大多数存储系统,为了能做到快速查找,都会采用树或者哈希表这样的存储结构,数据在写入的时候,必须写入到特定的位置上。比如说,我们在往 B+ 树中写入一条数据,必须按照 B+ 树的排序方式,写入到某个固定的节点下面。哈希表也是类似,必须要写入到特定的哈希槽中去。
在关系型数据库中,通常使用 B+ 树作为索引。B+ 树的数据都存储在叶子节点中,而叶子节点一般都存储在磁盘中。对 B-Tree 类型的数据结构进行更新操作时,除了查找 node 所需的时间外,还可能涉及到 node 的 merge、spilt、上下层移动等操作,这些操作通常都是 Random I/O。同时,这类更新操作都是是即时发生(in-place)的,即当场发生,当场完成,旧数据会被直接替换掉。比如,一个日志系统,每秒钟要写入上千条甚至上万条数据,这样的磁盘操作代价会使得系统性能急剧下降,甚至无法使用。
顺序IO VS 随机IO:
- B树/B+树的优点在于提供快速点查的效率前提下,同时具有良好的范围查询性能,但是会有随机I/O的问题;
- LSM Tree提升写性能的关键点在于将所有的写操作都变成顺序写,避免随机IO;
顺序IO的弊端:
- 首先需要解决查询的问题,因为是顺序写,所以数据不是有序存储的,对查询不友好;
- 其次是空间浪费的问题,如果对一个key多次修改,那么会产生很多无用的冗余数据;
基于日志的存储结构(Log-Structed)
无序的日志结构
通常做法是日志分解成一定大小的段,当文件达到一定大小时就关闭它,并将后续写入到新的段文件中。可以在日志段上执行压缩。压缩意味着在日志中丢弃重复的键,并且只保留每个键最近的更新。
优点:
