broker
Kafka 使用的是 Reactor 模式处理请求。
简单来说,Reactor 模式是事件驱动架构的一种实现方式,特别适合应用于处理多个客户端并发向服务器端发送请求的场景。
从这张图中,我们可以发现,多个客户端会发送请求给到 Reactor。Reactor 有个请求分发线程 Dispatcher,也就是图中的 Acceptor,它会将不同的请求下发到多个工作线程中处理。 在这个架构中,Acceptor 线程只是用于请求分发,不涉及具体的逻辑处理,非常得轻量级,因此有很高的吞吐量表现。而这些工作线程可以根据实际业务处理需要任意增减,从而动态调节系统负载能力。
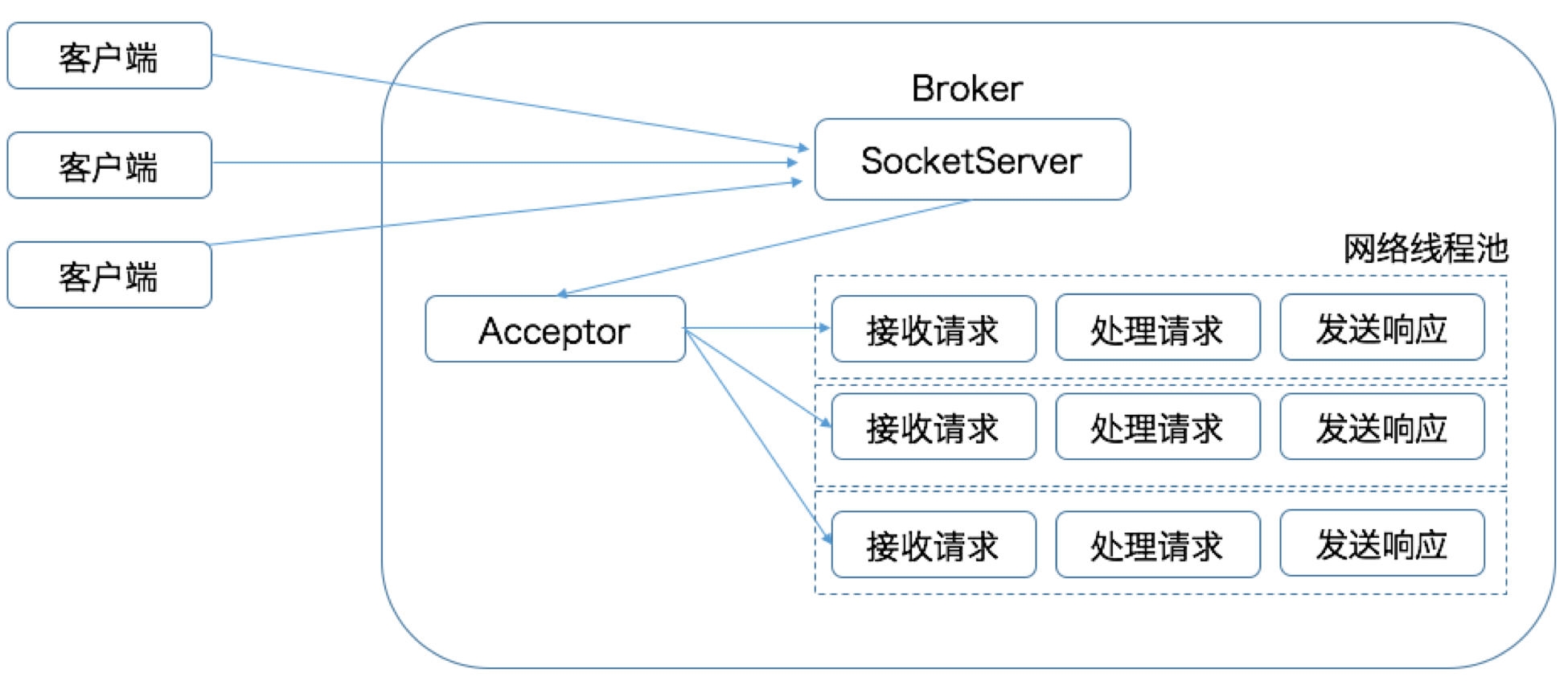 Kafka 的 Broker 端有个 SocketServer 组件,类似于 Reactor 模式中的 Dispatcher,它也有对应的 Acceptor 线程和一个工作线程池,只不过在 Kafka 中,这个工作线程池有个专属的名字,叫网络线程池。Kafka 提供了 Broker 端参数
Kafka 的 Broker 端有个 SocketServer 组件,类似于 Reactor 模式中的 Dispatcher,它也有对应的 Acceptor 线程和一个工作线程池,只不过在 Kafka 中,这个工作线程池有个专属的名字,叫网络线程池。Kafka 提供了 Broker 端参数 num.network.threads,用于调整该网络线程池的线程数。其默认值是 3,表示每台 Broker 启动时会创建 3 个网络线程,专门处理客户端发送的请求。
