存储引擎主要有两个存储引擎家族,即日志结构的存储引擎和面向页的存储引擎,比如B-tree。分别用于大家比较熟悉的两种数据库,即传统的关系数据库和大多数所谓的 NoSQL 数据库。
存储引擎
存储引擎一般包含如下三大类的选择:
- MySQL 等 SQL 数据库。
- LevelDB 和 RocksDB:基于排序字符串表(SSTable)算法。
- LMDB fn BoltDB
其中MySQL支持ACID事务。但是作为一个关系型数据库, MySQL主要定位于提供高效灵活的SQL查询语句支持,可以支持复杂的联表查询等。
LevelDB和RocksDB分别是Google和Facebook开发的存储引擎,RocksDB是在LevelDB的基础上针对Flash设备做了优化。其底层实现原理都是log-structured merge-tree(LSM tree),基本原理是将有序的key/value存储在不同的文件中,并通过“层级”将它们分开,并且周期性地将小的文件合并为更大的文件,这样做就能把随机写转化为顺序写,从而提高随机写的性能,因此特别适合“写多读少”和“随机写多”的场景。同时需要注意的是,LevelDB和RocksDB都不支持完整的ACID事务。
LMDB和BoltDB是基于B树和mmap的数据库,基本原理是用mmap将磁盘的page映射到内存的page ,而操作系统则是通过COW (copy-on-write)技术进行page管理,通过cow技术,系统可实现无锁的读写并发,但是无法实现无锁的写写并发,这就注定了这类数据库读性能超高,但写性能一般,因此非常适合于“读多写少”的场景。同时BoltDB支持完全可序列化的ACID事务。
Level DB的基本实现
这里以基于LSM思想的Level DB为例,讲述一下LevelDB在工程上的具体实现:
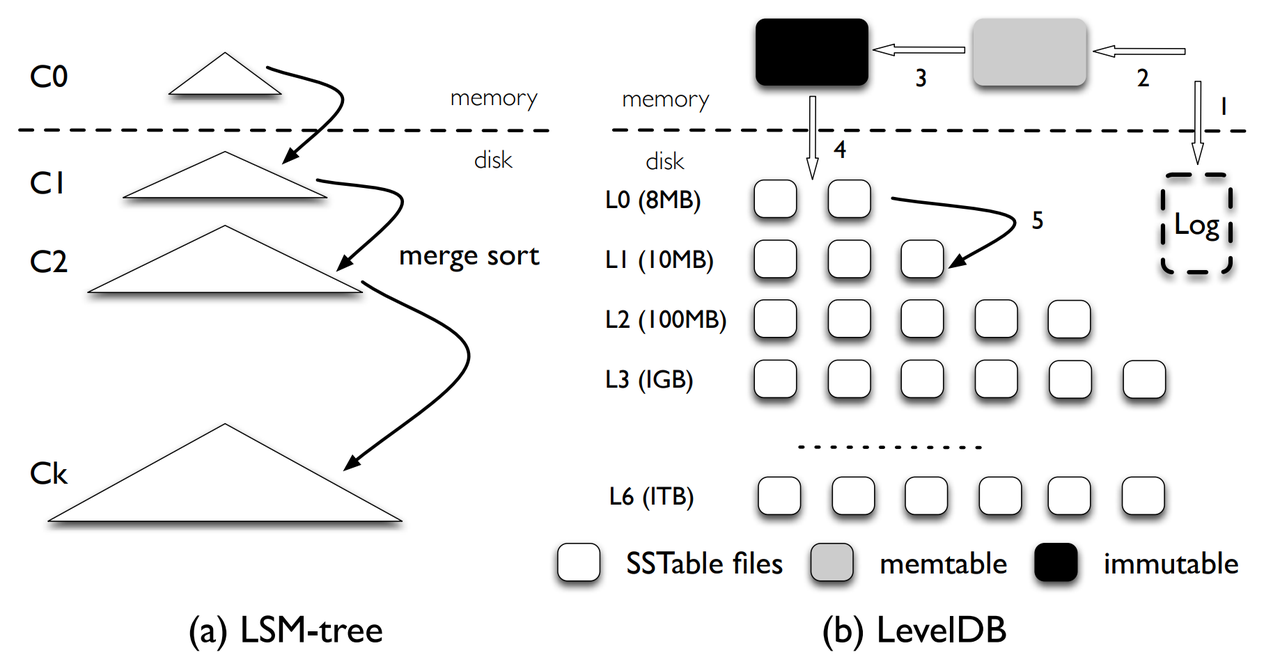