- 当进行数据写入时,只需要顺序追加写入即可,不会涉及乱序写入,写性能优势明显;在传统磁盘,顺序IO的性能比乱序IO高了几个数量级,在SSD中顺序IO仍然有优势。
- 合并旧段可以避免随着时间的推移数据文件出现碎片化的问题。
这类存储结构面临的问题:
- 记录切分:文件中的数据记录是以换行符(\n) 切分符的,当 key/value 中包含换行符有问题了,而 “,” 作为key和value的切分符 同样面临这样的问题。解决方案主要有三种:
- 字符转义:将Key/Value的 “,” “\n” 进行转义后再存入,比如转为 “\,” “\n”,取的时候再转回去。
- 定长结构:规定Key/Value特定的长度(比如都是100字节),这显然不符合一般数据库的场景。
- 长度标识边界:记录Key/Value的长度,使用长度判断边界而非切分符。这个是业界的主流。
- 查询性能:不难发现,极端的情况下,脚本需要扫描全部记录 才能找到key对应的记录,时间复杂度为O(N);所以我们要加入索引,以提高寻找定位记录的速度。
- 数据冗余、存储量被放大:因为不会原地更新,追加式的方式必然会来带数据的冗余,比如上面的 “k1,v1”就是一个冗余数据。解决的方案是定期进行压缩,删除部分旧的冗余数据。
基于长度的记录切分
当使用4个字节存储Key或Value的长度时,文件中的存储结构大概长这样:
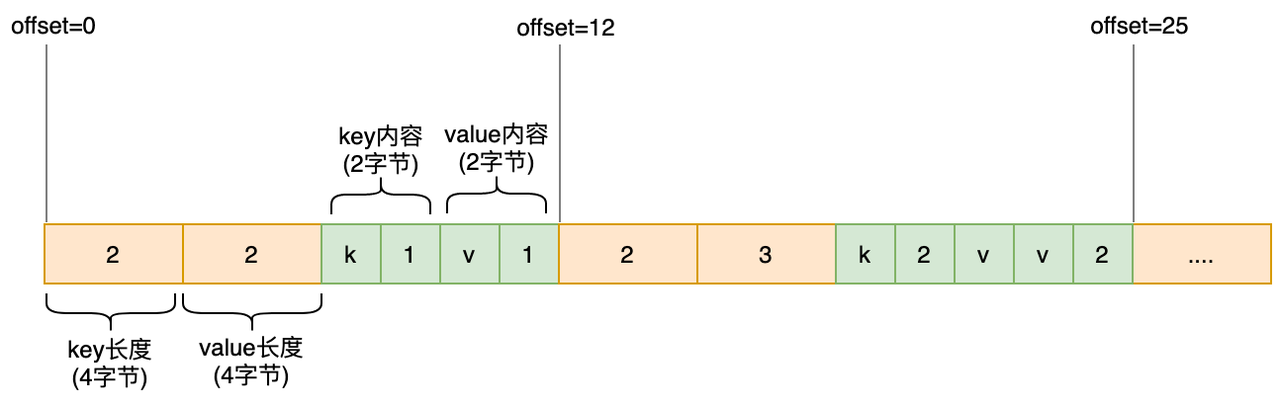 记录Key/Value长度的那部分通常被称之为Header,记录内容为Body。工程实现上,为了记录更多的元信息,Header内容会更加丰富:比如记录写入时间等。
