Redo 初衷是用于性能提升和崩溃恢复;
为了提供更好的读写性能,InnoDB在从磁盘读到page之后,会把page缓存在Buffer Pool中,在经过写入修改之后,这个page就变成了脏页。为了避免每次都把脏页落盘带来的海量随机写的IO开销,InnoDB是在后台异步的将脏页落盘,这时如果进程或机器崩溃导致内存数据丢失,磁盘上的数据和内存中的会存在不一致。为了保证数据库本身的一致性和持久性,InnoDB维护了RedoLog,RedoLog是追加写的模式,任何对Page的修改都需要先将变更记录到Redo中,并保证RedoLog早于对应的Page落盘,也就是常说的WAL(Write Ahead Log)。
当发生故障导致内存数据丢失后,InnoDB会在重启时重放Redo,将任意Page恢复到崩溃前的状态。
从上面的描述可以看到,RedoLog有以下作用:
- 提升数据库写入效率,把page的随机写,转变成了log的顺序写
- 保证数据库不丢数据,通过回放增量Redo,将page恢复到崩溃前的状态
从重做日志缓冲往磁盘写入时,是按 512 个字节,是按一个扇区的大小进行写入。因为扇区是写入的最小单位,因此可以保证写入必然是成功的。因此在重做日志的写入过程中不需要有二次写。
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,那么总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。
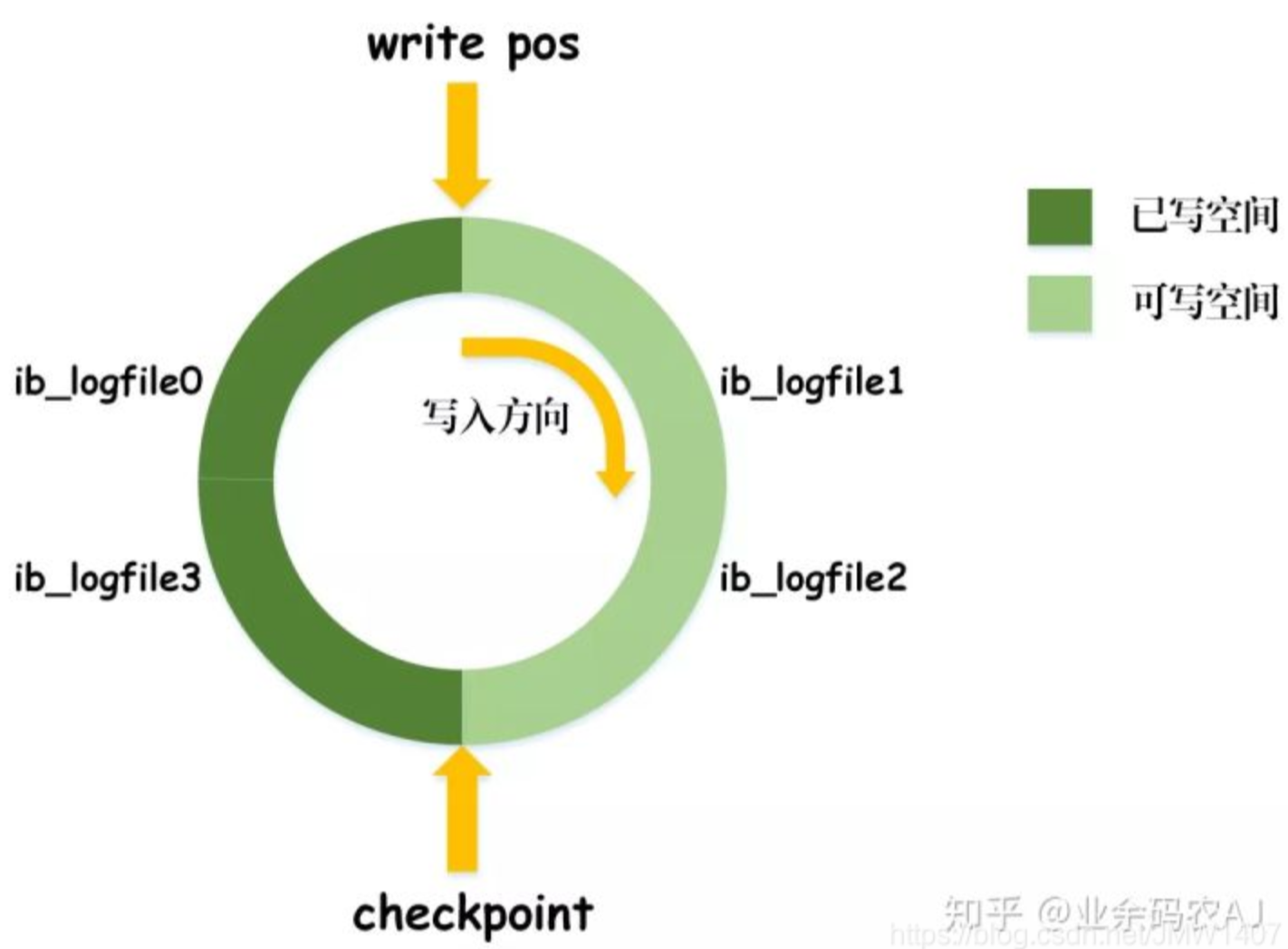
write pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。checkpoint是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos和checkpoint之间的空间是还空着的部分,可以用来记录新的操作。如果write pos追上checkpoint,表示空间满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把checkpoint推进一下。
有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
写入逻辑
redo log 包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的。二是磁盘上的重做日志文件(redo log file),该部分日志是持久的,并且是事务的记录是顺序追加的,性能非常高(磁盘的顺序写性能比内存的写性能差不了太多)。
事务在执行过程中,生成的 redo log 是要先写到 redo log buffer 的。
如果事务执行期间 MySQL 发生异常重启,那这部分日志就丢了。由于事务并没有提交,所以这时日志丢了也不会有损失。
redo log 可能存在三种状态,对应的就是下图中的三个颜色块。
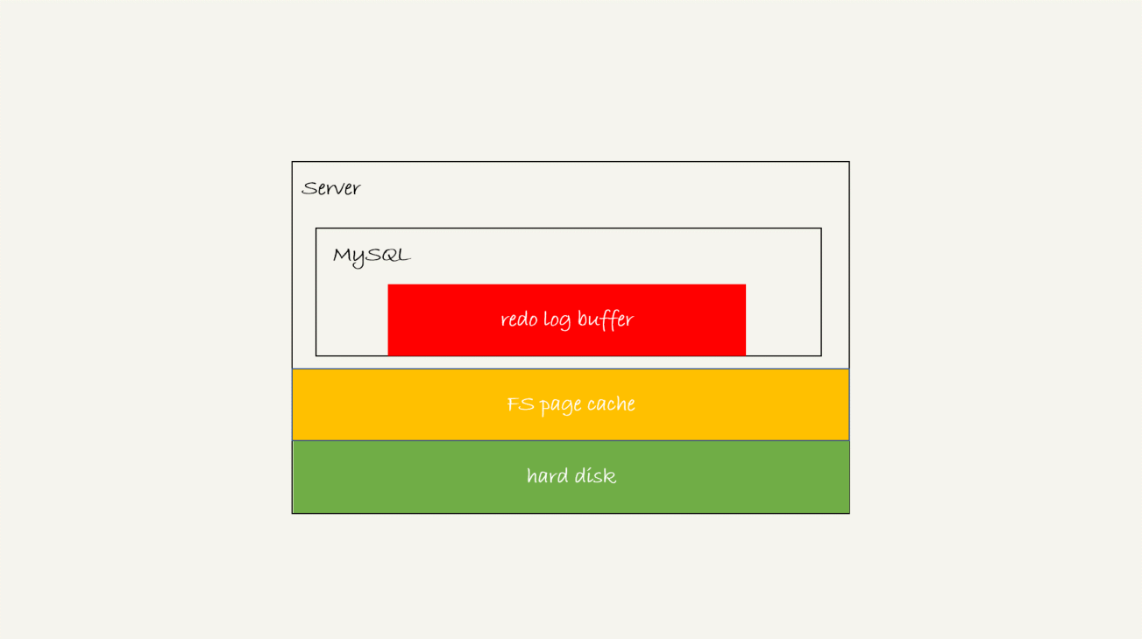
这三种状态分别是:
- 存在 redo log buffer 中,物理上是在 MySQL 进程内存中,就是图中的红色部分;
- 写到磁盘(write),但是没有持久化(fsync),物理上是在文件系统的 page cache 里面,也就是图中的黄色部分;
- 持久化到磁盘,对应的是 hard disk,也就是图中的绿色部分。
