字典是 Redis 服务器中出现最为频繁的复合型数据结构。除了 hash 数据结构会用到字典外,整个 Redis 数据库的所有 key 和 value 也组成了一个全局字典,还有带过期时间的 key 集合也是一个字典。 zset 集合中存储 value 和 score 值的映射关系也是通过 dict 结构实现的。Redis 里面 set 的结构底层实现也是字典,只不过所有的 value 都是 NULL,其它的特性和字典一模一样
1
2
3
4
5
6
7
8
9
10
11
struct redisServer{
...
redisDb *db; // 保存 db 的数组
int dbnum; // db 的数量
...
}
struct RedisDb {
dict * dict; // all keys key => value
dict * expires; // all expired keys key => long(timestamp)
}
Redis 的 server 包含若干个(默认16个) redisDb 数据库,客户端连接时默认连接数据库 0,可通过select命令切换到其他数据库。Redis 集群模式下只有 db0,不支持多 db,
1
2
3
4
struct zset {
dict * dict; // all values value => score
zskiplist * zsl;
}
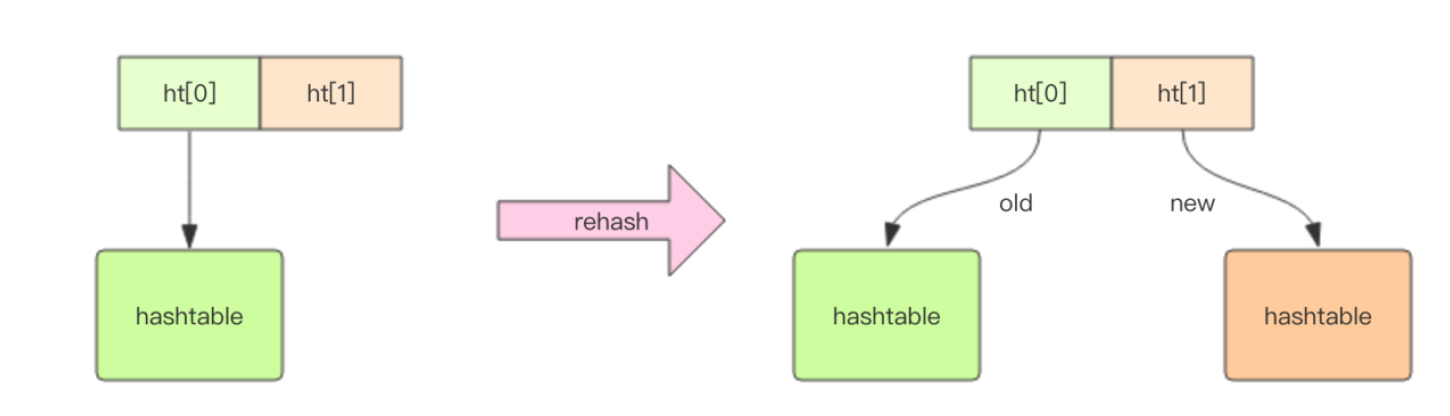
dict 结构内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的。但是在 dict 扩容缩容时,需要分配新的 hashtable,然后进行渐进式搬迁,这时候两个 hashtable 存储的分别是旧的 hashtable 和新的 hashtable。待搬迁结束后,旧的 hashtable 被删除,新的 hashtable 取而代之。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 字典
struct dict {
...
dictht ht[2];
int rehashidx; //当rehash 不在进行时,值为-1
}
// 哈希表
struct dictht {
dictEntry ** table; // 二维
long size; // 第一维数组的长度
long used; // hash 表中的元素个数
...