记录Key/Value长度的那部分通常被称之为Header,记录内容为Body。工程实现上,为了记录更多的元信息,Header内容会更加丰富:比如记录写入时间等。
Hash索引
可以在内存中构造一个Hash索引表(每个段对应一个索引表),记录Key对应的每条记录的偏移值,即可实现索引:
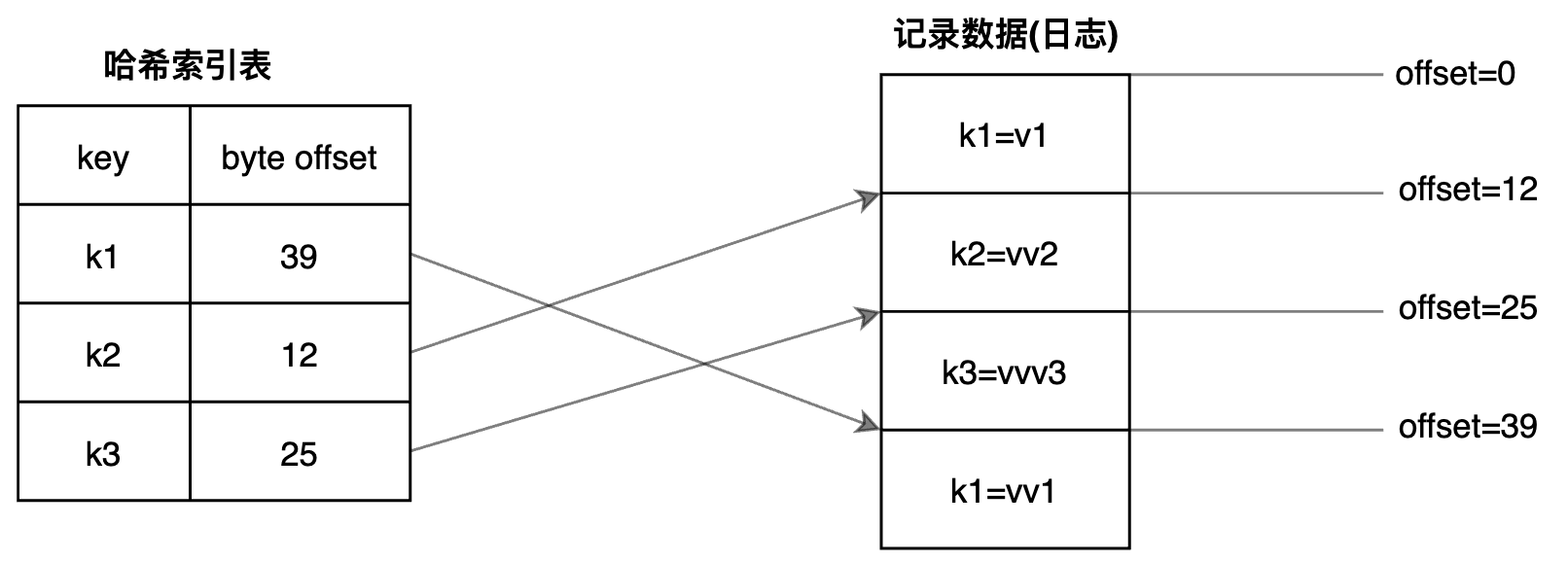
通常而言会记录将整个Hash索引表都放入内存;当更新数据时,会同时更新索引。
崩溃恢复: 当数据库需要重启时,可以重新扫描整个段文件重构索引表;不过分段文件很大时,花费的时间就比较长了。 可以考虑定时(比如每隔30秒)持久化这个索引表,除了表本身数据,可能还要带上一个最新的偏移值,发生宕机时,加载索引文件+从该偏移值扫描余下的数据记录补充索引即可。
数据压缩:
当只有单个数据文件,压缩时只要找出冗余的数据删掉即可:
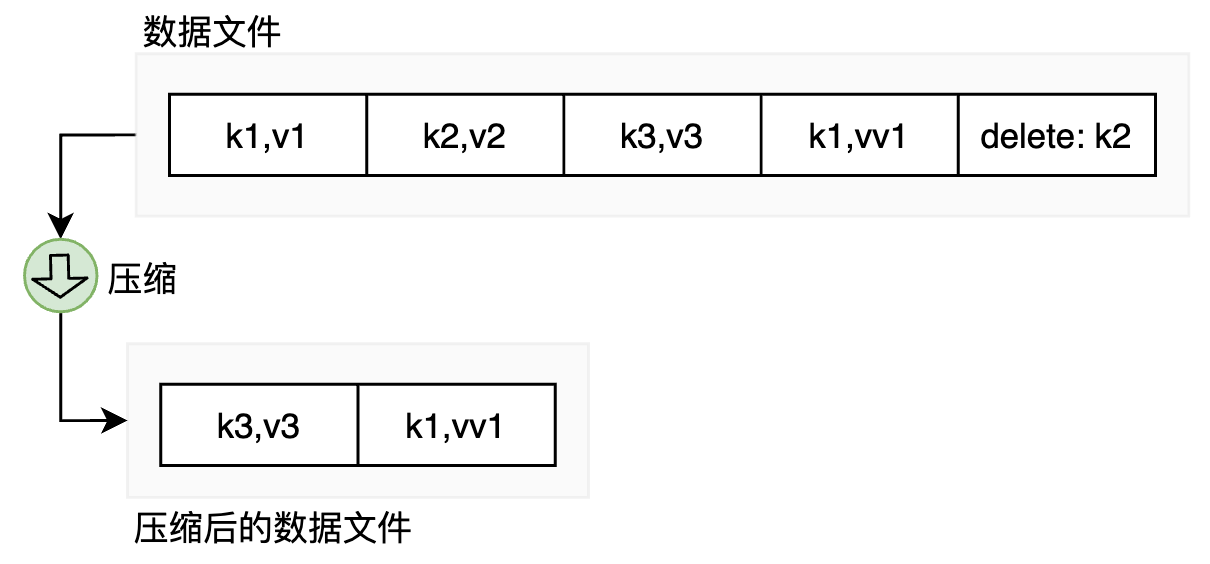 单个文件过大并不好管理,且合并时需要扫描一个超大的文件。我们可以考虑将日志拆分为一定大小的段(文件):当前文件大小达到一定程度时,再新起一个,后续内容都写到新文件中。
单个文件过大并不好管理,且合并时需要扫描一个超大的文件。我们可以考虑将日志拆分为一定大小的段(文件):当前文件大小达到一定程度时,再新起一个,后续内容都写到新文件中。
当进行压缩时,可以选择其中若干个文件进行合并压缩:
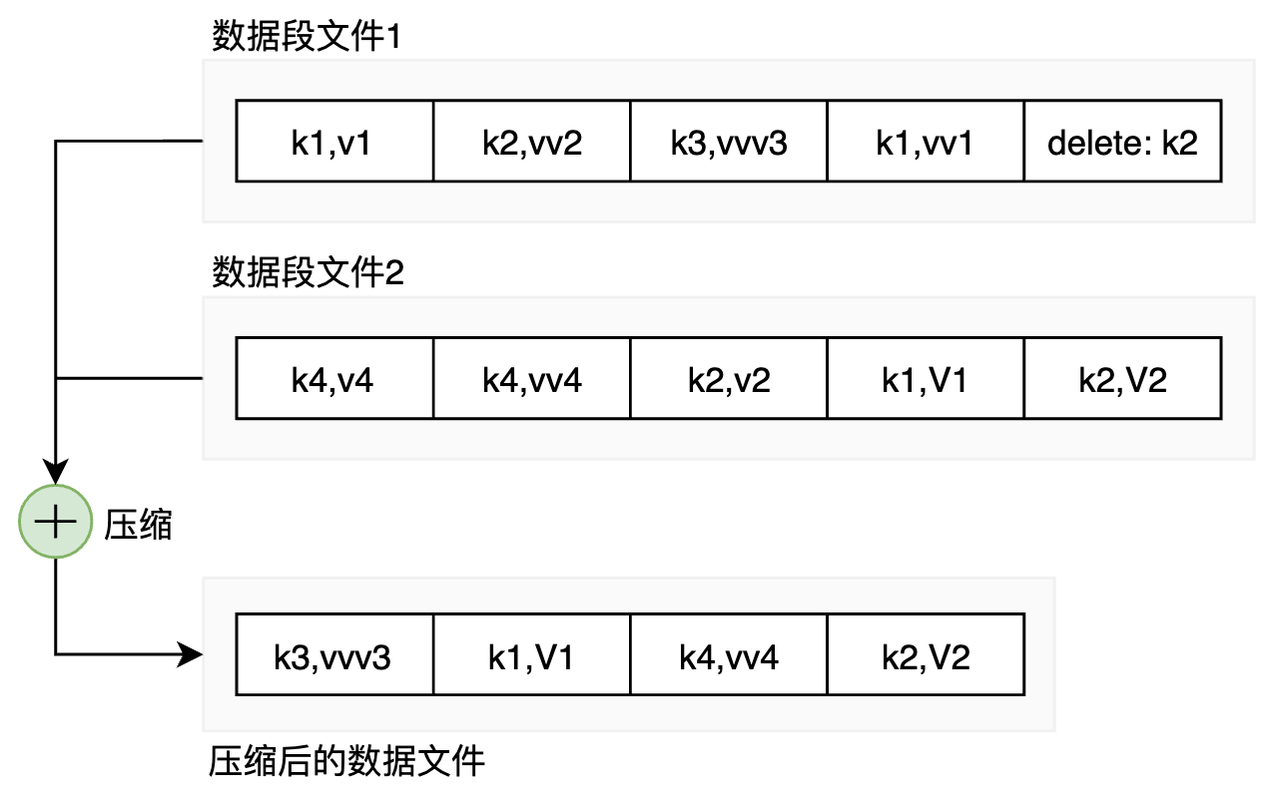
每个段都有自己的内存哈希表,将键映射到文件的偏移量。为了找到键的值,首先检查最新的段的hash map。如果键不存在,检查第二最新的段,以此类推。、
