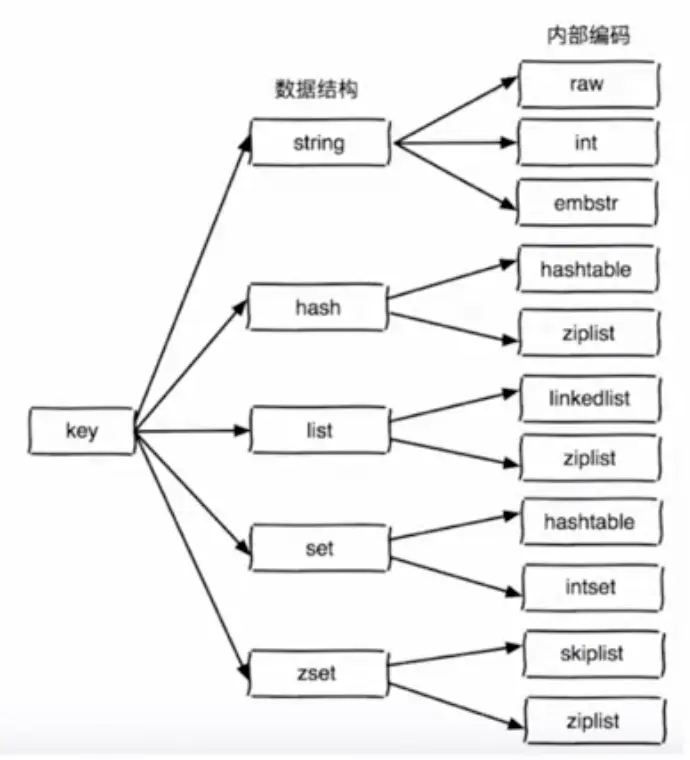
Redis 有 5 种基础数据结构,分别为 string 字符串,list 列表,set 集合,hash 哈希,zset 有序集合。 Redis 里面的每一种数据结构不止有一种底层实现,在不同的场景下Redis 会使用不同的底层实现,例如 zset,在元素个数不超过 64 时采用压缩列表实现,否则采用跳表+哈希表实现。
string 字符串
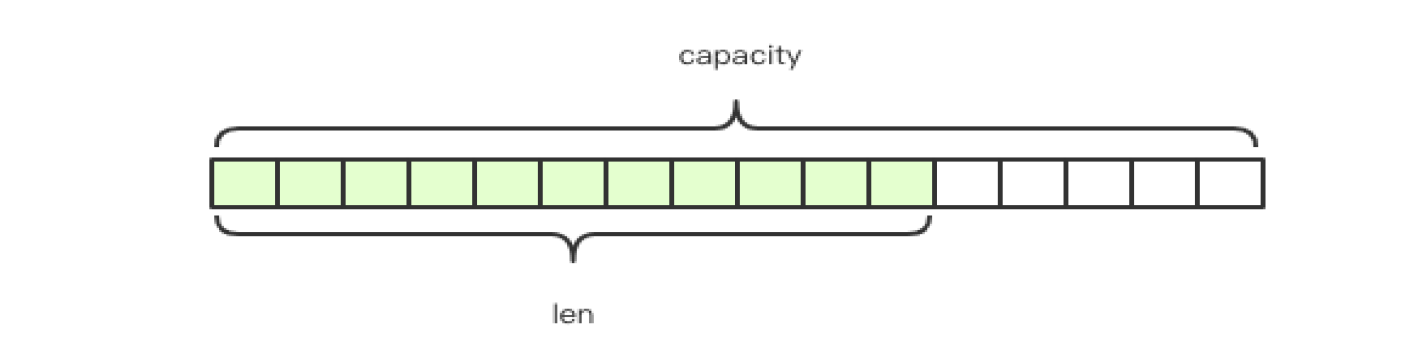
Redis 字符串是简单动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如下图所示,内部为当前字符串实际分配的空间 capacity 一般要高于实际字符串长度 len。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是字符串最大长度为 512 M。
键值对的键是一个字符串对象,值可能是一个字符串对象。Redis 所有的数据结构都是以唯一的 key 字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。不同类型的数据结构的差异就在于 value 的结构不一样。
List 列表
在版本 3.2 之前,Redis 列表数据结构的底层实现是 ziplist 和 linkedlist,当一个列表只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么 Redis 就会使用压缩列表来做列表的底层实现。当列表对象中元素的长度比较大或者数量比较多的时候,则会转而使用双向列表 linkedlist 来存储。
- list-max-ziplist-entries 512 # list 的元素个数超过 512 就必须使用双向列表 linkedlist 来存储
- list-max-ziplist-value 64 # list 的任意元素的长度超过 64 字节就必须使用双向列表 linkedlist 来存储
在版本 3.2 之后,引入了一个 quicklist 的数据结构,列表的底层都由 quicklist 实现。在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。当数据量比较多的时候才会改成快速链表(quicklist)。Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。

两种存储方式的优缺点:
- 双向链表 linkedlist 便于在列表的两端进行 push 和 pop 操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
- ziplist 存储在一段连续的内存上,所以存储效率很高。但是修改操作、插入和删除操作需要频繁的申请和释放内存。特别是当 ziplist 长度很长的时候,一次 realloc 可能会导致大批量的数据拷贝。
hash字典
Hash 对象的实现方式有两种,分别是 ziplist、hashtable, 其中 hashtable 的存储方式 key 是 String 类型的,value 也是以(key,value)的形式进行存储。
