早期的 Redis 多组 Master-Slave 之间 是没有交互的(相对独立),而故障检测和转移的动作则由哨兵(Sentinel)集群 完成,架构如下图:
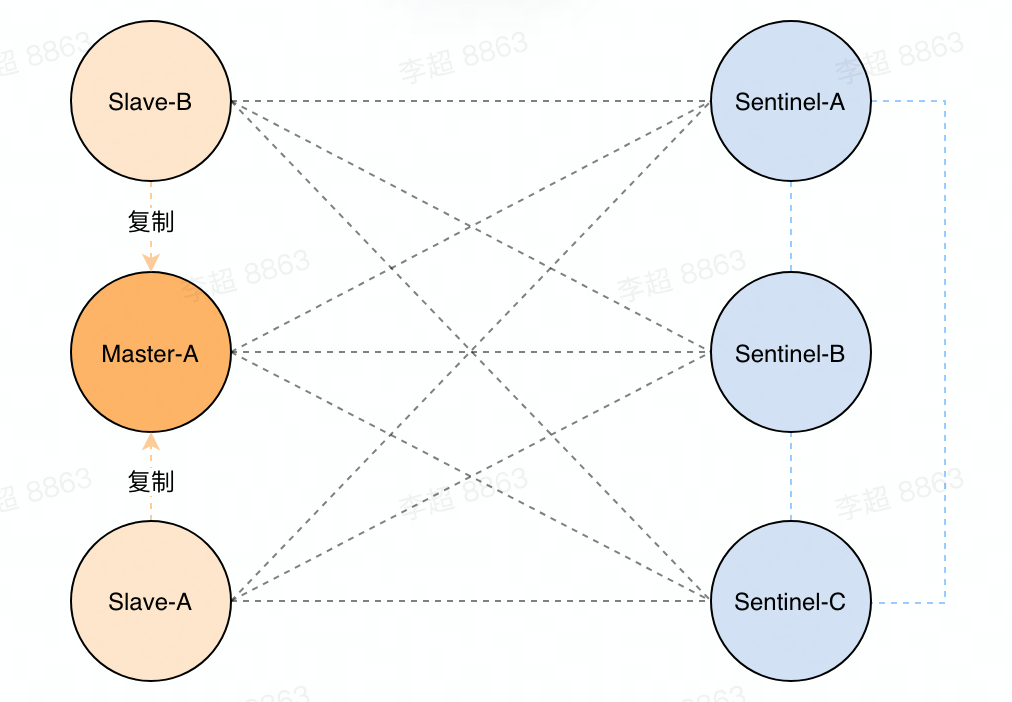
- 可将 Redis Sentinel 集群看成一个 ZooKeeper 集群,它是集群高可用的心脏,它一般是由 3~5 个节点组成。这样挂了个别节点后,集群还可以正常运转。
- 它负责持续监控主从节点的健康,当主节点挂掉时,自动选择一个最优的从节点切换为主节点。客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,然后再去连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 sentinel 要地址,sentinel 会将最新的主节点地址告诉客户端。如此应用程序将无需重启即可自动完成节点切换。
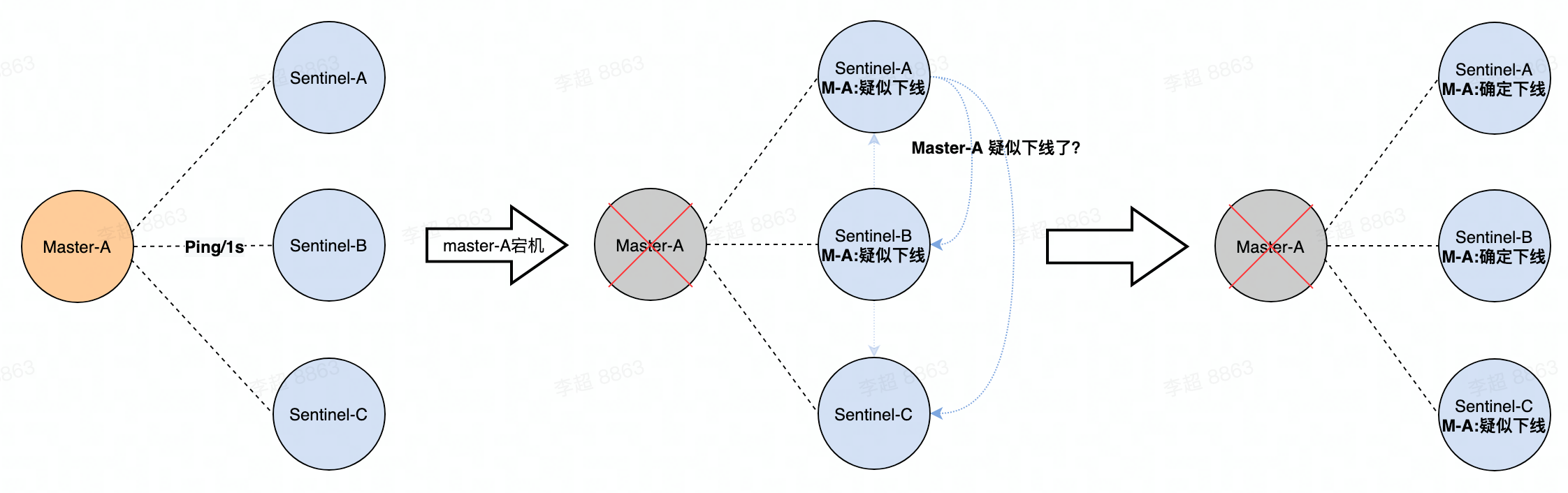
故障检测
- 哨兵会每间隔1秒会Ping一下Master,如果某个Master超过一定时间(down-after-milliseconds) 都没响应的话,哨兵会将这个 Master 标记为 疑似下线(主观下线);比如哨兵A标记Master-A为 疑似下线;