对于这些冻结段的合井和压缩过程可以在后台线程中完成,而且运行时,仍然可以用旧的段文件继续正常读取和写请求。当合并过程完成后,将读取请求切换到新的合并段上,而旧的段文件可以安全删除。
删除记录: 如果要删除键和它关联的值,则必须在数据文件中追加一个特殊的删除记录。
并发控制: 由于写入以严格的先后顺序追加到日志中,通常的实现选择是只有一个写线程。数据文件段是追加的, 并且是不可变的, 所以他们可以被多个线程同时读取。
有序的日志结构-SSTable
考虑下压缩的具体实现,一个简单的方法是将所有数据加载到内存,然后根据写入先后顺序,确定保留哪些记录;当内存装不下文件内容时,处理起来效率可能就比较低了。
假设每个段文件中的记录都是有序的话,我们就可以使用归并排序中的归并思路,每个段文件只需要加载前面的部分记录到内存,进行合并输出到新的有序文件中就行了:
 排序字符串表SSTable(Sorted Strings Table)就是这样的格式:它要求 段文件中的记录都按照Key进行排序,且每个Key只能出现一次。
排序字符串表SSTable(Sorted Strings Table)就是这样的格式:它要求 段文件中的记录都按照Key进行排序,且每个Key只能出现一次。
稀疏的Hash索引:
相对于一个索引对应一个数据记录,稀疏索引则是一个索引对应多个数据记录。
因为日志中的数据是有序的,我们可以在单个文件中再划分一个维度-数据块,每个块中包含若干个数据记录,这时可以建立Hash索引:一个索引对应一个数据块:
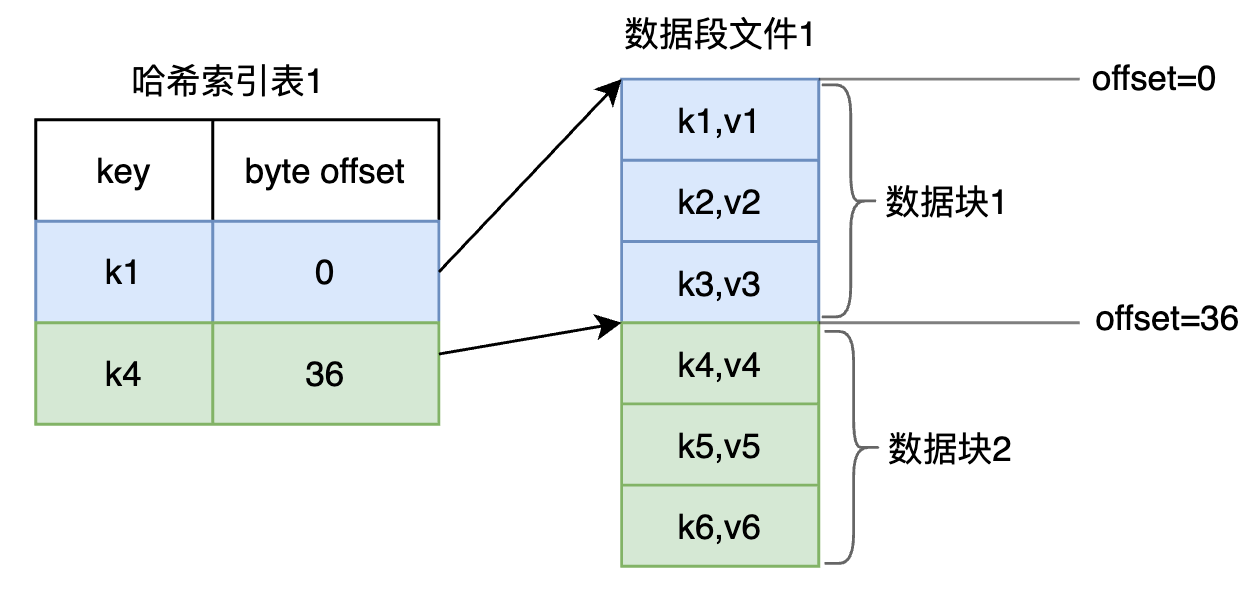 当查找K2时,可以先定位到K1和K4,然后扫描这两者之间(0~36)的记录即可。
当查找K2时,可以先定位到K1和K4,然后扫描这两者之间(0~36)的记录即可。