为了控制 redo log 的写入策略,InnoDB 提供了 innodb_flush_log_at_trx_commit 参数,它有三种可能取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中;
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
注意,事务执行中间过程的redo log也是直接写在redo log buffer中的,这些redo log也会被后台线程一起持久化到磁盘。也就是说,一个没有提交的事务的redo log,也是可能已经持久化到磁盘的。
实际上,除了后台线程每秒一次的轮询操作外,还有两种场景会让一个没有提交的事务的redo log写入到磁盘中:
- 一种是,redo log buffer 占用的空间即将达到
innodb_log_buffer_size一半的时候,后台线程会主动写盘。注意,由于这个事务并没有提交,所以这个写盘动作只是 write,而没有调用 fsync,也就是只留在了文件系统的 page cache。 - 另一种是,并行的事务提交的时候,顺带将这个事务的 redo log buffer 持久化到磁盘。假设一个事务A执行到一半,已经写了一些redo log到buffer中,这时候有另外一个线程的事务B提交,如果
innodb_flush_log_at_trx_commit设置的是 1,那么按照这个参数的逻辑,事务 B 要把 redo log buffer 里的日志全部持久化到磁盘。这时候,就会带上事务A在redo log buffer里的日志一起持久化到磁盘。
由两阶段提交可知,时序上redo log先prepare, 再写binlog,最后再把redo log commit。