当一个哈希键只包含少量键值对,并且每个键值对的键和值要么是小整数值,要么是长度比较短的字符串,那么 Redis 就会使用压缩列表来做哈希键的底层实现。
- hash-max-zipmap-entries 512 # hash 的元素个数超过 512 就必须用标准结构存储
- hash-max-zipmap-value 64 # hash 的任意元素的 key/value 的长度超过 64 就必须用标准结构存储
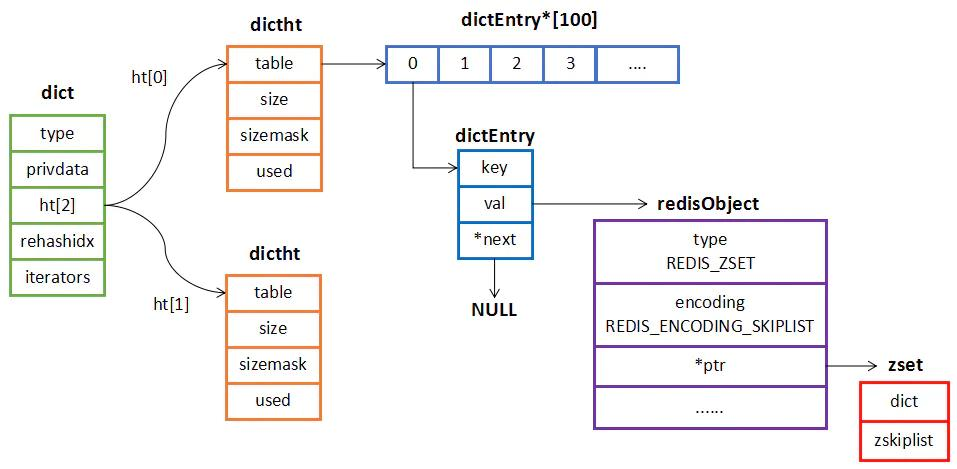
hashtable 是无序字典。内部实现结构是数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
 Redis 的字典的 rehash 是个耗时的操作,Redis 为了高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
Redis 的字典的 rehash 是个耗时的操作,Redis 为了高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
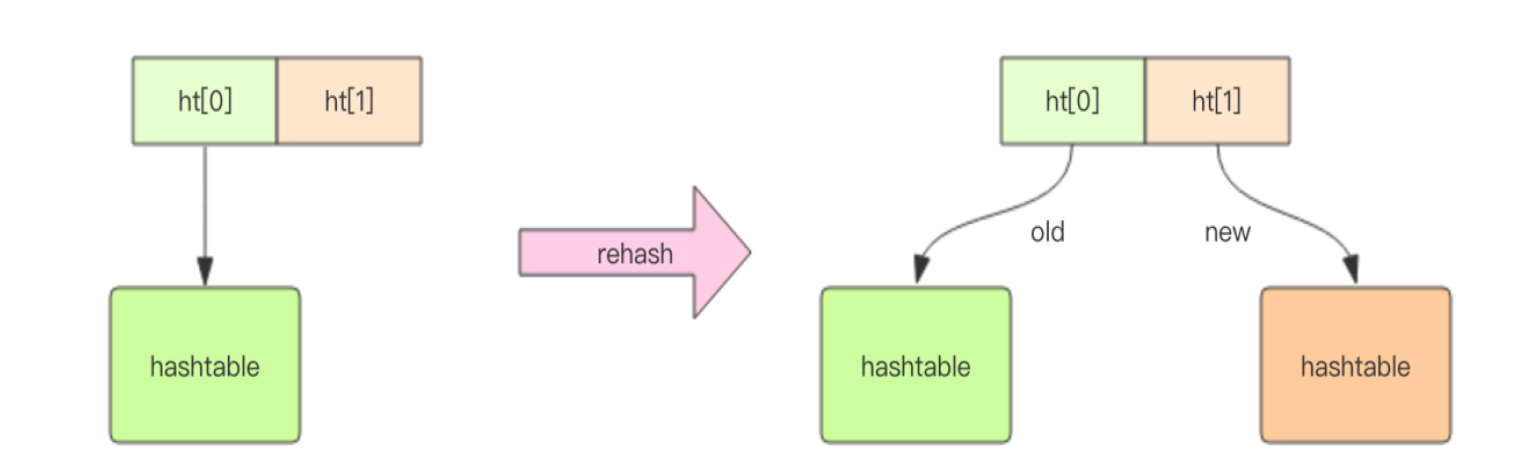
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务中以及 hash 的指令中,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中。
set 集合
集合数据类型用来存储一组不重复的数据。其实现方法有两种,一种是有序数组,另一种是字典。
- set-max-intset-entries 512 # set 的整数元素个数超过 512 就必须用默认结构字典存储。
Redis的集合的实现相当于一个特殊的字典,字典中所有的value都是一个值NULL。
zset有序集合
有序集合的底层数据结构分两种:ziplist 或者 skiplist,当避开下面两个条件限制时,有序集合对象使用 ziplist 这种结构,其余应使用 标准结构 skiplist 存储 (Redis 默认配置,可更改):
- zset-max-ziplist-entries 128 # zset 的元素个数超过 128 就必须用标准结构存储
- zset-max-ziplist-value 64 # zset 的任意元素的长度超过 64 就必须用标准结构存储
zset 标准存储使用了两个数据结构,第一个是 hash,第二个是 跳跃列表,hash 的作用就是关联元素 value 和权重 score,保障元素 value 的唯一性,可以通过元素 value 找到相应的 score 值。跳跃列表的目的在于按照 score 给元素 value 排序,根据 score 的范围获取元素 value 列表,以支持快速地按照得分值、得分区间获取数据。
1
2
3
4
5
// from redis.h/zset
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;