和传统的Hash索引相比,稀疏索引占用的体积更小,对于范围查询也更加有优势;不过对于单个记录查询,传统的Hash索引仍然占优(一次定位就完成了)。
构建和维护SSTable: 因为要保证有序性,出于性能的考量,SSTable并不直接操作磁盘,而是先在内存中维护一份有序数据(红黑树/Skip List),当内存中的数据大小达到阈值时(比如5MB),再一次性写入磁盘。这个内存中的数据有时被称为内存表。
工作流程大概如下:
- 插入/更新/删除时:直接操作内存,追加/更新内存中的记录;
- 为了保证数据持久性,会顺序写入一条行为日志,即预写日志(Write-ahead logging,WAL)
- 当内存中的数据达到一定大小时,将其作为SSTable文件写入磁盘。新创建一个文件进行写入,显然这个文件也是有序的。
- 每间隔一段时间,选择若干个文件进行压缩,合并期间丢弃那些已被覆盖或删除的值。
- 查询时:先查内存中的数据,然后是最新的磁盘文件,再然后是次新文件….最糟糕的情况下,会全部文件查询完成,不过因为索引的存在,这个工作量相对会轻点。
SSTable 优点:
- 提高合并效率
- 降低合并时所需内存
- 支持稀疏的Hash索引,不再需要在内存中保存所有键的索引
- 由于磁盘是顺序写入的,可以支持非常高的写入吞吐量
- 由于数据按排序存储,因此可以有效地执行区间查询
LSM-日志结构合并树(Log-Structured Merge-Tree) 基于保存在系统中的一系列排序字符串表(SSTable),基于合并和压缩排序文件原理的存储引擎通常都被称为LSM存储引擎。算法的基本思想是 内存有一棵树(如红黑树),磁盘中也有一颗树(如B+树),当内存中的树达到一定大小时,再和磁盘中的树进行合并,合并结果一次性批量地刷入磁盘。可以参考:LSM 论文、基于论文的一些解读、合并流程 、LSM的一些磁盘和内存的价值计算