- 标记后,哨兵A会询问 其他哨兵,看它们 是不是也 确定 这个Master疑似下线了。当超过 N 个哨兵 都响应说这个Master 疑似下线了,此时哨兵A 将Master-A 标记为 确定下线(客观下线);
- 标记为 确定下线 后,说明这个Master真的翻车了(不是说 就 我和这个Master 连不上而已,是很多哨兵都连不上),此时触发故障转移;
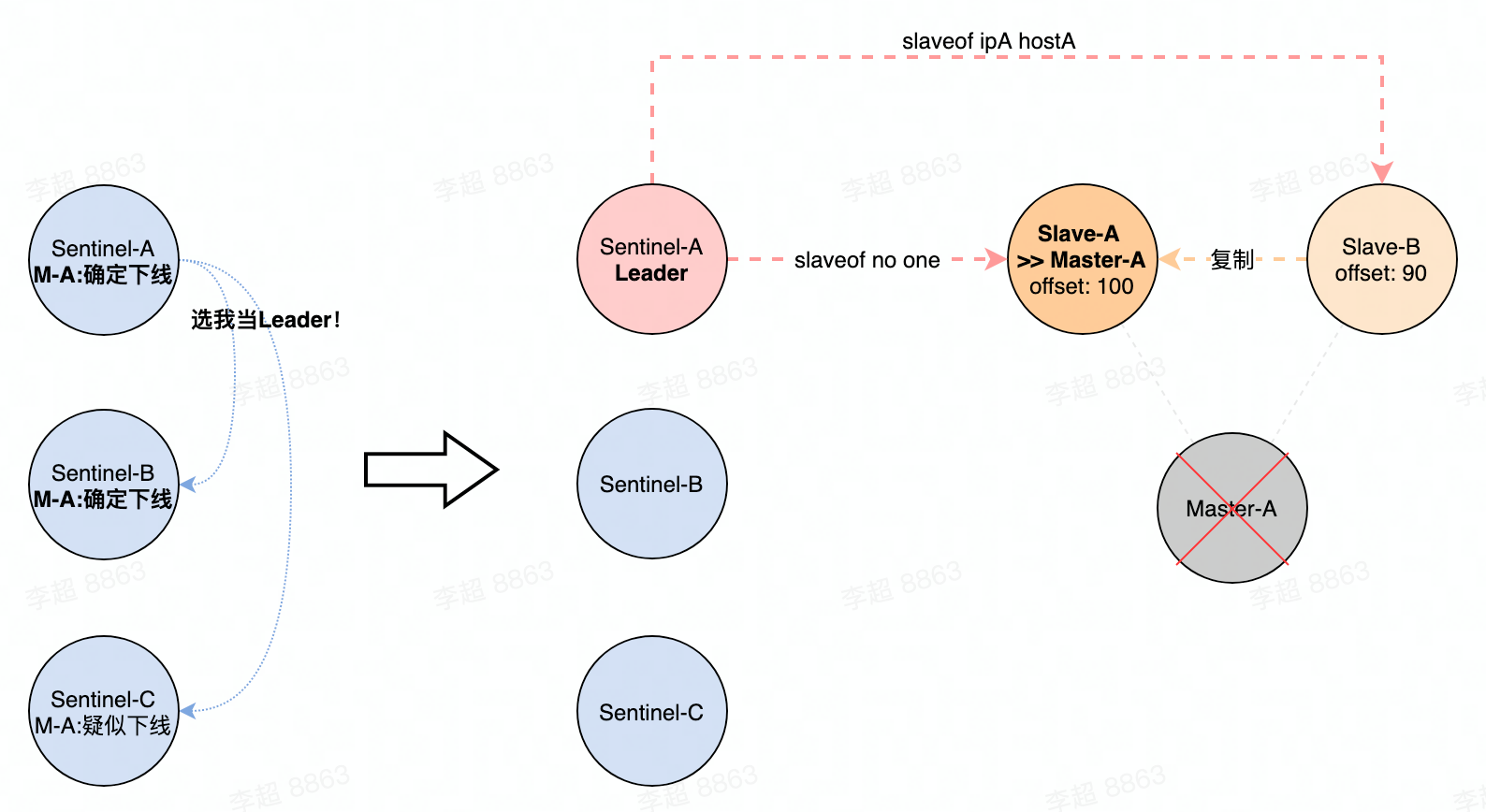
故障转移
故障转移最主要的目标 就是找出一个 从节点 升级为 主节点(发送slaveof no one命令),但是由哪个哨兵去执行这些动作呢?Redis的策略是通过 类Raft算法 在哨兵集群中选出一个Leader 进行操作:
- 当哨兵A 标记 Master-A为确定下线后,会向其他哨兵 发送 一个投票请求,要求别的哨兵投票给自己;每个哨兵 只能 有一票;比如 哨兵C投给了哨兵A,就不能投给哨兵B了
- 哨兵A 带上 投给自己那票,已经有2票了,超过了一半,确定自己成为哨兵的Leader;
- 哨兵A 执行后续的 转移动作:
- 从Slaves中挑选一个,将其升级为新的Master(slaveof no one)
- 其他Slave 改为复制新的Master(slaveof newIP newPort)
- 向 [+switch-master] 频道 发送 主节点切换的消息,客户端发现后,更新路由。
一些细节:如果A/B/C同时发起投票,然后这一轮大家都投自己了,没有过半的投票怎么办?根据Raft的套路,这三个节点会等待随机N毫秒,再发起新的一轮投票:比如A等100毫秒,B/C等200毫秒,A最先发起新一轮投票,此时B/C会直接投给A了(因为还没来得及投给自己) 因为哨兵本身是无状态的,所以选谁都一样。
消息丢失
Redis 主从采用异步复制,意味着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息就丢失了。如果主从延迟特别大,那么丢失的数据就可能会特别多。Sentinel 无法保证消息完全不丢失,但是也尽可能保证消息少丢失。它有两个选项可以限制主从延迟过大。
min-slaves-to-write 1
min-slaves-max-lag 10
第一个参数表示主节点必须至少有一个从节点在进行正常复制,否则就停止对外写服务,丧失可用性。 何为正常复制,何为异常复制?这个就是由第二个参数控制的,它的单位是秒,表示如果 10s 没有收到从节点的反馈,就意味着从节点同步不正常,要么网络断开了,要么一直没有给反馈。