如果把 innodb_flush_log_at_trx_commit 设置成 1,那么 redo log 在 prepare 阶段就要持久化一次,因为崩溃恢复逻辑是要依赖于 prepare 的 redo log,再加上 binlog 来恢复的。
每秒一次后台轮询刷盘,再加上崩溃恢复这个逻辑,InnoDB就认为redo log在commit的时候就不需要fsync了,只会write到文件系统的page cache中就够了。
MySQL的“双1”配置,指的就是sync_binlog和innodb_flush_log_at_trx_commit都设置成 1。也就是说,一个事务完整提交前,需要等待两次刷盘,一次是redo log(prepare 阶段),一次是binlog。
检查点(checkpoint)
数据经过更新或者删除之后,数据页变为脏页,需要刷回磁盘,在事务提交时,先写 redo log,再修改页,再在合适的时机刷回磁盘。这样即使宕机,也可以通过 redo log 来恢复数据。InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写。检查点表示脏页写入到磁盘的时候,所以检查点也就意味着脏数据的写入,其目的是:
- 缩短数据库恢复时间,将脏页刷新到磁盘
- 缓冲池不够用时,将脏页刷新到磁盘
- redo log 写满了,将脏页刷新到磁盘。要避免这种情况,因为此时整个系统就不能再接受更新了,所有的更新都必须停止。
- 正常关闭 数据库实例时,将脏页刷新到磁盘
检查点分为两种:
- sharp checkpoint:完全检查点,数据库正常关闭时,会触发把所有的脏页都写入到磁盘上。
- fuzzy checkpoint:模糊检查点,部分页写入磁盘。发生在数据库正常运行期间。主线程在空闲时会周期性执行,或者在空闲页不足,或者redo log文件快满时会执行模糊检查点。
Redo日志的格式和类型