内存排序有很多广为人知的树状数据结构,例如红黑树或AVL树。使用这些数据结构,可以按任意顺序插入键并以排序后的顺序读取它们。
处理查找某个不存在键时低效的处理办法:使用额外的布隆过滤器(布隆过滤器是内存高效的数据结构,用于近似计算集合的内容。如果数据库中不存在某个键,它能够 很快告诉你结果,从而节省了很多对于不存在的键的不必要的磁盘读取)
基于页式的存储结构
页式存储结构可以认为是存储应用的一层抽象,屏蔽底层操作系统内存页/文件系统的大小,统一管理;一页可能包含多条记录,一条记录也有可能由多页组成;
从内存的角度看:存储页 一般由 若干个内存页组成,内存页会遵循操作系统的内存淘汰策略,即热数据会留在内存中,冷数据则有可能会被置换到磁盘。以MySQL InnoDB为例,其中的Buffer Pool就包含了大量的热页,缓存命中率一般会在99.9%以上;
从磁盘的角度看:存储页 通常不会 像日志系统那样可以顺序写入,在主流的B-Tree类索引下,这些存储页的写入基本上都是乱序写入。
每个存储页 都可以使用一个数字(指针)进行标识。
B-tree
B-tree 是最广泛使用的索引结构,是几乎所有关系数据库的标准索引实现。在 B-Tree 索引下,一个树节点通常使用一页进行记录,查询时:
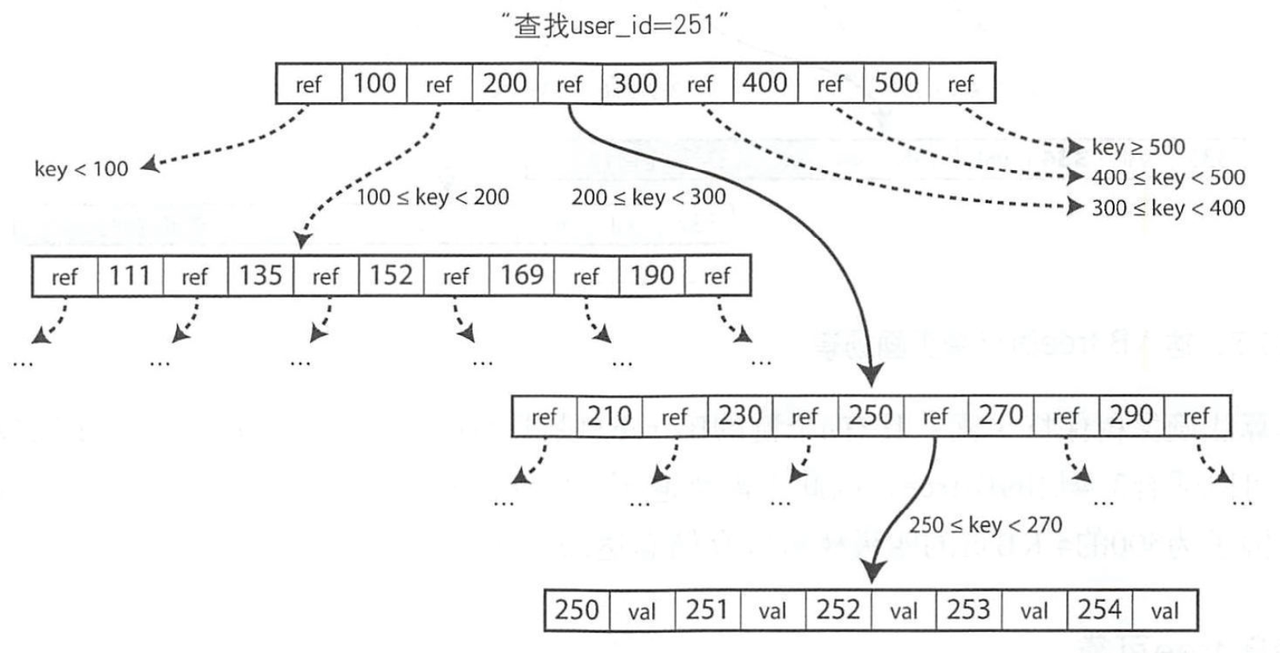
本质上 B-Tree 也可以认为是一个 Key-Val 结构,这里的 Key 为 user_id,Value 即对应的记录;
