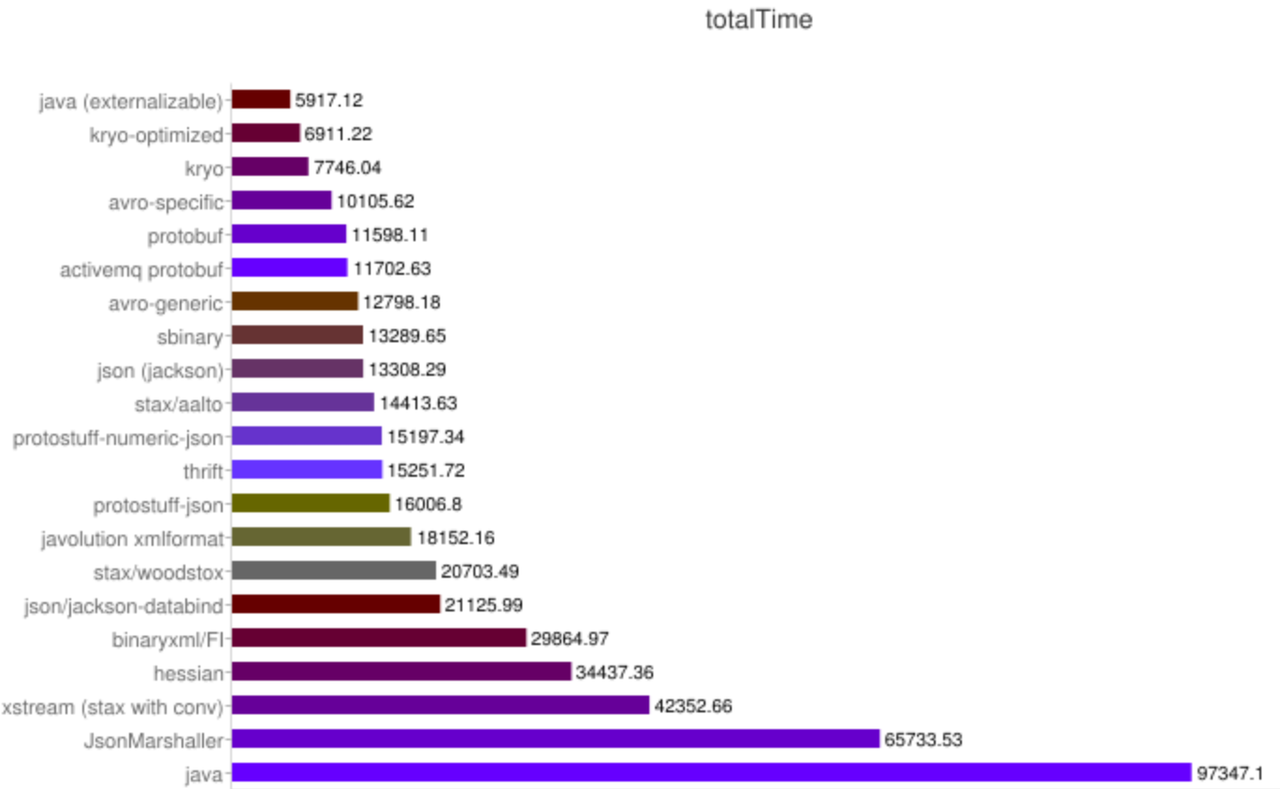
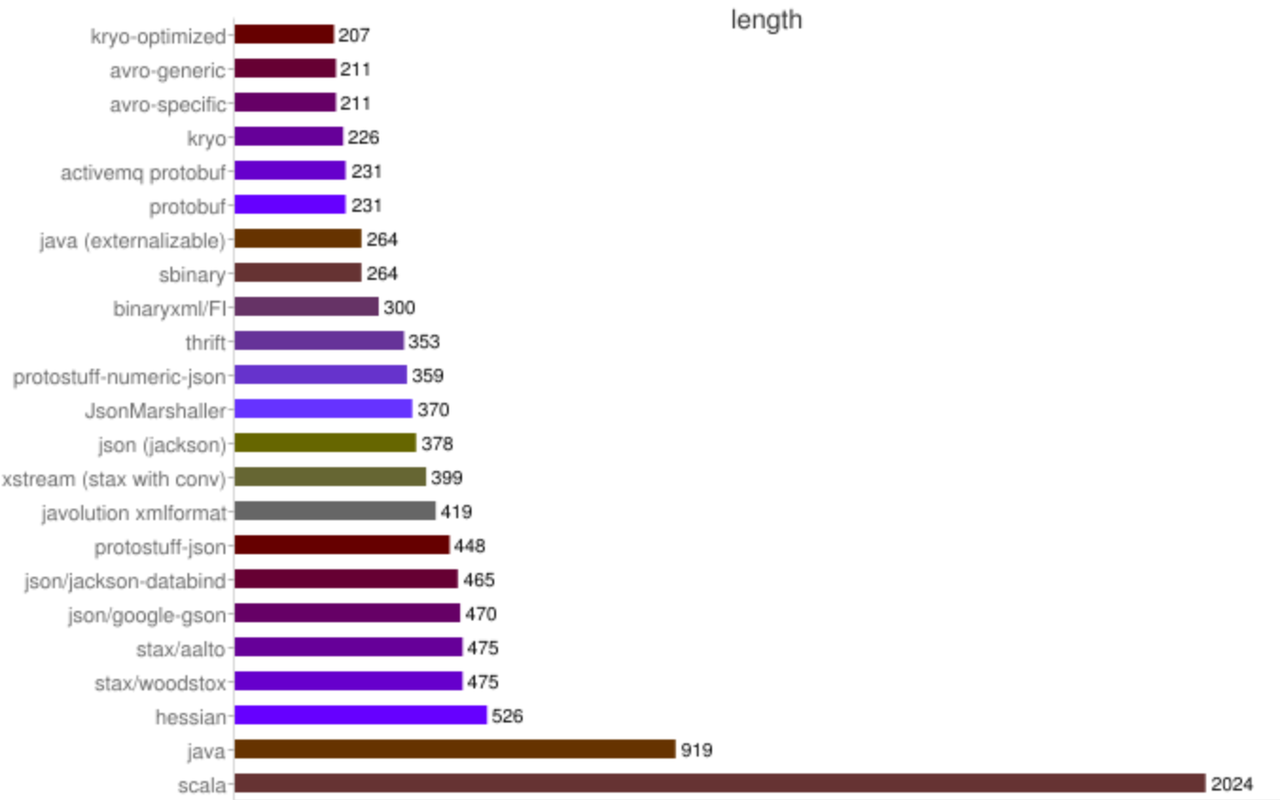
就本文讨论的协议,不考虑各种变体(非严谨排序):
- 体积大小: Protocol Buffers < Thrift CompactProtocol < BinaryProtocol « json < xml
- 性能高低: Protocol Buffers >= Thrift BinaryProtocol > CompactProtocol > json > xml
值得注意的是:编码协议只是描述了协议的格式,同样的协议 不同的生成过程 性能可能差异较大(比如上图中几种 json的序列化库的性能差异);另外编码的目标(大小、结构复杂度等)差异也会带来性能上的差异,参考 dubbo(一个Java RPC框架)的性能测试报告
另外一些 特定语言的编码协议往往更加有优势(因为不用考虑跨语言实现),比如上图中的 仅支持Java的Kryo 无论是体积还是性能都非常优秀。
关于编码格式对比参考:Comparison of data-serialization formats 注:对于 字符编码 的方式仍然基于我们常说的 GBK/UTF-8/16等,可以认为是两个层面的东西,不过序列化时,会包含字符编码的活。
应用场景
编码应用的主要目标为:1. 网络通信 2. 存储
RPC
通常而言,RPC的基本流程为:
- 客户端:
- 组装请求 Struct实例 / 对象(如LoginReq);
- 基于双方约定的 编码协议(如Thrift/PB/Json等),将对象 编码为 字节序列([ ]byte)