- 作用于 Page 的 Redo
大部分的用户操作都是此类,比如
MLOG_REC_INSERT、MLOG_REC_UPDATE_IN_PLACE、MLOG_REC_DELETE三种类型分别对应于Page中记录的插入、修改以及删除。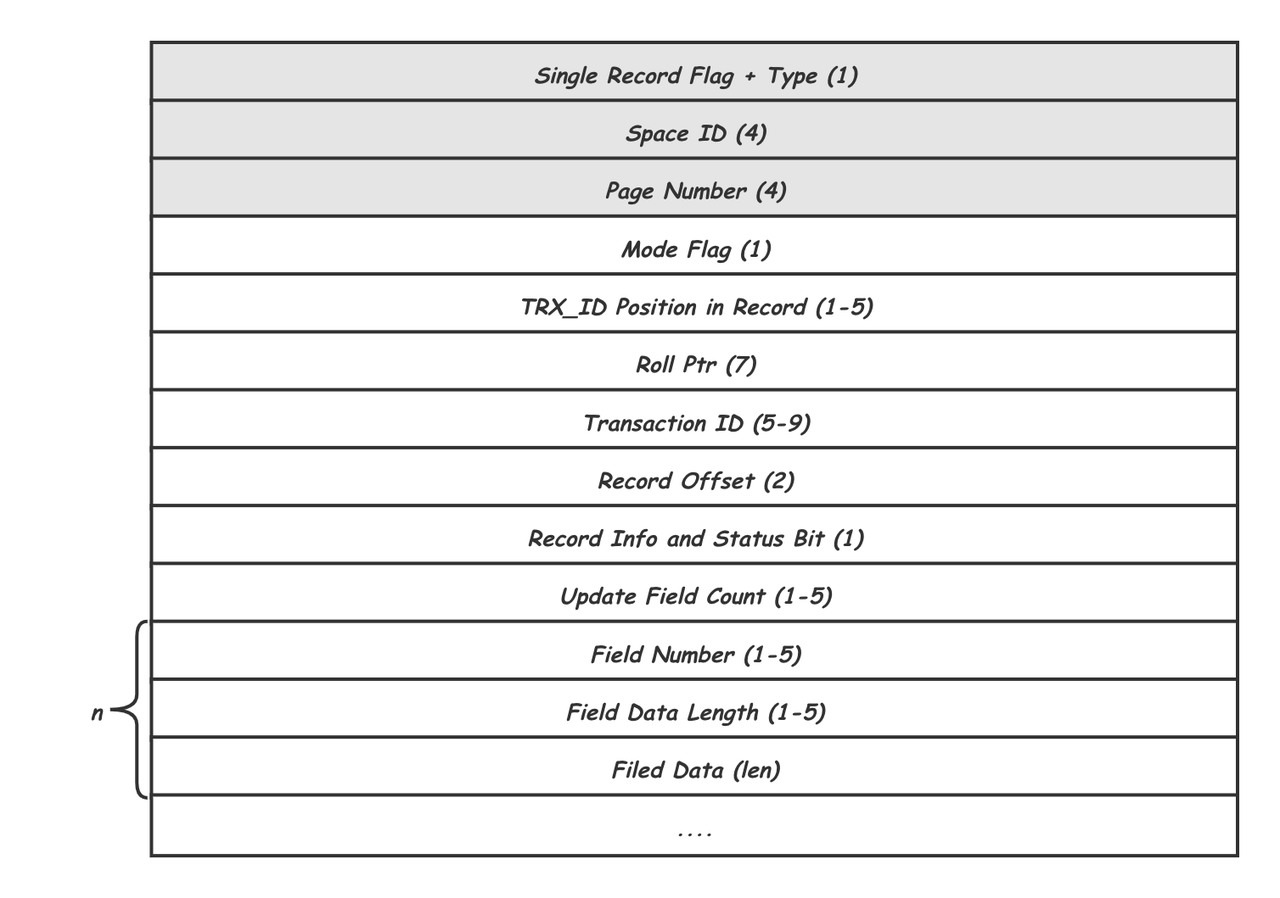 上图以
上图以MLOG_REC_UPDATE_IN_PLACE为例,Type就是MLOG_REC_UPDATE_IN_PLACE类型,Space ID和Page Number唯一标识一个Page页,这三项是所有REDO记录都需要有的头信息。后面的是MLOG_REC_UPDATE_IN_PLACE类型独有的,其中Record Offset用给出要修改的记录在Page中的位置偏移,Update Field Count说明记录里有几个Field要修改,紧接着对每个Field给出了Field编号(Field Number),数据长度(Field Data Length)以及数据(Filed Data) - 作用于 Space 的 Redo
这类REDO针对一个Space文件的修改,如
MLOG_FILE_CREATE,MLOG_FILE_DELETE,MLOG_FILE_RENAME分别对应对一个Space的创建,删除以及重命名。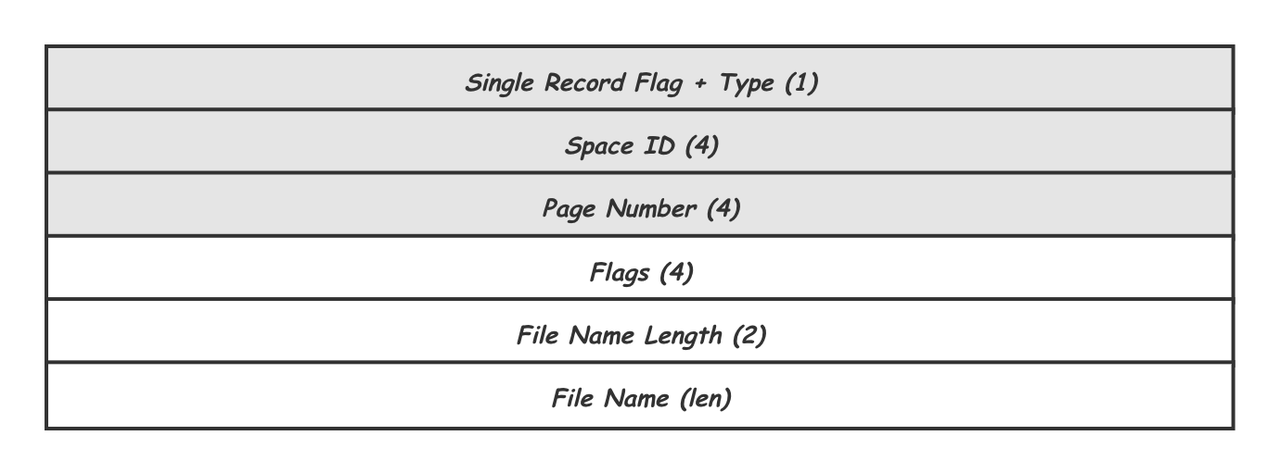 上图以MLOG_FILE_CREATE为例,前三个字段还是Type,Space ID和Page Number,由于是针对Space的操作,这里的Page Number永远是0。在此之后记录了创建的文件flag以及文件名,用作重启恢复时的检查。