这里的 B-Tree 的具体实现是B+Tree,好处是:非叶子节点不存储Value数据,只有下一层的指针,一页大小的限制下放入更多的索引数据;从而减少树的高度,提高查询效率;另外因为B+Tree叶子节点会保留下一个叶子节点的指针,也方便了范围查询。
写入时,和 B-Tree 类似,会涉及节点满了进行分裂的过程,因为一页=一节点,即页满了之后进行分裂:
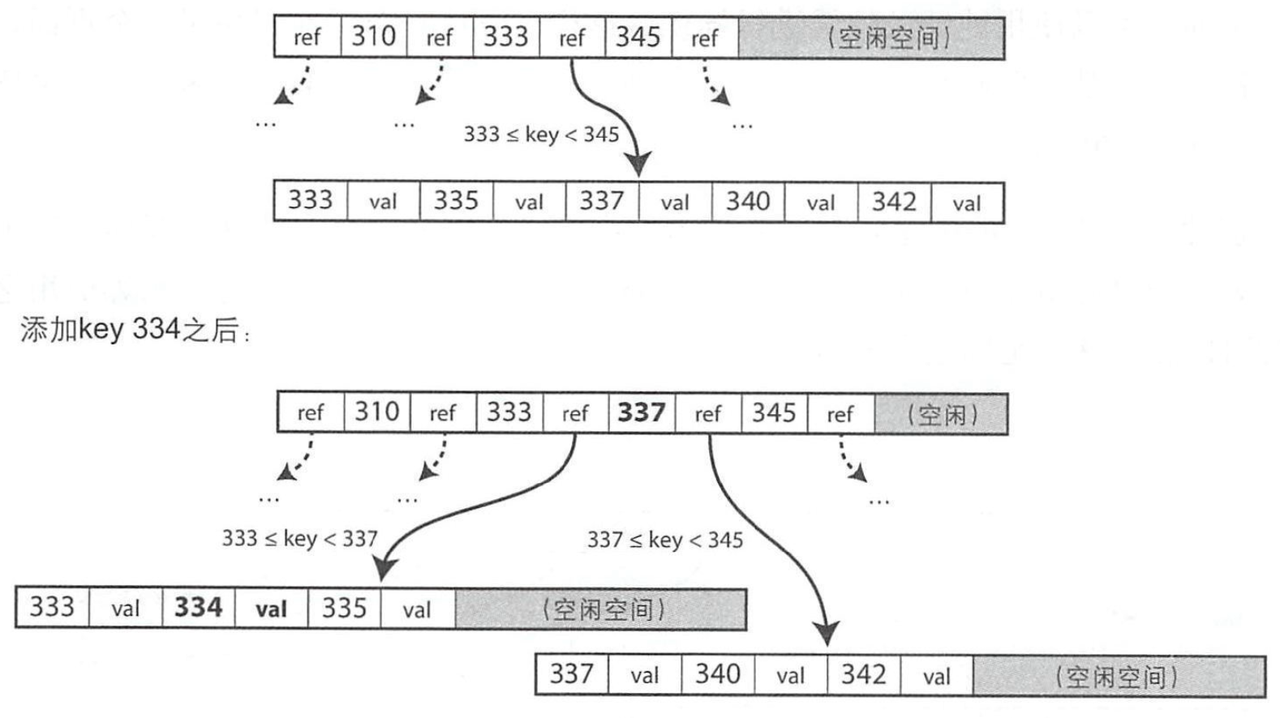 通常页的写入时不会直接刷到磁盘,而是先写到预写日志WAL,页数据会攒着攒着,由后台线程在适当的时机刷入;崩溃时可以通过WAL进行恢复。比如MySQL的Redo Log就记录了数据页的变化。
通常页的写入时不会直接刷到磁盘,而是先写到预写日志WAL,页数据会攒着攒着,由后台线程在适当的时机刷入;崩溃时可以通过WAL进行恢复。比如MySQL的Redo Log就记录了数据页的变化。
预写日志(write-ahead log, WAL),也称为重做日志。这是一个仅支持追加修改的文件,每个B-tree的修改必须先更新WAL然后再修改树本身的页。当数据库在崩愤后需要恢复时,该日志用于将B-tree恢复到最近一致的状态。
无论是数据日志类还是B-Tree类,通常都可以支持多个索引的,比如再构造一颗B-Tree,同样可以使用WAL保证数据的可靠性。
在MySQL InnoDB中,主键索引叶子节点中的value会包含某行的全部数据(聚簇索引),而一般二级索引的叶子节点的value则为 主键的值;在MySQL MyISAM中,数据和索引则是分开的,主键/一般索引的value均是指向数据位置的一个指针。当然,他们的索引都是基于B+树的,只是具体实现不一样。