- 基于双发约定的 通信协议(如Thrift/HTTP等),组装为 协议报文(如HTTP报文),将数据通过TCP发送出去;
- 服务端:
- 接收到 请求报文,解析到 LoginReq对象 对应的 字节序列([ ]byte);
- 基于双方约定的 编码协议(如Thrift/PB/Json等),将 字节序列 解码为 对象;
- 执行本地调用逻辑;获得结果对象 LoginResp
- 编码LoginResp对象,组装通信协议包,通过TCP发出去;
- 客户端端
- 接收到 响应报文,解析 到字节序列,再进行解码,就可以获取到LoginResp对象了。

数据库
Redis
set key value:
- 客户端:
- 将 Key 和 Value 进行编码,将对象转换为 字节序列;
- 基于Redis的通信协议,发送 编码后的 字节序列;
- 服务端:
- 基于Redis的通信协议,解析 到 Key 和 Value字节序列([ ]byte);
- 直接基于 Key/Value的字节数组进行存储:key的[ ]byte –> value的[ ]byte

get key:
- 客户端:
- 将 Key 进行编码,将对象转换为 字节序列;
- 基于Redis的通信协议,发送 编码后的 字节序列;
- 服务端:
- 基于Redis的通信协议,解析 到 Key字节序列([ ]byte);
- 直接基于 Key 的字节数组,从 Redis的存储中(一个Map)获取到Value的字节数组;
- 基于Redis通信协议,将Value的字节数组 发回到客户端;