上图以MLOG_FILE_CREATE为例,前三个字段还是Type,Space ID和Page Number,由于是针对Space的操作,这里的Page Number永远是0。在此之后记录了创建的文件flag以及文件名,用作重启恢复时的检查。 - 提供额外信息的 Logic Redo
比如
MLOG_SINGLE_REC_FLAG,MLOG_MULTI_REC_END,MLOG_INDEX_LOAD。
在这些基础的格式之上,MySQL通过不同的层次,把redo记录组织起来。
Redo的组织形式:
-
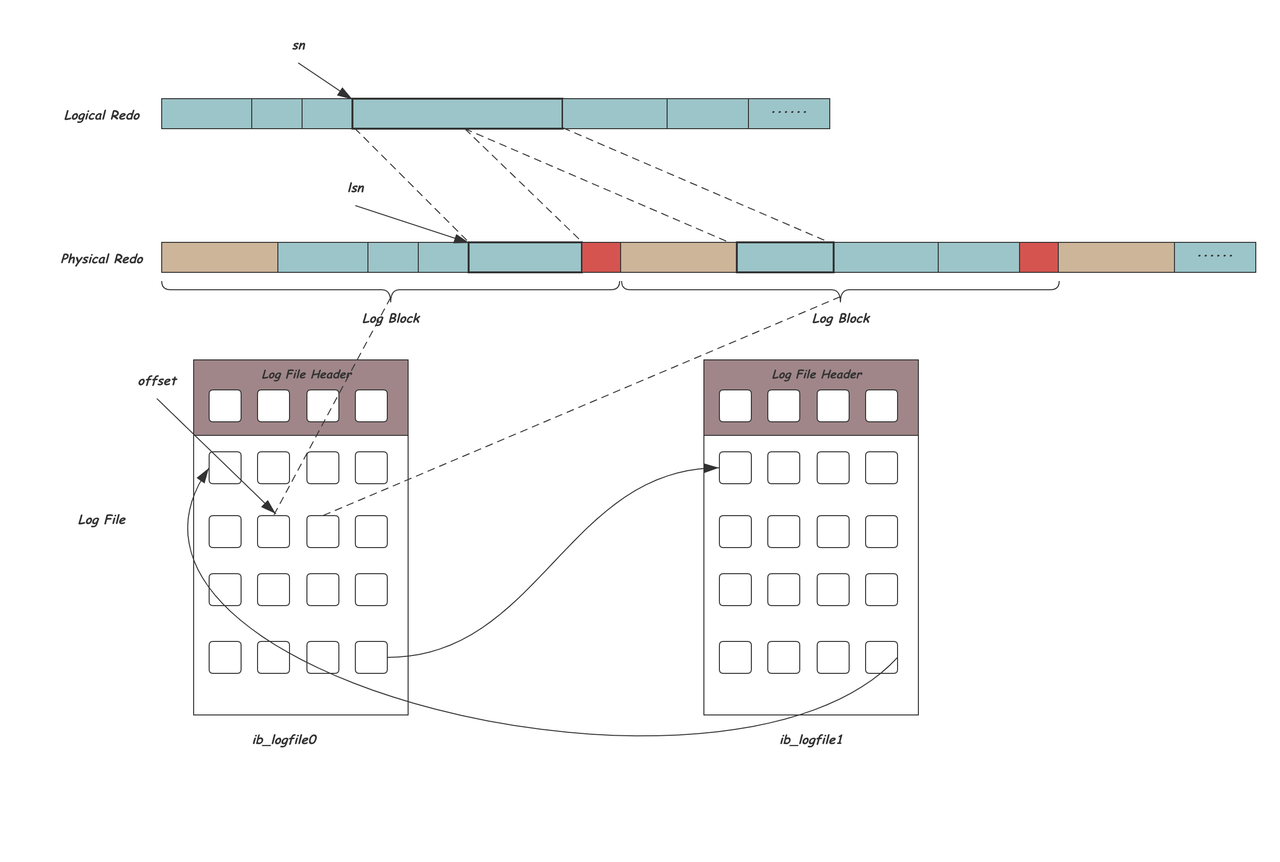
逻辑Redo层 真正的Redo内容,由多个不同Type的多个Redo记录首尾相连组成,有全局唯一的递增的偏移sn,InnoDB会在全局log_sys中维护当前sn的最大值,并在每次写入数据时将sn增加Redo内容长度

- 物理Redo层
InnoDB中用Block的概念来读写数据,一个Block的长度OS_FILE_LOG_BLOCK_SIZE等于磁盘扇区的大小512B,每次IO读写的最小单位都是一个Block。除了Redo数据以外,Block中还需要一些额外的信息。

- 文件层 Redo最终会被写入到Redo日志文件中,以ib_logfile0、ib_logfile1…命名,为了避免创建文件及初始化空间带来的开销,InooDB的Redo文件会循环使用,通过参数innodb_log_files_in_group可以指定Redo文件的个数。多个文件首尾相连顺序写入Redo内容。
整体的结构可以描述为:逻辑REDO是真正需要的数据,用sn索引,逻辑REDO按固定大小的Block组织,并添加Block的头尾信息形成物理REDO,以lsn索引,这些Block又会放到循环使用的ib_logfile中的某一位置,文件中用offset索引。