压缩列表(ziplist)是列表(List)和散列(Hash)、有序集合(zset)的底层实现之一。
概述
压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
数据结构
1
2
3
4
5
6
7
struct ziplist<T> {
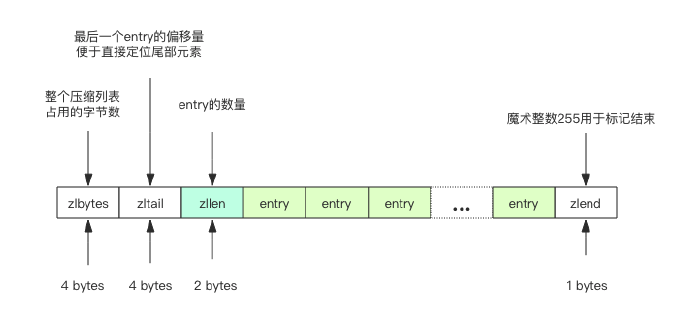
int32 zlbytes; // 整个压缩列表占用内存字节数
int32 zltail; // 压缩列表表尾节点距离压缩列表起始位置有多少字节,用于快速定位到最后一个节点
int16 zllength; // 节点个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
压缩列表为了支持双向遍历,所以才会有 ztail 这个字段,用来快速定位到最后一个元素,然后倒着遍历。实体 entry 块随着容纳的元素类型不同,也会有不一样的结构。
1
2
3
4
5
struct entry {
int<var> prevlen; // 前一个 entry 的字节长度
int<var> encoding; // 元素类型编码
optional byte[] content; // 元素内容
}
- prevlen 字段表示前一个 entry 的字节长度,当压缩列表倒着遍历时,需要通过这个字段来快速定位到下一个元素的位置。它是一个变长的整数,当字符串长度小于
254(0xFE)时,使用一个字节表示;如果达到或超出254(0xFE)那就使用 5 个字节来表示。第一个字节是0xFE(254),剩余四个字节表示字符串长度。可能会觉得用 5 个字节来表示字符串长度,是不是太浪费了。我们可以算一下,当字符串长度比较长的时候,其实 5 个字节也只占用了不到(5/(254+5))<2%的空间。 - encoding 字段存储了元素内容的编码类型,ziplist 通过这个字段来决定后面的 content 内容的形式
- content 字段在结构体中定义为 optional 类型,表示这个字段是可选的,对于很小的整数而言,它的内容已经内联到 encoding 字段的尾部了。
Redis 为了节约存储空间,对 encoding 字段进行了相当复杂的设计。Redis 通过这个字段的前缀位来识别具体存储的数据形式。下面我们来看看 Redis 是如何根据 encoding 的前缀位来区分内容的:
- 00xxxxxx 最大长度位 63 的短字符串,后面的 6 个位存储字符串的位数,剩余的字节就是字符串的内容。
- 01xxxxxx xxxxxxxx 中等长度的字符串,后面 14 个位来表示字符串的长度,剩余的字节就是字符串的内容。
- 10000000 aaaaaaaa bbbbbbbb cccccccc dddddddd 特大字符串,需要使用额外 4 个字节来表示长度。第一个字节前缀是10,剩余 6 位没有使用,统一置为零。后面跟着字符串内容。不过这样的大字符串是没有机会使用的,压缩列表通常只是用来存储小数据的。
- 11000000 表示 int16,后跟两个字节表示整数。
- 11010000 表示 int32,后跟四个字节表示整数。
- 11100000 表示 int64,后跟八个字节表示整数。
- 11110000 表示 int24,后跟三个字节表示整数。
- 11111110 表示 int8,后跟一个字节表示整数。
- 11111111 表示 ziplist 的结束,也就是 zlend 的值 0xFF。
- 1111xxxx 表示极小整数,xxxx 的范围只能是 (0001~1101), 也就是1~13,因为0000、1110、1111都被占用了。读取到的 value 需要将 xxxx 减 1,也就是整数0~12就是最终的 value。
增加元素
ziplist 都是紧凑存储,没有冗余空间 (对比一下 Redis 的字符串结构)。意味着插入一个新的元素就需要调用 realloc 扩展内存。取决于内存分配器算法和当前的 ziplist 内存大小,realloc 可能会重新分配新的内存空间,并将之前的内容一次性拷贝到新的地址,也可能在原有的地址上进行扩展,这时就不需要进行旧内容的内存拷贝。
如果 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。所以 ziplist 不适合存储大型字符串,存储的元素也不宜过多。
级联更新问题
前面提到每个 entry 都会有一个 prevlen 字段存储前一个 entry 的长度。如果内容小于 254 字节,prevlen 用 1 字节存储,否则就是 5 字节。这意味着如果某个 entry 经过了修改操作从 253 字节变成了 254 字节,那么它的下一个 entry 的 prevlen 字段就要更新,从 1 个字节扩展到 5 个字节;如果这个 entry 的长度本来也是 253 字节,那么后面 entry 的 prevlen 字段还得继续更新。
如果 ziplist 里面每个 entry 恰好都存储了 253 字节的内容,那么第一个 entry 内容的修改就会导致后续所有 entry 的级联更新,这就是一个比较耗费计算资源的操作。