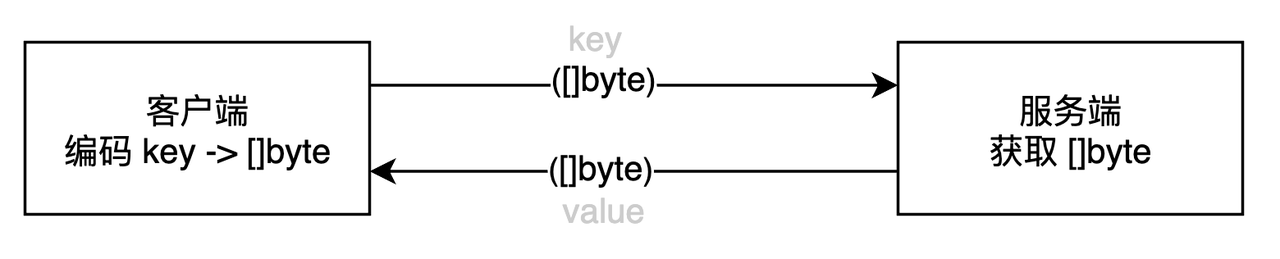 从这里可以看出,编码的形式服务端是不进行参与的,客户端怎么存的,服务端就怎么返回。
从这里可以看出,编码的形式服务端是不进行参与的,客户端怎么存的,服务端就怎么返回。
Mysql
insert into t values (‘1’, ‘张三’):
- 客户端:
- 建立连接,指定字符编码characterEncoding=GBK;
- 编码 包含 SQL 在内的相关请求数据,得到字节序列 (字符编码=GBK)
- 基于通信协议发出;
- 服务端:
- 基于通信协议,字符编码=GBK,解码获取到SQL字符;
- 组装相关的 sturct 对象(如基于schema的 id=’1’, name=’张三’, ‘xxx’=null);
- 进行序列化(字符编码为utf8/utf8mb4),插入磁盘数据;

当进行 select 时,先从磁盘(缓存) 获取到字节序列,然后解码成 sturct 对象,然后再基于通信协议进行编码,再发出去。
如果客户端在连接时没有指定编码(characterEncoding=xxx),此时服务端会使用自己配置的 character_set_client,如果客户端和服务端的 字符编码不一致,解析到的字符就可能发生乱码。
MySQL 存储使用的编码方式,是根据自己的存储引擎来指定的,和我们常说的Thrift/PB这些都不太一样。当 Schema 发生变化时,MySQL InnoDB 是直接将迁移到一个新表,以保证后续读写的兼容。
异步消息传递
以 RoketMQ 为例,和 Redis 类似,其服务端是不参与 具体记录的编码,它只管来什么存什么;至于使用什么编码方式,只要生产者和消费者约定好就行了。