B-Tree和LSM-Tree
朴素的 LSM-Tree 可以认为是 页式+数据日志的形式,与B-Tree不同的是,它会攒着攒着再一次性顺序写入(注:不仅是WAL日志,其数据也是批量顺序写入的,工程实现LevelDB更有代表性); 而 B-Tree 的页刷盘时,会触发更多的随机 IO;且页中某一条记录发生变化时,也要重写整页,这也是一个损耗,尽管可以攒着攒着再写。
一般认为:因为没有数据冗余/重复键等,B-Tree读性能会更好一些;而LSM则更适合写密集的存储系统,读写/空间放大等问题则需要考量;
- B-tree 索引必须至少写两次数据:一次写入预写日志,-次写入树的页本身。
- 由于反复压缩和SSTable的合井,日志结构索引(LSM-tree)也会重写数据多次
- LSM-tree通常能够承受比B-tree更高的写入吞吐量,部分是因为它们有时具有较低的写放大。部分原因是它们以顺序方式写入紧凑的SSTable文件, 而不必重写树中的多个页。
- LSM-tree可以支持更好地压缩,因此通常磁盘上的文件比B-tree小很多
- 日志结构存储(LSM-tree)的缺点是压缩过程有时会干扰正在进行的读写操作。日志结构化存储引擎(LSM-tree)的查询晌应时间有时会相当高,而B-tree的响应延迟则更具确定 性。
- B-tree的优点则是每个键都恰好唯一对应于索引中的某个位置,而日志结构的存储引擎可能在不同的段中具有相同键的多个副本
- 在许多关系数据库中,事务隔离是通过键范围上的锁来实现的,井且在B-tree索引中,这些锁可以直接定义到树中。
写放大: 在数据库内,由于一次数据库写入请求导致的多次磁盘写