LevelDB 的工作流程如下:
- 写入时:
- 和SSTable一样,先写WAL,然后更新到内存(memtable)
- 当memtable达到一定大小时,将其置为不可修改(immutable),新起一个memtable用以新的写入,然后有个后台线程将immutable 写入到 L0层 的文件中;显然L0中的各个文件中是可能存在重复的键的;
- 当L0层的所有文件总和达到一定大小时,选择L0层的若干个文件 和 L1层的若干个文件 进行合并,合并时会保证L1层的 从左到右的文件都是有序的、不存在重复键的。如果L1也达到阈值,重复以上动作。
- 读取时:读取顺序为 memtable -> immutable -> L0 -> L1 -> L2 …
Level DB 使用的压缩方式为分层压缩(leveled compaction),除了L0,其下每一层都会保证 键只会有一个,同一层内不会出现冗余键,这减少了 空间放大以及读放大;但是写时遇到worst-case 可能会比较糟糕,比如上图中L2的第二个文件内容为 10-100000,那合并L3时,可能会涉及L3层的全部数据。
相对于leveled compaction,还有一种合并方式是 大小分级(Size-tired compaction),和分层压缩不同的是, 大小分级 并不需要保证 每一层的键只会有一个,压缩的时候,只需简单选择本层的若干个进行合并即可:
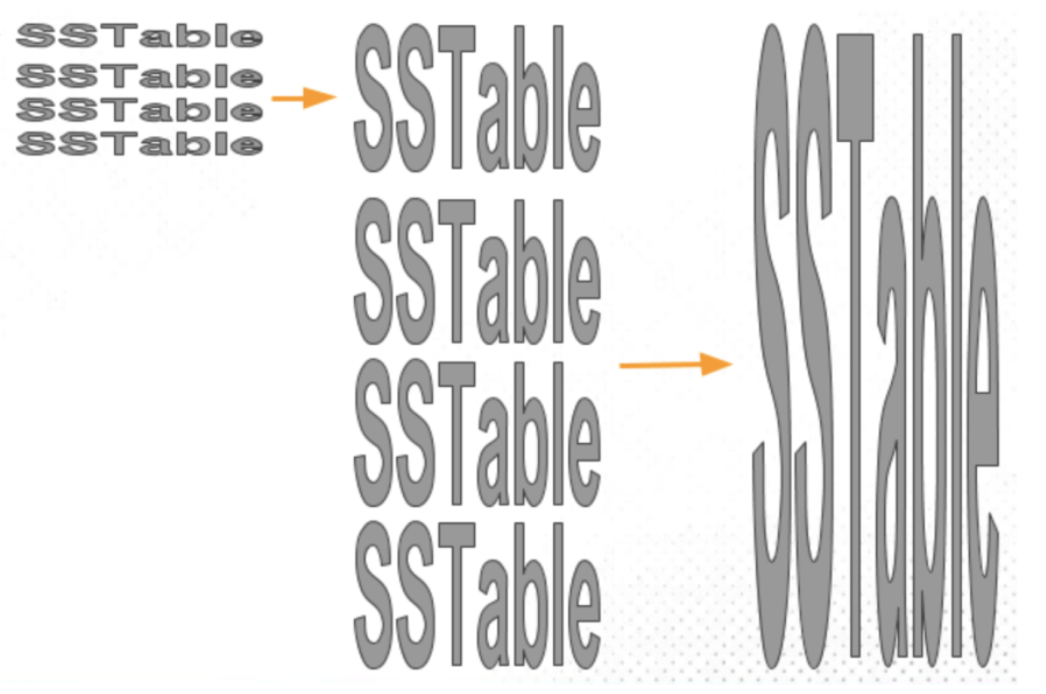
大小分级 在压缩过程时的写比较稳定的,不会出现严重的wrost-case的问题,但是每一层都可能会有冗余的情况,导致空间放大;同时因为每一层没有全局的有序,读时可能需要扫描多个文件才能确定哪个记录最新,从而导致读放大。具体参考:深入探讨LSM Compaction机制