Acceptor 线程采用轮询的方式将入站请求公平地发到所有网络线程中,因此,在实际使用过程中,这些线程通常都有相同的几率被分配到待处理请求。这种轮询策略编写简单,同时也避免了请求处理的倾斜,有利于实现较为公平的请求处理调度。
协议
Kafka 自定义了一组基于 TCP 的二进制协议,只要遵守这组协议的格式,就可以向 Kafka 发送消息,也可以从 Kafka 中拉取消息,或者做一些其他的事情,比如提交消费位移等。
consumer
KafkaConsumer 是单线程的设计,严格来说这是不准确的。因为,从 Kafka 0.10.1.0 版本开始,KafkaConsumer 就变为了双线程的设计,即用户主线程和心跳线程。
所谓用户主线程,就是启动 Consumer 应用程序 main 方法的那个线程,而新引入的心跳线程(Heartbeat Thread)只负责定期给对应的 Broker 机器发送心跳请求,以标识消费者应用的存活性(liveness)。引入这个心跳线程还有一个目的,那就是期望它能将心跳频率与主线程调用 KafkaConsumer.poll 方法的频率分开,从而解耦真实的消息处理逻辑与消费者组成员存活性管理。
虽然有心跳线程,但实际的消息获取逻辑依然是在用户主线程中完成的。因此,在消费消息的这个层面上,我们依然可以安全地认为 KafkaConsumer 是单线程的设计。
controller
在 Kafka 0.11 版本之前,控制器采用多线程的设计,这些线程还会访问共享的控制器缓存数据,多线程访问共享可变数据是维持线程安全最大的难题。为了保护数据安全性,控制器不得不在代码中大量使用ReentrantLock 同步机制,这就进一步拖慢了整个控制器的处理速度。
鉴于这些原因,社区于 0.11 版本重构了控制器的底层设计,最大的改进就是,把多线程的方案改成了单线程加事件队列的方案。我直接使用社区的一张图来说明。
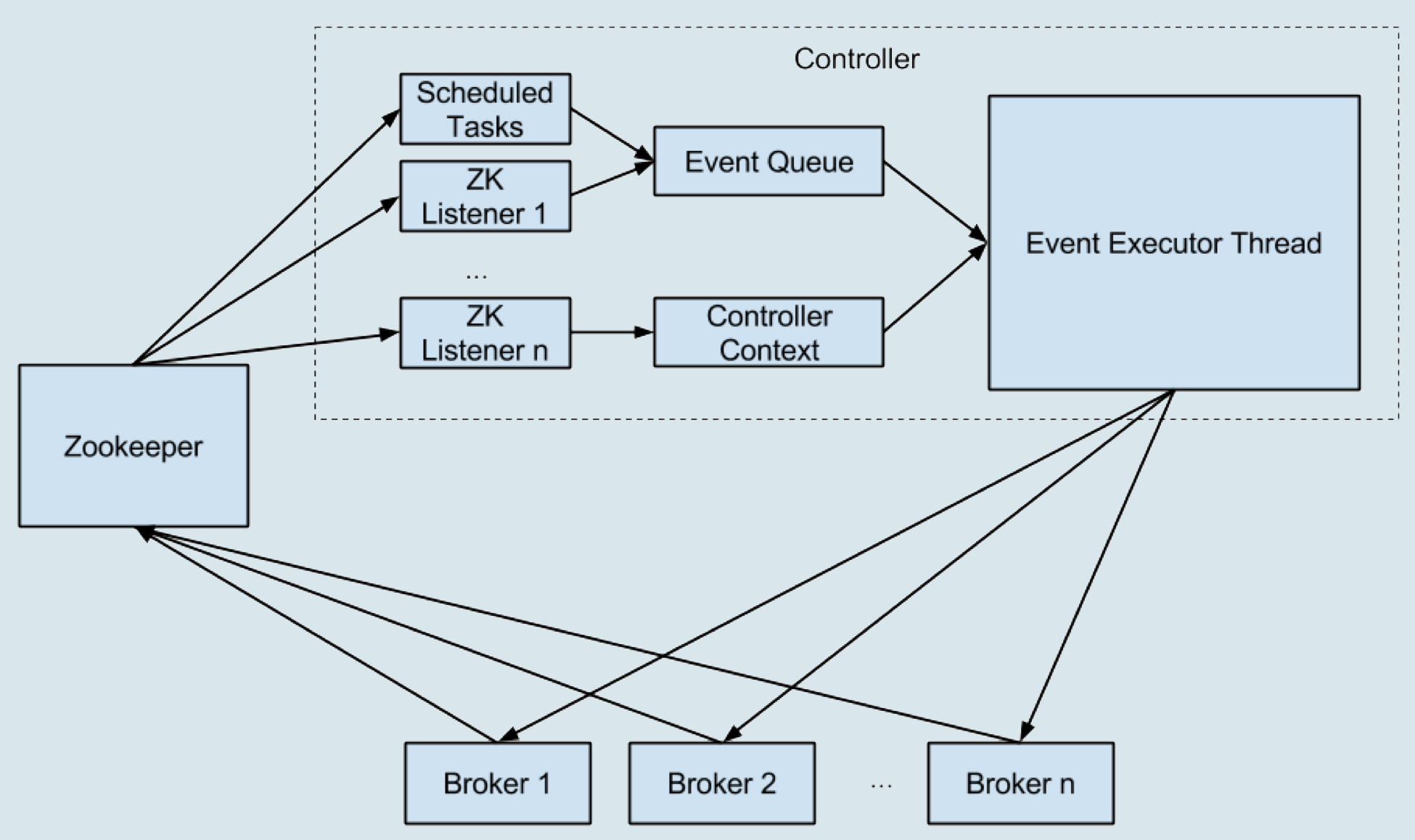
从这张图中,我们可以看到,社区引入了一个事件处理线程,统一处理各种控制器事件,然后控制器将原来执行的操作全部建模成一个个独立的事件,发送到专属的事件队列中,供此线程消费。这就是所谓的单线程 + 队列的实现方式。
值得注意的是,这里的单线程不代表之前提到的所有线程都被“干掉”了,控制器只是把缓存状态变更方面的工作委托给了这个线程而已。
这个方案的最大好处在于,控制器缓存中保存的状态只被一个线程处理,因此不再需要重量级的线程同步机制来维护线程安全,Kafka 不用再担心多线程并发访问的问题,非常利于社区定位和诊断控制器的各种问题。事实上,自 0.11 版本重构控制器代码后,社区关于控制器方面的 Bug 明显少多了,这也说明了这种方案是有效的。