}
// 键值对
struct dictEntry {
void * key;
void * val;
dictEntry * next; // 链接下一个 entry
}
字典数据结构的精华在 hashtable 结构上。hashtable 通过分桶的方式解决 hash 冲突。第一维是数组,第二维是链表。数组中存储的是第二维链表的第一个元素的指针。
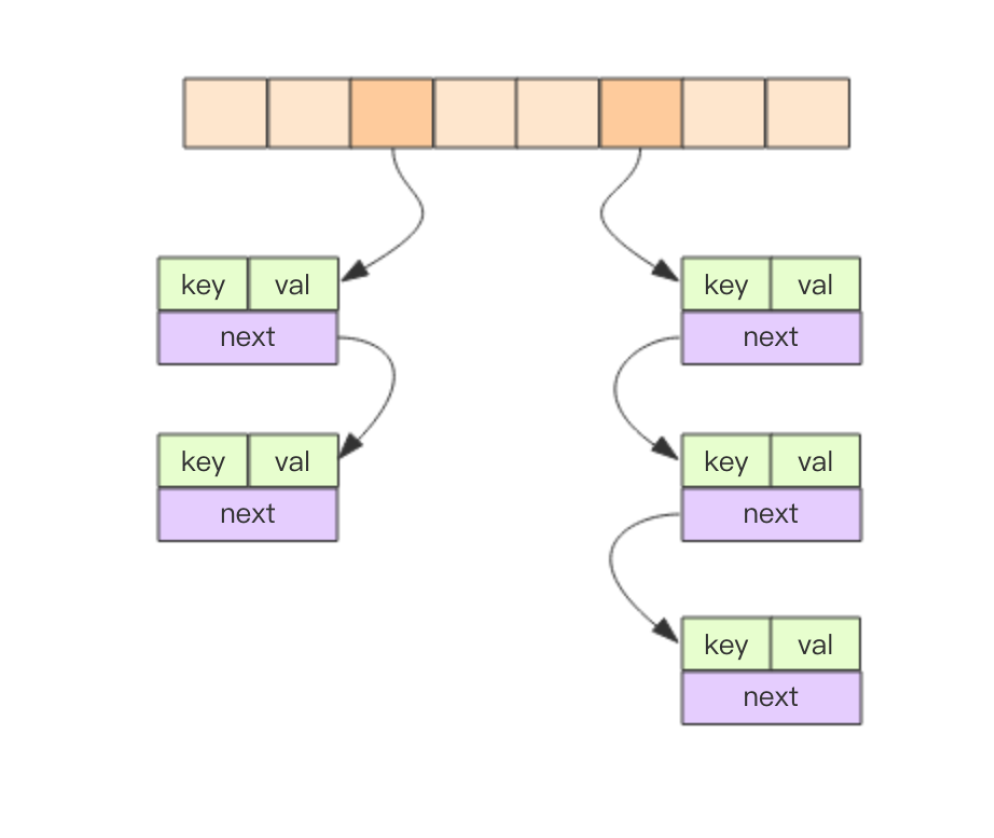
hash 函数
hashtable 的性能好不好完全取决于 hash 函数的质量。hash 函数如果可以将 key 打散的比较均匀,那么这个 hash 函数就是个好函数。Redis 的字典默认的 hash 函数是 siphash。siphash 算法即使在输入 key 很小的情况下,也可以产生随机性特别好的输出,而且它的性能也非常突出。对于 Redis 这样的单线程来说,字典数据结构如此普遍,字典操作也会非常频繁,hash 函数自然也是越快越好。
如果 hash 函数存在偏向性,黑客就可能利用这种偏向性对服务器进行攻击。存在偏向性的 hash 函数在特定模式下的输入会导致 hash 第二维链表长度极为不均匀,甚至所有的元素都集中到个别链表中,直接导致查找效率急剧下降,从O(1)退化到O(n)。有限的服务器计算能力将会被 hashtable 的查找效率彻底拖垮。这就是所谓 hash 攻击。
扩容与缩容
为了让哈希表的负载因子维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。
正常情况下,当 hash 表中 元素的个数 等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的 2 倍。不过如果 Redis 正在做 bgsave,为了减少内存页的过多分离 (Copy On Write),Redis 尽量不去扩容 (dict_can_resize),但是如果 hash 表已经非常满了,元素的个数已经达到了第一维数组长度的 5 倍 (dict_force_resize_ratio),说明 hash 表已经过于拥挤了,这个时候就会强制扩容。
当 hash 表因为元素的逐渐删除变得越来越稀疏时,Redis 会对 hash 表进行缩容来减少 hash 表的第一维数组空间占用。缩容的条件是元素个数低于数组长度的 10%。缩容不会考虑 Redis 是否正在做 bgsave。
- 服务器目前没有在执行 BGSAVE 或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于1,执行扩容
- 服务器目前正在执行 BGSAVE 或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于5,执行扩容
- 当哈希表的负载因子小于 0.1 时,执行收缩操作.
Redis Bgsave 命令用于在后台异步保存当前数据库的数据到磁盘。在执行 Bgsave 命令或 BGREWRITEAOF 命令的过程中,Redis 需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内存写入操作,最大限度地节约内存。
渐进式 rehash
扩展或收缩哈希表需要将ht[0]里面的所有键值对 rehash 到 ht[1]里面,但是,这个 rehash 动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
渐进式 rehash 的好处在于它采用分而治之的方式,将 rehash 流程所需要的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式 rehash 而带来的庞大计算量。搬迁操作在:
- 在当前字典的后续指令中(hset/hdel/hget/指令)
- Redis 还会在定时任务中对字典进行主动搬迁
哈希表渐进式 rehash 的详细步骤:
- 为
ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx,并将它的值设置为0,表示 rehash 工作正式开始。 - 在 rehash 进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对rehash 到ht[1],当 rehash 工作完成之后,程序将rehashidx属性的值增一。 - 随着字典操作的不断执行,最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash 操作已完成。
在进行渐进式 rehash 的过程中,字典会同时使用
ht[0]和ht[1]两个哈希表,所以在渐进式 rehash 进行期间,字典的删除、查找、更新等操作会在两个哈希表上进行。在进行渐进式 rehash 的过程中,新添加到字典的键值对一律会被保存到ht[1]里面,ht[0]则不再进行任何添加操作。