LRU 是⼀种缓存淘汰策略。LRU 的全称是 Least Recently Used,也就是说认为最近使⽤过的数据应该是是「有⽤的」,很久都没⽤过的数据应该是⽆⽤的,内存满了就优先删那些很久没⽤过的数据。
实现
LRU 算法实际上是设计数据结构:⾸先要接收⼀个 capacity 参数作为
缓存的最⼤容量,然后实现两个 API,⼀个是 put(key, val) ⽅法存⼊键值
对,另⼀个是 get(key) ⽅法获取 key 对应的 val,如果 key 不存在则返回
-1。
注意 get 和 put ⽅法必须都是
O(1)的时间复杂度。
要让 put 和 get ⽅法的时间复杂度为 O(1),可以总结出 cache 这个数据结构必要的条件:查找快,插⼊快,删除快,有顺序之分。
哈希表查找快,但是数据⽆固定顺序;链表有顺序之分,插⼊删除快,但是查找慢。所以结合⼀下,形成⼀ 种新的数据结构:哈希链表。
LRU 缓存算法的核⼼数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构⻓这样:
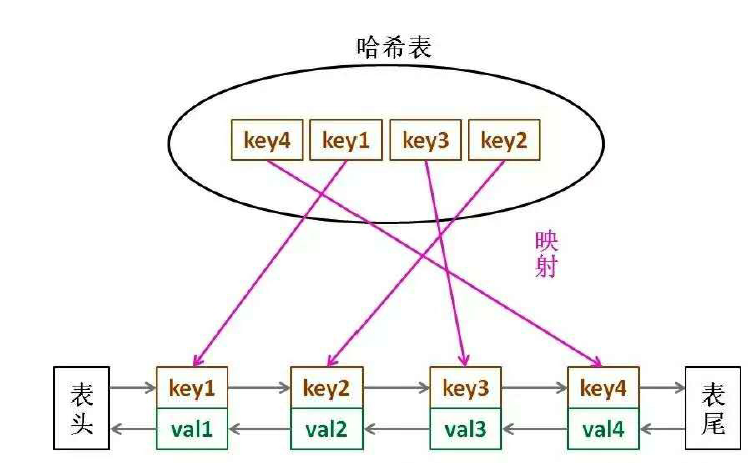
代码
⾸先,我们把双链表的节点类写出来,为了简化,key 和 val 都认为是 int 类型:
1
2
3
4
5
6
7
8
class Node {
public int key, val;
public Node next, prev;
public Node(int k, int v) {
this.key = k;
this.val = v;
}
}
然后依靠 Node 类型构建⼀个双链表,实现⼏个需要的 API(这些操作的时间复杂度均为 O(1)):
1
2
3
4
5
6
7
8
9
10
11
class DoubleList {
// 在链表头部添加节点 x,时间 O(1)
public void addFirst(Node x);
// 删除链表中的 x 节点(x ⼀定存在)
// 由于是双链表且给的是⽬标 Node 节点,时间 O(1)
public void remove(Node x);
// 删除链表中最后⼀个节点,并返回该节点,时间 O(1)
public Node removeLast();
// 返回链表⻓度,时间 O(1)
public int size();
}
URL实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class LRUCache {
// key -> Node(key, val)
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
// 最⼤容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
public int get(int key) {
if (!map.containsKey(key))
return -1;
int val = map.get(key).val;
// 利⽤ put ⽅法把该数据提前
put(key, val);
return val;
}
public void put(int key, int val) {
// 先把新节点 x 做出来
Node x = new Node(key, val);
if (map.containsKey(key)) {
// 删除旧的节点,新的插到头部
cache.remove(map.get(key));
cache.addFirst(x);
// 更新 map 中对应的数据
map.put(key, x);
} else {
if (cap == cache.size()) {
// 删除链表最后⼀个数据
Node last = cache.removeLast();
map.remove(last.key);
}
// 直接添加到头部
cache.addFirst(x);
map.put(key, x);
}
}
}