协同服务用来存储服务配置信息、提供分布式锁等能力。
服务目标
一个协调服务,理想状态下大概需要满足以下五个目标:
-
可用性角度:高可用。协调服务作为集群的控制面存储,它保存了各个服务的部署、运行信息。若它故障,可能会导致集群无法变更、服务副本数无法协调。业务服务若此时出现故障,无法创建新的副本,可能会影响用户数据面。
-
数据一致性角度:提供读取“最新”数据的机制。既然协调服务必须具备高可用的目标,就必然不能存在单点故障(single point of failure),而多节点又引入了新的问题,即多个节点之间的数据一致性如何保障?比如一个集群 3 个节点 A、B、C,从节点 A、B 获取服务镜像版本是新的,但节点 C 因为磁盘 I/O 异常导致数据更新缓慢,若控制端通过 C 节点获取数据,那么可能会导致读取到过期数据,服务镜像无法及时更新。
-
容量角度:低容量、仅存储关键元数据配置。协调服务保存的仅仅是服务、节点的配置信息(属于控制面配置),而不是与用户相关的数据。所以存储上不需要考虑数据分片,无需过度设计。
-
功能:增删改查,监听数据变化的机制。协调服务保存了服务的状态信息,若服务有变更或异常,相比控制端定时去轮询检查一个个服务状态,若能快速推送变更事件给控制端,则可提升服务可用性、减少协调服务不必要的性能开销。
-
运维复杂度:可维护性。在分布式系统中往往会遇到硬件 Bug、软件 Bug、人为操作错误导致节点宕机,以及新增、替换节点等运维场景,都需要对协调服务成员进行变更。若能提供 API 实现平滑地变更成员节点信息,就可以大大降低运维复杂度,减少运维成本,同时可避免因人工变更不规范可能导致的服务异常
服务高可用
引入多副本机制
数据一致性
为了解决数据一致性问题,需要引入一个共识算法,确保各节点数据一致性,并可容忍一定节点故障。常见的共识算法有 Paxos、ZAB、Raft 等。etcd 选择了易理解实现的 Raft 算法,它将复杂的一致性问题分解成 Leader 选举、日志同步、安全性三个相对独立的子问题,只要集群一半以上节点存活就可提供服务,具备良好的可用性。
存储引擎
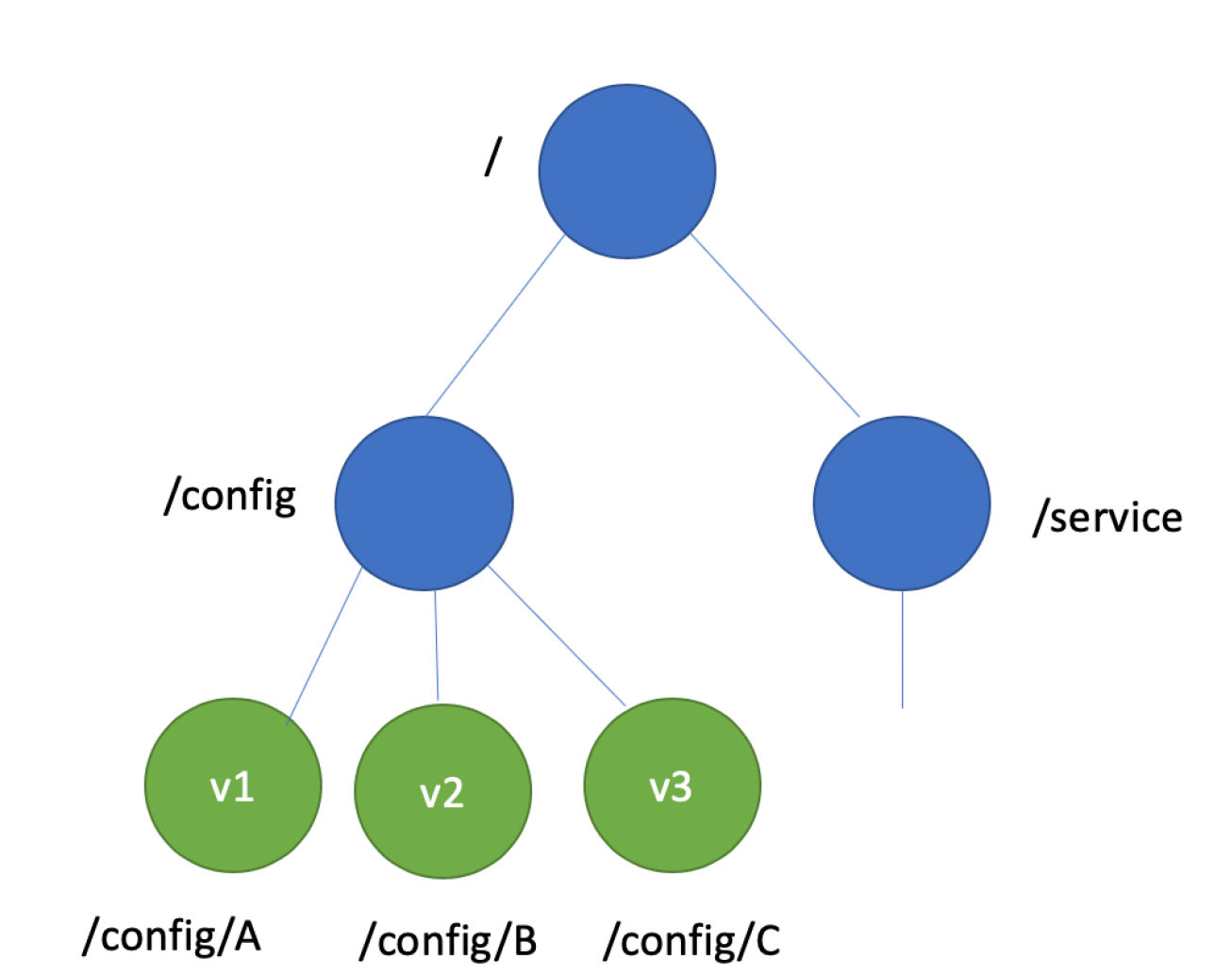
key-value 存储引擎上,ZooKeeper 使用的是 Concurrent HashMap,而 etcd 使用的则是简单内存树,它的节点数据结构精简后如下,含节点路径、值、孩子节点信息。这是一个典型的低容量设计,数据全放在内存,无需考虑数据分片,只能保存 key 的最新版本,简单易实现。
1
2
3
4
5
6
7
type node struct {
Path string //节点路径
Parent *node //关联父亲节点
Value string //key的value值
ExpireTime time.Time //过期时间
Children map[string]*node //此节点的孩子节点
}
方案选型
对于协调服务的选择,有很多,例如百度的disconf、阿里的diamond、点评开源的lion、携程开源的apollo等,也可以使用etcd、consul。
对于 Zookeeper、Etcd 这样强一致性组件,数据只要写到主节点,内部会通过状态机将数据复制到其他节点,Zookeeper使用的是Zab协议,etcd使用的是raft协议。
Zookeeper 其提供了 Master 选举、分布式锁、数据的发布和订阅等诸多功能。
Zookeeper
存在问题
- 配置信息变更延迟
- 配置中心惊群效应